 大家电
大家电  厨卫家电
厨卫家电  生活电器
生活电器  健康电器
健康电器  数码产品
数码产品  五金电器
五金电器  生活用品
生活用品  好物推荐
好物推荐  网站首页
网站首页Intel桌面独显Arc深入测试
认证:电脑配件优质原创作者
本文有5777个文字,大小约为24KB,预计阅读时间15分钟
精选评测好文
本文由我和 CloudLiu cloudliu的个人主页| 值得买 (smzdm.com) 联合创作。
从炼金术士到德鲁伊——Intel 回归桌面独显的首部曲
在上个世纪 90 年代初。Intel 内部正面临 RISC 和 CISC 方向的巨大争议中。争论的结果之一就是名为 i860 的 RISC 处理器高调亮相。作为 Intel 第一枚 RISC 高性能处理器。 i860 集成了在当时还非常罕见的 3D 图形处理单元。
 底下中央位置的那枚长条白色芯片就是 Intel 的 82720。打上了 NEC 的名字
底下中央位置的那枚长条白色芯片就是 Intel 的 82720。打上了 NEC 的名字
Intel 在 80 年代推出过给 NEC µPD7220 用的 82720 图形控制器以及若干独立卡厂商用的 82786。但是这两枚芯片只具备非常基本的显示输出或者文本加速能力。
相比之下。i860
显卡
具备一个 64 位整数 3D 图形单元。这个 3D 图形单元与浮点单元共享寄存器。可以每秒完成 50 万次 4*4 3D 矩阵变换计算。与当时一些独立 3D 图形处理板性能相当。从现在的角度来看。这个 3D 图形单元基本上可以视作后来 Pentium MMX 的先驱。 SGI RealityEngine 采用了 Intel i860 作为几何加速处理器
SGI RealityEngine 采用了 Intel i860 作为几何加速处理器
尽管 i860 在 SGI RealityEngine 等重要产品中获得应用。然而它并未如它的内部竞争对手 x86 那样获得长足的发展。特别是其他通用处理器也引入了图形扩展后。i860 的优势不再显著。到了 90 年代末 Intel 将这个自己一手打造的 RISC 架构产品线砍掉。取而代之的是基于第三方 RISC 指令集 ARM 的自研架构 Xscale。
虽然 i860 嘎然而止。但是 Intel 透过 i860 初步获得了业界对其图形处理的认可。开始涉足图形工作站和工业图形市场。其成果就是 1998 年推出的 i740(代号 Auburn)。i740 虽说是 Intel 生产。但是它有浓厚的 Real3D(洛克希德马丁公司的图形部门)背景。因为代号 Auburn就是 Real3D 和 Intel 一年前以 4.3 亿美元收购的 Chips and Technologies 合作项目。该项目将 CT 的 2D 技术和 Real3D 的 3D 技术进行整合。形成 i740。到后来 Intel 还索性再收购了 Real3D 20% 的股权。

从商业角度来看的话。几乎所有第三方显卡都是都推出过 i740 显卡。虽然速度离同期第一名还有一定差距。但是它具备比较稳定的渲染品质以及较低的价格。还是获得了不少用户的选择。
如果放到整个显卡市场来看的话。i740 的份额并耀眼:在1997 年 到 1998 年。Intel 一共卖出了 400 万片 i740。市场份额只有 4%。究其原因是它的性能无法和当时的竞争对手——NVIDIA、3dfx、相提并论。
在 Intel 看来。它的未来主要增长方向将会是笔记本、服务器领域。桌面的大头也是集团客户。这些客户希望在维护方面尽可能简单。独显是一个碎片化的东西。集成到芯片组中更符合 Intel 当时的发展态势。打从有了这个认知后。Intel 就决定只在芯片组后来是 CPU 中集成一个凑合够用的 GPU。
但是这只是影响 Intel 退出独显市场的一个因素而已。
除了产品策略的问题外。Intel 当时还面临来自美国联邦贸易委员会的不公平竞争诉讼。i740 的公开报价是 28 美元。但是在中国台湾的实际价格只有 7 到 18 美元。主板厂商也表示如果采购 i740 的话。可以更容易拿到 Pentium II 处理器(i740 采用的 AGP 总线是从 Pentium II 开始引入)。
到 1999 年底。英特尔做了两件事。关闭了 i740 项目。并从洛克希德马丁公司手中收购了 Real3D 的资产。
随着 Real3D 的崩溃。ATI 雇佣了许多剩余的员工并开设了奥兰多办事处。
当年 3dfx 将资产出售给 NVIDIA 之前曾经因为专利权被侵犯而起诉 Real3D。英特尔通过将所有 IP 出售给 3Dfx 解决了这个问题。3Dfx 最终落入了 NVIDIA 手中。NVIDIA 拥有 SGI 的图形开发资源。其中包括 Real3D 10% 的份额。这引发了一系列诉讼。ATI 也加入了进来。在 2001 年交叉许可和解之前。两家公司都参与了有关 Real3D 专利的诉讼。
尽管英特尔在 18 个月前才大张旗鼓地进入这个市场。但是此时英特尔已经作出了退出该市场的决定。除了法律原因外。最主要的原因其实是独显业务的贡献对英特尔来说比较一般。这个业务销售相对 NVIDIA 这样的竞争对手来说还是比较惨淡的。Intel 仍然在生产将标准 PC 芯片组与图形处理器结合在一起的集显芯片组。但这些产品的目标是售价在 1,000 美元或以下的计算机。与游戏玩家渐行渐远。
直到 2018 年。形势的发展让 Intel 有了不一样的看法。
如果将视线拉到更远的 2008 年 8 月的 SIGGRAPH 图形峰会。大家一定会记得 Intel 在这次大会上公布了代号 Larrabee 的项目。这个项目的目标是推出一个包含数十个经过美国国防部除错的 P55C 内核处理器。试图用纯 x86 通用计算内核替代 GPU。
 收购了 3D Labs 团队后 信奉 x86 就是锤子的 Intel 尝试推出基于 x86 的显卡
收购了 3D Labs 团队后 信奉 x86 就是锤子的 Intel 尝试推出基于 x86 的显卡
这个在现在看来依然非常疯狂的计划所处的背景是一年前或者说 2007 年 NVIDIA 推出了名为 CUDA 的 GPU 通用计算架构。CUDA 揉合了之前人们多年在 GPU 通用计算的研究成就。为了推动 CUDA。NVIDIA 发动了有史以来最大的开发者支持力度。
举个例子。在 Fermi 发布后。仅仅是在中国大陆区。NVIDIA 一位开发者关系经理能调拨给认证 CUDA 开发者免费使用的 GeForce GTX 480 就达数百片(400+)。当时 CUDA 开发者相比现在来说还是寥寥无几的阶段。这种支持力度相当于是无限量供应了。在院校支持方面。NVIDIA 与诸多院校合作开展 CUDA 开发培训以及应用研发。培训出了大量毕业后就已经掌握 CUDA 编程的毕业生。这些毕业生如今已经活跃于各个 GPU 通用计算领域。
Intel 此时已经感到大事不妙。
众人皆知半导体发展的摩尔定律早就不那么灵光了。内存墙、功率墙让 CPU 性能发展举步维艰。业界此时普遍的认知是未来的系统架构将会是异构计算的天下。
Intel 对此的应对方式是前面所提及的 Larrabee。然而 Larrabee 虽然强调基于 x86。在编程难度上要比 CUDA 简单。但是从实际的情况看。Larrabee 如果要发挥全部效能依然需要修改大量的代码。
基于 Larrabee 二代目(Knights Landing)的 Xeon Phi上市时间是 2013 年。此时距离 Larrabee 项目公布已经过去了 5 年。而 CUDA 这边已经有 6 年。业界在异构计算方面的资源已经完全向 CUDA 倾斜。加上 Intel 在 10 纳米制程上严重拖沓。Xeon Phi 当初宣称的一些优势已经不再明显。这使得 XeonPhi 并未如 Intel 预期的那样可以代替 GPU。
反而 CUDA 这边由于拥有庞大的 GPU 用户群体。显著摊薄了开发、使用成本。获得了大量不同应用的支持。发展势头一日千里。相较之下。Xeon Phi只有 HPC 用户。变成了一种小打小闹的产品。如今国内一些打着 GPGPU 旗号的初创公司也面临着同样的问题——只能服务极个别客户。难以做大。生态极其脆弱。
根据反映超级计算机性能排名的 TOP500 统计结果。在 2021 年有 38% 的算力源自 GPU。而这个比值在 6 年前只有 15%。
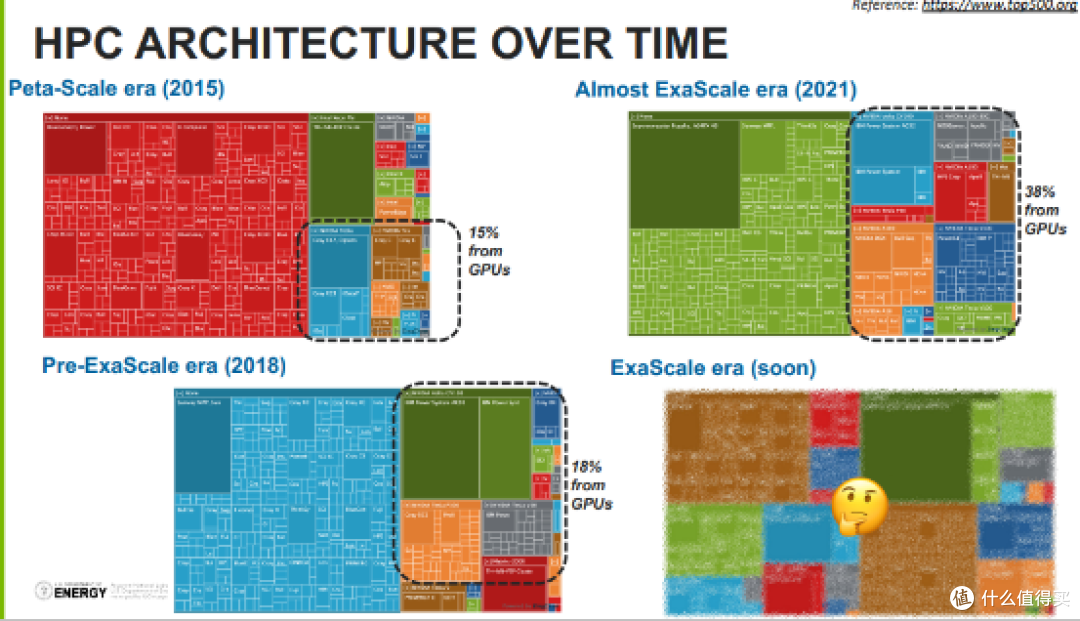
正是上述背景下。Intel 在 2018 年决定重启独显研发计划。项目的名称就是 Project Xe。随着该计划的启动。源自 LRB 的 XeonPhi 产品线于 2020 年被终止。

按照 Intel 原定的计划。第一款独立显卡(代号 DG1)应该在 2020 年推出。但是实际情况是有点雷声大雨点小。DG1 的问世几乎是悄无声息。原因是该卡的性能比较低。只提供给 OEM 市场。纯属试水产品。也不知道 OEM 们做这样的小白鼠是幸运还是倒霉。
 DG1。只适合作为收藏品
DG1。只适合作为收藏品
Intel 的 GPU 团队是由 2017 年从 AMD 跳槽过来的 Raja Koduri 领导。Raja Koduri 是印度裔移民。从履历上来看是有丰富的图形芯片行业经验:
1996 年加入 S3 Graphics;
2001 年成为 ATI 的先进技术研发总监;
2006 年 ATI 被 AMD 收购后。成为 AMD 首席图形技术官;
2009 年跳槽到苹果公司。让苹果电脑实现了视网膜高分辨率显示;
2013 年回巢 AMD 公司担任视觉计算副总裁;
2015 AMD 重组图形部门的时候 Raja Koduri 被任命为 RTG 的高级副总裁兼首席架构师。在此期间。AMD 推出的 Polaris、Vega、Navi 都与他有关。特别是现在 Navi 架构更是由他完全负责的。
比较有意思的是。Raja Koduri 在当年 Vega 发布后。展开了一个长达 3 个月的假期。推特也基本上不再提 AMD 的任何事情。RTG 的业务也都由 AMD CEO Lisa Su 接盘。坊间当时有各种猜测。例如 Vega 表现不佳。AMD 领导层不满 Raja 的表现等等。
同行当然是在等待 Intel 的笑话。如何回敬则是 Intel 和 Raja 团队必须面对的。
根据 Intel 2021 年架构日的介绍。Intel 将其独立显卡品牌命名为 Intel ARC。按照 Intel 的说法。Arc 这个名字源自故事弧(Story Arc。表示故事里的角色或者状态转换)的概念。一并公开的还有一份长远的路线图。给人的感觉就是游戏主角的转职路线图:

按照这份路线图。2022 年第一季度问世的游戏用户GPU 代号是 Alchemist(炼金术士)。之后将会是 Battlemage(魔法战士)、Celestial(天神)、Durid(德鲁伊)。如果取英文首字母的话。刚巧就是英文字母表的前四个字母 ABCD。需要指出的是。ARC 并非英特尔唯一的显卡品牌。它在 2013 年(Haswell 时代)的时候专门为其高端核显推出了 Iris 品牌。更早之前则是 Intel Extreme Graphis 和 Intel GMA(Nehalem 时代)这样的产品名称。
按照正常的发展规律。初代产品主要是练练手。因此今年 Alchemist 的现实目的并非与 NVIDIA 拉开架势全面开打。而是选择销量先决为主。Intel 将桌面最高端型号定位至 RTX 3070 也说明其虽有野心。但是也清楚自身实力是什么水平。
和 AMD、NVIDIA 在产品规划上经常出现的一股乱炖不同(现在好一些)的是。Intel 很清晰地将其 GPU 产品线划分为 Xe-LP、Xe-HPG 以及 Xe-HPC。之前还有一个被取消了的 Xe-HP。

Xe-LP:核显、低端独显(应用于 OEM 办公整机或者服务器板载亮机)。
Xe-HPG:高性能独显。
Xe-HPC:高性能计算中心加速器。

当初的 Xe-HP 构想是把 Xe-HPG 做成不同 Tile(现在的叫法是 Stack)组合的型号。但是如今已经取消。留下的产品空间现在被下级 Xe-HPG(云计算、AI 推理)和上级 Xe-HPC(高性能计算、AI 训练)分食。

上图是 Intel Xe-HP 团队所有成员合照。该团队位于印度班加罗尔。可以说 Xe HP 的咖喱味很浓。它的夭折某种程度上也是可以理解的。

今年 Intel 的 Xe-HPG Intel Arc 独显就是基于 Alchemist 微架构的 DG2 系列。桌面型号包括了 A310、A380、A580、A770 以及传说中的 A780 等。其中的首字母 A 表示它们属于 Alchemist。型号数字越大代表性能越高。
从现在开始。就让我们进入 Intel Arc 的架构。看看这个架构和 Intel 以往的 GPU 架构以及其他厂商的 GPU 架构有何不一样的地方。
为了简化内容。我想先把一些 Intel GPU 的名词予以解释。这样有助于大家了解后面的内容。
首先。Intel 今年更新了 GPU 相关的名词术语:


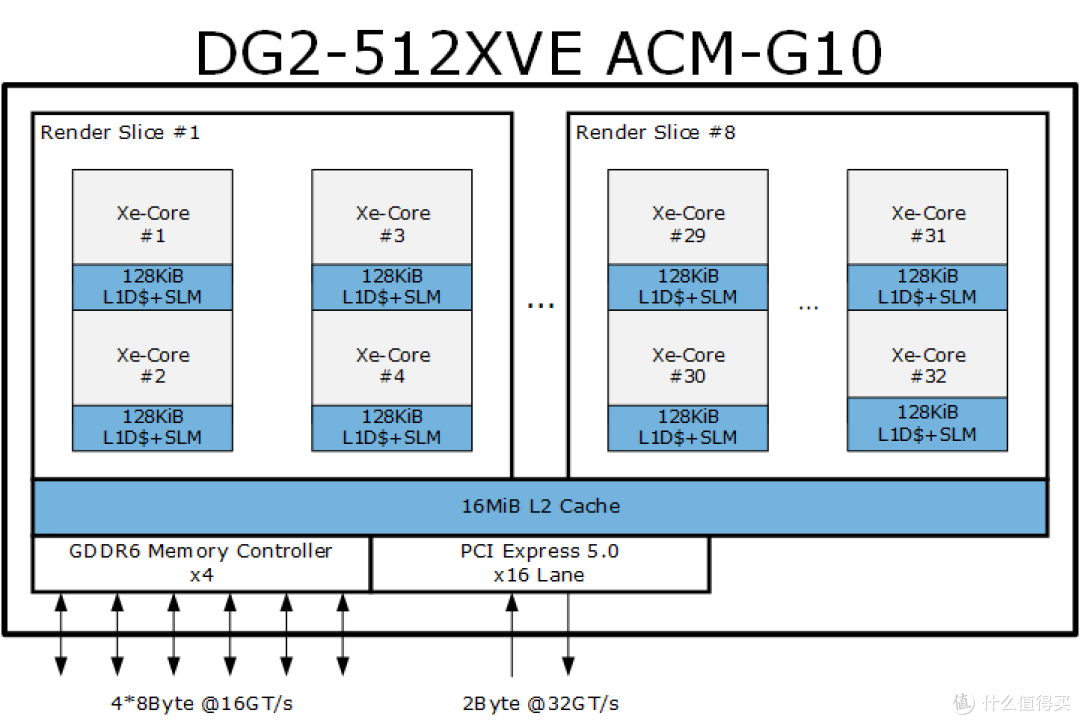
以大家比较熟悉的 NVIDIA GPU 名词术语为例。这里面的 XVE 相当于 NVIDIA CUDA 里的 SM SubCore。XMX 相当于 Tensor Core。XC 相当于 SM、SLC 相当于 GPC。STK 则相当于一枚可以堆叠的芯片。
XVE:XVE 或者说以前的 EU 是 Intel Xe GPU 架构里最小线程级单元。需要注意的是。XVE 虽然在概念上等同 EU。但是具体实现上有一定差别。
Xe-LP 的 EU 是一个 8 路 FP32、整数的 SIMD 单元。内部资源可以支持 7 条线程(NVIDIA CUDA 术语中相当于 Thread Block)。
在 Xe-HPG 里。每个 XVE 也有一个 8 路 FP32 FMA SIMD单元。而在 Xe-HPC 里。每个 XVE 是 16 个 FP32 FMA SIMD。都可以支持 8 个线程。
XC:Xe-Core 或者说以前的 DSS。相当于 NVIDIA CUDA 里的 SM 或者 AMD RDNA 里的 Dual Compute Unit。
每个 Xe-HPG 的 XC 内部有 16 个 8 路 FP32 XVE和 16 个 1024-bit XMX、一个指令高速缓存、一个本地线程分派器、一个 SLM(共享式局部内存)以及一个每周期 128 字节的数据端口。
理论上。Xe-HPG 的 XC 可以每个周期执行 512 个 FP16 或者 256 个 FP32(16 XVE * 8 FP32 FMA inst/XVE * 2ops/inst)操作。
每个 Xe-HPG XC 里的 SLM 容量为 192-KiB(Xe-HPC 是 512-KiB)。可以供 XVE 直接访问。它的一个重要作用是共享 XVE 中并发执行的 work-item(对应 CUDA 里的 CUDA Thread)涉及的原子操作数据和信号。相当于 CUDA 里的 shared memory(SMEM) 或者 RDNA 中的 LDS。
XC 内的每个 XMX 或者说矩阵引擎是 1024-bit。在 16 个 XMX 加持下每个 XC 每个周期可以跑 4096 个 int8 操作或者 2048 个 fp16/bf16 操作、又或者是 1024 个 fp32 操作。
每个 Xe-HPG XC 都有一条 512-字节 的内存通道。
相比之下。以前 Xe-LP 时代的 DSS 具备 16 个 EU。可以每个周期执行的 FP32 操作数虽然也是 256 个 FP32 操作(16 EU * 8 FP32 FMA inst/EU * 2ops/inst = 256)。但是它的内存总线只有 128 字节。
SLC:SLC 相当于 NVIDIA Ampere 里的 GPC。它能独立完成包括光栅操作在内的完整图形处理。可以视作一个小的 GPU。
在 Xe-HPG 里面。每个 SLC 具备 4 个 XC 或者说 512 个 PE(计算元)和 64 个 XMX。
和 NVIDIA、AMD 将光线追踪加速单元 RTCore 或者 RA 集成到 SM 或者 DCU 类似的是。Intel 将光线加速单元 RTU 和纹理单元等所有图形相关的固定功能单元也都放在了 XC 这一级里。每个 Xe-HPG SLC 有 4 个 RTU。
在面向高性能计算的 Xe-HPC 里。每个 SLC 包含 16 个 XC。RTU 数量相应的也增加到 16 个。相比之下 NVIDIA 的 A100、H100、AMD 的 MI200 等同级别 GPU 都是没有 RTCore 或者 RA 的。

在指令能力方面。Xe-HPG 不支持 DP4A 指令。而 Xe-HPC 提供了支持。此外 Xe-HPC 还提供了全速率的 FP64 支持。Xe-HPG 则是完全不支持 FP64。
Intel 并未说明 XMX 是否能和 XVE 着色器一起并行运作(NVIDIA 安培架构可以)。
说起 DP4A 和 XMX。绕不开的话题自然是 Intel 的 XeSS。
XeSS 是 Intel 的超分辨率技术。相当于 AMD 的 FSR 2.0 和 NVIDIA 的 DLSS 1.9+。
NVIDIA 的 DLSS 现在遍地开花。已经有接近 200 个游戏支持 DLSS 技术。它可以用较低的分辨率进行实际渲染。然后透过超级计算机训练出来的人工智能网络参数重构出分辨率更高的画面。做到了帧率、画质我都要的效果。
Intel 的 XeSS 技术基本上就是 DLSS 的翻版。所不同的是。作为后来者。Intel 提供了两个版本的 XeSS 供开发人员选择。
它们分别是采用 XMX 加速的 XeSS 高速版和 DP4A 加速的通用版 XeSS。
XMX 版 XeSS 只能在 Intel Arc Xe-HPG 系列 GPU 上运行。透过调用 XMX 单元实现 XeSS 加速运行。

而 DP4A 采用了 DP4A 指令来执行。由于 AMD Vega 20、Navi12、 Intel Xe 以及 NVIDIA GP102 等 GPU 都提供了 DP4A 指令硬件支持。因此 XeSS DP4A 版本都可以在它们上面运行。
其实 NVIDIA 在游戏 Control 上实现的 DLSS 1.9 就是采用了软件方式执行。虽然不清楚是否使用了 DP4A 指令。但是其速度和效果令人相当满意。之后 DLSS 1.9 引入了 Tensor Core 加速。成为了 DLSS 2.x。
如果你不清楚 DLSS 1.9 的话。我可以简单说一下。DLSS 1.9 和 DLSS 1.0 相比。引入了时间域采样。显著改善了画质。DLSS 1.9 就是 DLSS 2.0 的雏形。

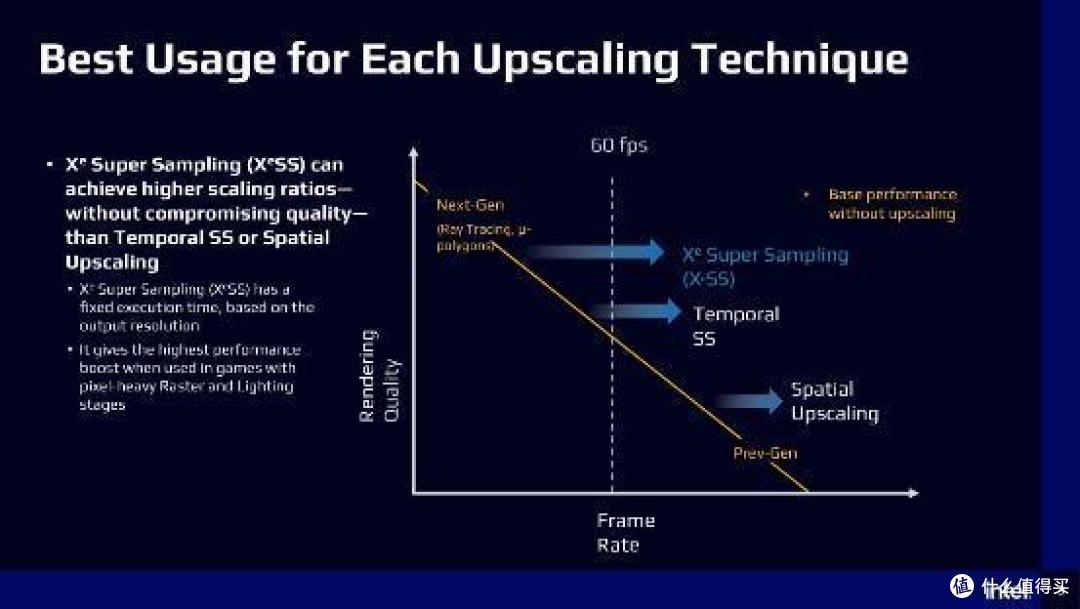

Intel XeSS 和 DLSS 高度相似。同样支持 AI 硬件加速、同样采用时间域采样、同样采用通用神经网络参数。实际的画质区别应该非常小。理论上是后者极具竞争力的对手。
在产品发布节奏上。Intel 在桌面产品方面选择了先行推出 DG2 的低阶版本 DG2-128 或者说 ACM11。这个 GPU 有两个 SLC。合计 8 个 XC 或者说 128 个 XVE。RTU 和 XMX 均为 8 个。手头这个 Intel ARC A380 则是该 GPU 里的最高阶型号。具备完整的 128 XVE。
更多的架构细节 Intel 并没有透露多少。接下来。让我们进行一些底层测试。
底层测试并不一定能反映 GPU 的实际应用表现。但是它们的测试结果可以反映出 GPU 一些特性。其中一些是 Intel 并没有告知的。由于 GPU 的特点。部分底层测试受驱动和测试软件影响颇大。但是它们当中的一些项目是比较难以透过驱动改善。
经常看到“新驱动 战未来”之类的说法。而底层测试也许可以一定程度上告知我们这个 GPU 战未来的可能性有多高。
首先来看看指令吞吐测试(测试软件为 Nemes 的 GPU Perf Tester 0.9):
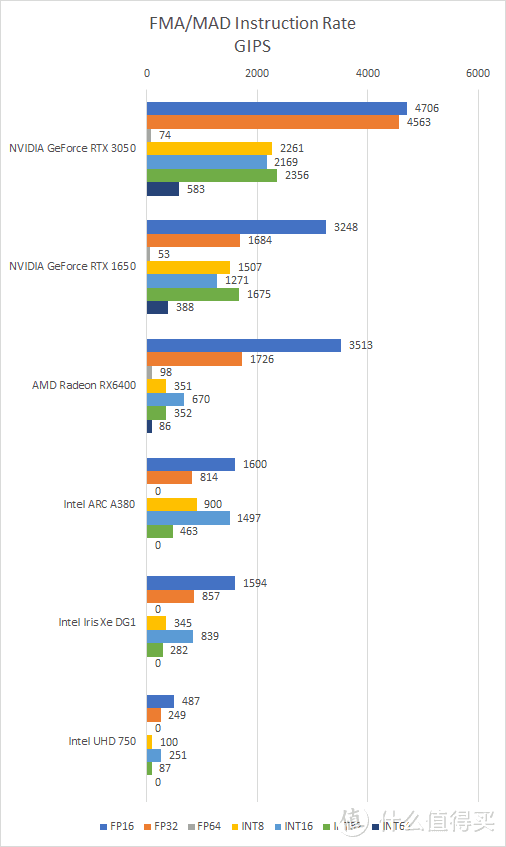
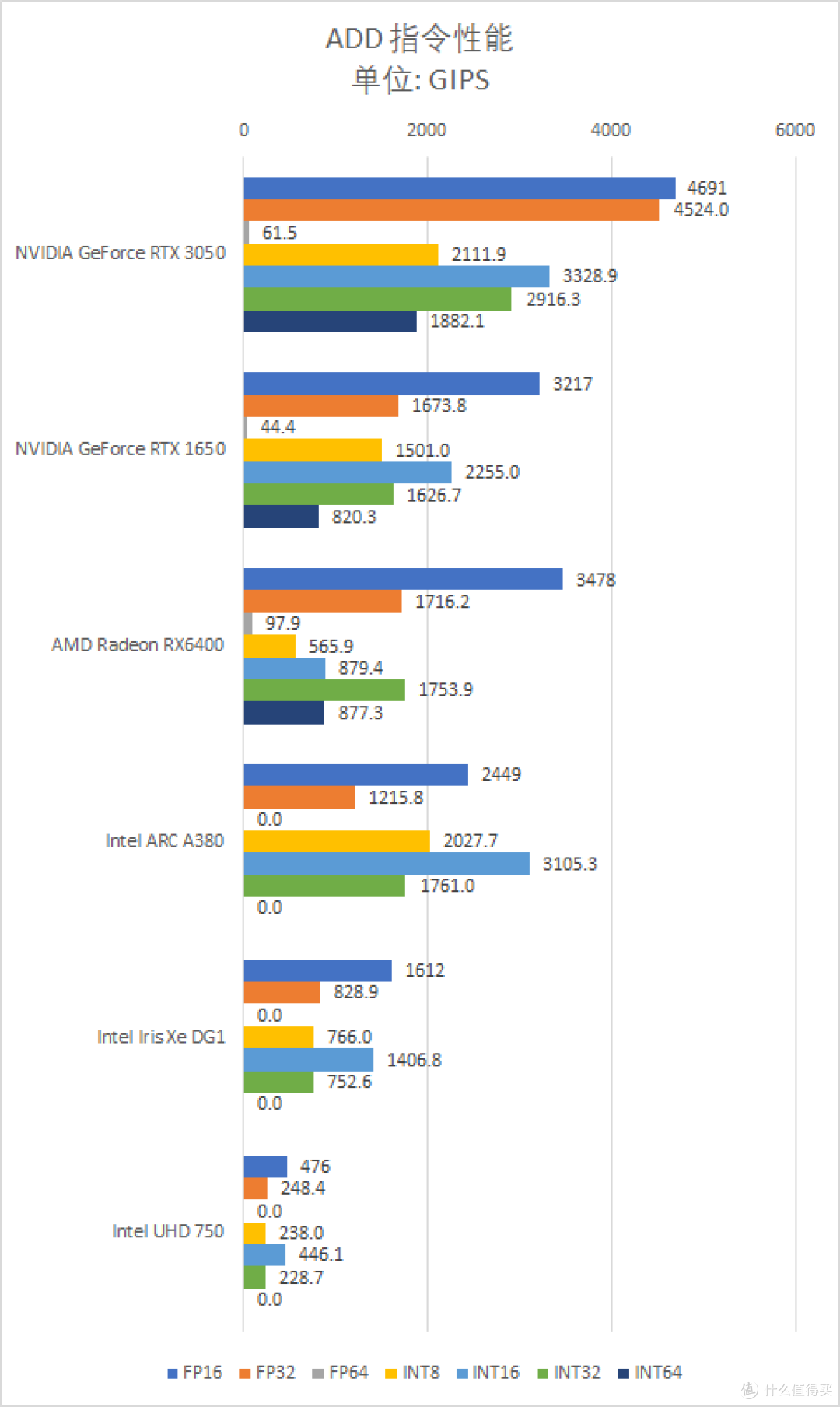




指令吞吐测试属于比较底层的测试。这类测试在编写的时候本应考虑到尽可能地榨尽 GPU 的每一滴计算能力。例如枚举或者嗅探出 GPU 内的线程和局部资源。根据这些数据设定不同级别的线程规模和数组布局。在 GPGPU 编程里的说法就是尽可能地提高 GPU 占用率。
从测试结果来看。Intel ARC A380 的 FP32 FMA 指令性能为每秒 800 GIPS 或者说 1.6 TFLOPS。较理论值低不少。INT32 FMA 的性能是 FP32 的 1/2。INT 16 FMA 是 FP32 FMA 的 两倍。因此出现了 INT16 性能是 INT32 四倍的情况。
按照 Intel Arc A380 的纸面规格。基频 2GHz 下。拥有 128 个 XVE 或者说 1024 个FP32 FMA 的理论性能应该是 2048 GIPS。800 GIPS 的实测值只是相当于理论值的 39%。
造成这个现象的可能原因估计是测试程序的强度不足以唤起 GPU 频率全速运行。
能测试 GPU 指令吞吐的程序还是不少的。为此我找来了 mixbench。得出的结果如下:
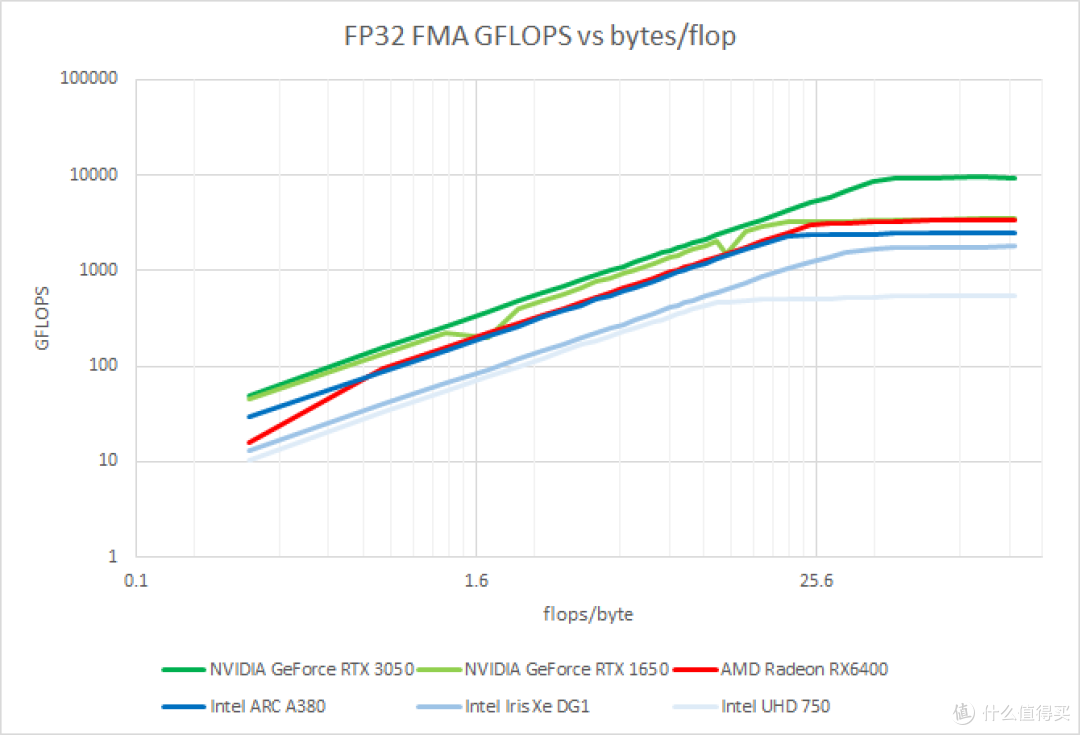 5 款 GPU 的 roofline 或者说天花板图
5 款 GPU 的 roofline 或者说天花板图
上图是根据测试结果绘制的 roofline 或者说天花板图。Y 轴是实测性能 GFLOPS。X 轴是每个浮点操作可匹配的内存带宽(字节)数。这种图一般应用在程序员进行 GPU 性能调优的时候。根据程序热点落在天花板图中的位置决定是否进一步优化以及优化的方向(降低访存需求还是提高计算复杂性实现更出色的特效)。
从 mixbench 来看。Arc380 的实测值大约是 2400 TFLOPS 或者说 1200 GIPS。比上面的测试结果高大约 50%。但是距离理论值 2000 GIPS 仍有不少的距离。
除了上述的两个指令吞吐测试软件外。我还测试过其他的一些指令吞吐测试。结果大同小异。A380 的 FP32 FMA 实测值距离理论值有较大距离。
看到这里。你现在有什么想法呢?先不急。后面我也会说一下这类现象的看法。看看我们是否英雄所见略同。
接下来让我们看看一些图形相关的底层测试。
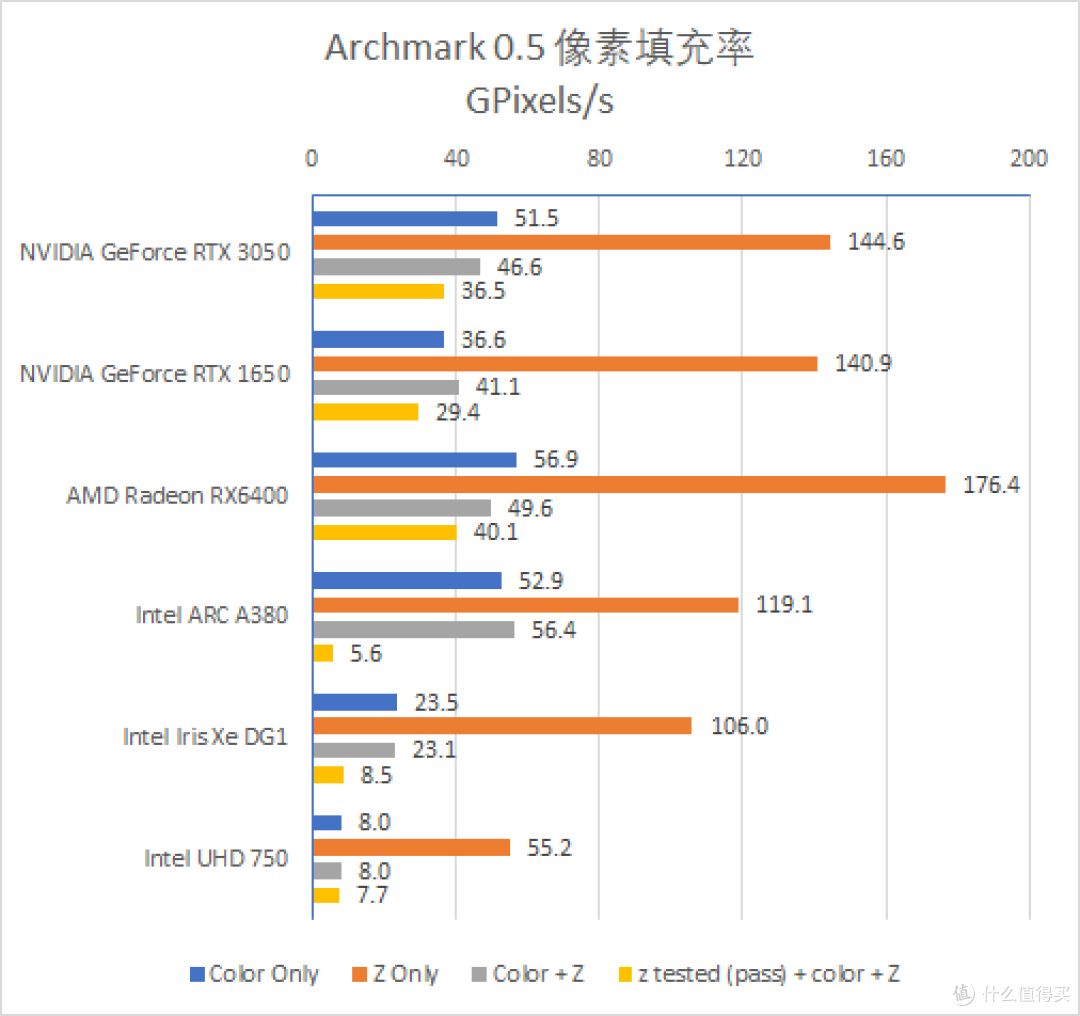
首先看看像素填充率测试。说起来。这类测试我已经很少进行。但是 Intel Arc 是时隔 20 多年后 Intel 推出的独显。很好奇其图形功能方面的表现。所以安排一下。
从测试来看。A380 的纯色彩光栅处理大约是 52.9 GPixs/s。Z-ROP 跑出了 119.1 GPixs/s 的等效性能。是纯色彩的两倍。相较之下。其他 GPU 的 Z 等效性能基本上是 3 到 4 倍。Z 等效性能某种程度上反映了 GPU 进行 MSAA 时候的优化能力。

Archmark 是基于 OpenGL 的测试程序。它的几何性能测试用到了 VBO。如果不支持 VBO 的话就会转用 Display List。从测试来看。A380 的坐标变换性能似乎很差。只有每秒 1300 万三角形的水平。还不如核显 UHD750 的每秒 2.75 亿三角形。
然而在启用了光照处理后。A380 的性能出现了巨幅的提升。可能的解释就是跑坐标变换类测试的时候。GPU 处于怠速状态。当进行复杂的光照处理时候。GPU 又满血状态。甚至比包括 RTX 3050 在内的所有对手都强大。


纹理测试的时候。我让驱动保持了默认纹理优化设置。
NVIDIA 在这个测试中无法完成 5-8 层纹理的混合测试。
Archmark 提供了双线性和三线性测试。缺少各向异性过滤。
从测试结果来看。A380 的纹理过滤在 4 层三线性后和 RX 6400 相当或者说略微占优。
光线追踪方面。Intel Arc A380 也提供了硬件支持。内置了 8 个 RTU(Ray Tracing Unit)。这次的对比产品里。RX 6400 和 RTX 3050 也都具备硬件光线加速能力。
我使用了一个名为 Hairball 的模型进行这个测试。这个模型有接近三百万个三角形。渲染计算很简单。因此主要测试的是 GPU 光线追踪单元。由于三角形较多。会涉及大量的三角形求交测试——目前 GPU 硬件光线追踪加速的主要步骤。


从测试结果来看。RTX 3050、RX 6400、A380 的测试结果分别为 19.8 fps、2.2 fps、5.5 fps。RTX 3050 分别是后两者的 9 倍、3.6 倍。
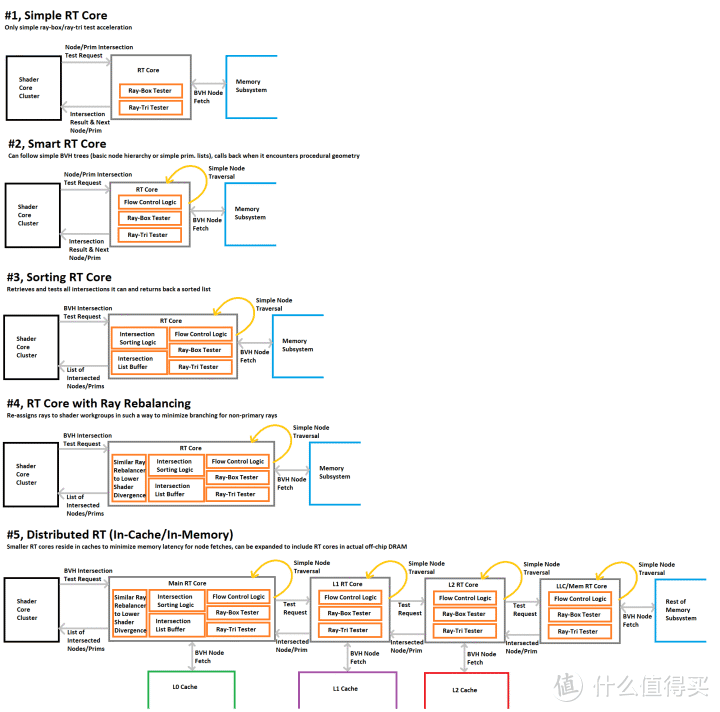 Nemes 根据 ImgTec 提出的硬件 RT 五种实现水平制作的特性对比图
Nemes 根据 ImgTec 提出的硬件 RT 五种实现水平制作的特性对比图
如果按照 ImgTec 的五级(或者说六级。六级模式的时候第 0 级是纯软件执行。上图中不包含六级模式里的第 0 级)硬件光线追踪加速分级(RTLS)。NVIDIA RT Core 接近于上图中的第四级。AMD 的 RA 接近于第三级。ImgTec 表示 PowerVR 的 RT3 表示已经实现了第四级。
即使考虑到 RTX 3050 本身定位高一个档次。A380 依然是有较大的差距。但是和 RX 6400 相比。A380 的三角形光线追踪性能还是要强 1.5 倍之多。
从底层测试来看。Intel Arc 系列 GPU 面临着一个比较棘手的问题——软件优化。这是一个老生常谈的问题。不过 Intel 显然还没有很好地解决这个问题。
没错。对第三方开发人员来说。可以透过一些更新就能让代码更好的运行。但是这样的代价是宝贵的时间需要耗费在旧代码调优上。如果商业公司的话。显然还需要额外的人手来应对客户技术支持。随之而来的还有不可预知的产品风险。
对 Intel 来说。最迫切的当然是让实际的应用例如游戏平稳、高速运行。这也许就是我们使用的底层测试工具目前在 Intel GPU 上出现一些状况的原因——Intel 还没有精力去顾及新 GPU 驱动的普遍性优化。对游戏的针对性优化被放在第一位。
这样的好处是在短期内能尽快见效。对卖 GPU 以及直接客户——显卡厂商和整机厂商有帮助。
更底层的通用优化需要较长时间。换而言之。对最终消费者来说。目前选择 Intel Arc A380 可能得冒着较高的踩雷风险。软件能否如期高效运行目前还是一个问号。
更重要的是。有些问题可能就是硬件约束造成的。驱动日后即使调优。可能也只是一个缓解手段。对用户来说风险依然比较高。
随着时间的推移。Intel 最终会把 Xe-HPG 架构的最好一面呈现给大家。不过时间上会是今年就搞定还是等明年的下一代呢?
答案目前还不得而知。
待更新:
后面会有 Cache/内存带宽、时延测试等结果补充。
指令吞吐测试稍后会更新。
稍后会更新 Cloud Liu 负责的游戏与应用测试。
作者声明本文无利益相关。欢迎值友理性交流。
显卡
和谐讨论~其他人还看了
「amd」RTX40的对手来了!AMDRDNA3显卡发布会官宣
英伟达RTX40系列移动版显卡型号曝光,搭载AD103~AD107GPU
消息称英伟达将推RTX4090移动版:基于次旗舰GPUAD103
 打赏给作者
打赏给作者
郑重声明:本文“Intel桌面独显Arc深入测试”,https://nmgjrty.com/diannaopj_471124.html内容,由edisonchan提供发布,请自行判断内容优劣。

- 全部评论(0)

-
 千元级小钢炮,畅爽游戏兼顾生产力,华硕VG249Q1A
千元级小钢炮,畅爽游戏兼顾生产力,华硕VG249Q1A -
 男朋友说用这个显示器打游戏好爽!
男朋友说用这个显示器打游戏好爽! -
 小米显示器,性价比还是挺高的
小米显示器,性价比还是挺高的 -
 自媒体最佳拍档,这块飞利浦高清显示器我不信你不心动!
自媒体最佳拍档,这块飞利浦高清显示器我不信你不心动! -
 告别平庸的硬盘底座!OIRCO这款“集装箱”,速度快玩法超多
告别平庸的硬盘底座!OIRCO这款“集装箱”,速度快玩法超多 -
 W4K显示器
W4K显示器 -
 朗科(Netac)NV70001TPCIe40SSD固态硬盘测试
朗科(Netac)NV70001TPCIe40SSD固态硬盘测试 -
 Linus考虑让Linux内核放弃支持英特尔80486处理器
Linus考虑让Linux内核放弃支持英特尔80486处理器 -
 13代i7暴打12代i9!憋屈太久了,牙膏厂疯起来真的挺吓人
13代i7暴打12代i9!憋屈太久了,牙膏厂疯起来真的挺吓人 -
 超高性价比的选择,锐可余音“夏至”三件套之CX5电竞声卡体验
超高性价比的选择,锐可余音“夏至”三件套之CX5电竞声卡体验 -
 225元的105寸一线通便携屏SurfaceGO2同款屏幕
225元的105寸一线通便携屏SurfaceGO2同款屏幕 -
 矿难确定不当回开扎古的真男人么
矿难确定不当回开扎古的真男人么 -
 闲置固态硬盘的完美解决方案!奥睿科USB40固态硬盘盒实测分享
闲置固态硬盘的完美解决方案!奥睿科USB40固态硬盘盒实测分享 -
 华硕推出新一代ROGRyuoIII240/360ARGB“龙王”水冷散热器1799元起
华硕推出新一代ROGRyuoIII240/360ARGB“龙王”水冷散热器1799元起 -
 秒懂1U、2U、4U服务器和42U机柜
秒懂1U、2U、4U服务器和42U机柜 -
 2022年了,我才开始用先马趣造
2022年了,我才开始用先马趣造
最新更新
- 千元级小钢炮,畅爽游戏兼顾生产力,华
- 男朋友说用这个显示器打游戏好爽!
- 小米显示器,性价比还是挺高的
- 自媒体最佳拍档,这块飞利浦高清显示器
- 告别平庸的硬盘底座!OIRCO这款“集装箱
- W4K显示器
- 朗科(Netac)NV70001TPCIe40SSD固态硬盘测试
- Linus考虑让Linux内核放弃支持英特尔80486处
- 13代i7暴打12代i9!憋屈太久了,牙膏厂疯
- 超高性价比的选择,锐可余音“夏至”三
- 225元的105寸一线通便携屏SurfaceGO2同款屏幕
- 矿难确定不当回开扎古的真男人么
- 闲置固态硬盘的完美解决方案!奥睿科
- 华硕推出新一代ROGRyuoIII240/360ARGB“龙王”
- 秒懂1U、2U、4U服务器和42U机柜
推荐阅读
- 矿难确定不当回开扎古的真男人么
- 「英伟达」不止是游戏党,他们才是被英伟达坑怕的人。
- 「amd」RTX40的对手来了!AMDRDNA3显卡发布会官宣
- 消息称英伟达将推RTX4090移动版:基于次旗舰GPUAD103
- 海外网友在Newegg购买RTX4090显卡,拆开包装发现仅有两块配重块
- 英伟达高管回应RTX408012GB显卡退市:性能和408016GB差距大
- EVGA宣布不生产显卡后,其GPU超频软件更新支持RTX4090
- AMD新一代旗舰笔记本GPU爆料:RX7900M将达到RX6950XT桌面显卡性能
- 消息称英特尔ArrowLake-S将采用台积电3nm工艺,ARL-P采用Intel20A工艺
- 消息称英伟达GDDR6X版RTX3060Ti将在10月26日上市
- 海鲜市场捡漏“真香”?9000元预算纯白12代风冷主机达成分享
- 华硕率先公布自家RTX3060TiG6X非公卡
猜你喜欢
- [机箱]ITX装机初体验
- [机箱]机箱界的铝厂,支持240水冷与长显卡的乔思伯V8ITX机箱装机点评
- [机箱]安钛克驱逐者DF600FLUX
- [机箱]Thermaltake发布Divider300TG机箱
- [机箱]Zen3架构基础款单核锤爆10900K?AMD锐龙55600X评测
- [机箱]也许是最小MATX主机的完美走线
- [机箱]30系列已到,机电有升级的必要吗?
- [机箱]女王的ITX新电脑上篇之复刻lousuITX机箱
- [机箱]最小ATX乔思伯RM2及风道改造
- [机箱]bequiet!德商必酷发布PureBase500DX机箱
- [机箱]修理机箱耳机插孔
- [机箱]大容积的小钢炮
- [机箱]乔思伯A4水冷机箱+R53600RX5700升级装机
- [机箱]TtLevel20GT全塔机箱开封解析
- [机箱]Dell戴尔小机箱内部升级记



