 大家电
大家电  厨卫家电
厨卫家电  生活电器
生活电器  健康电器
健康电器  数码产品
数码产品  五金电器
五金电器  生活用品
生活用品  好物推荐
好物推荐  网站首页
网站首页它很接近完美了,AMDR97950X全面评测
精选评测好文
北京时间的 8 月 29 日。时隔将近两年后。超威半导体(下称 AMD)发布了他们的新一代的桌面消费级 CPU Zen 4 产品。Ryzen 7000 系列。作为 Zen 3 系列的继任者。Zen 3 系列产品的优秀性能与能效自然不由分说。其一扫Zen 1 & Zen 2 单线程与 Gaming 相较于对手产品的阴霾。不仅获得了长足的 IPC 与单线程性能进步。还在 Gaming 上大放异彩。以至于删除我们上一份稿件的蓝色黑恶势力的 11 代桌面酷睿产品出师未捷直接身先死。直到 12 代酷睿产品的发布才在这些方面扭转了颓势。
作为优秀的 Zen 3 产品继承人。Zen 4
显卡
系列的产品自然备受瞩目。其不仅对微架构进行了改动。还进行了制程大节点的更新。从 TSMC N7 制程切换到了 TSMC N5 制程。至使其同时获得了 IPC 与频率的双重提升。格外的引人瞩目。在这里。OneRaichu 跟 ECSM_Official 共同合作。我们对 Zen 4 的旗舰产品。AMD Ryzen R9 7950X 进行了相应的测评。
下面。我们将从微架构、互联、延迟与带宽、理论性能、游戏、IPC、功耗与能效几个方面进行相应的测评。
测试平台:
CPU1: AMD Ryzen R9 7950X
CPU2: Intel Core i9 12900KF
DRAM: DDR5-6000 CL30-38-38-76 AMD=1T。intel: Trefi=262143
其他小参=Auto。
主板:某 Z690 与某 X670E(均为旗舰 or 次旗舰型号)
(由于 AMD 这次采用了各路媒体分批解禁的政策。9/26。9/27 分两天解禁。这种迷惑操作让我们暂时不能直接展示借用主板的详细信息。尽管我们不受 AMD NDA 的拘束。但为了避免连累到板厂。所以这里暂不展示板厂信息)
BIOS 版本:截止 9/24。均为目前最新版本。
GPU:AMD Radeon RX 6900 XTXH @2700MHz 400W VBIOS
散热:DEEPCOOL 冰堡垒 360 AIO。
规格简介
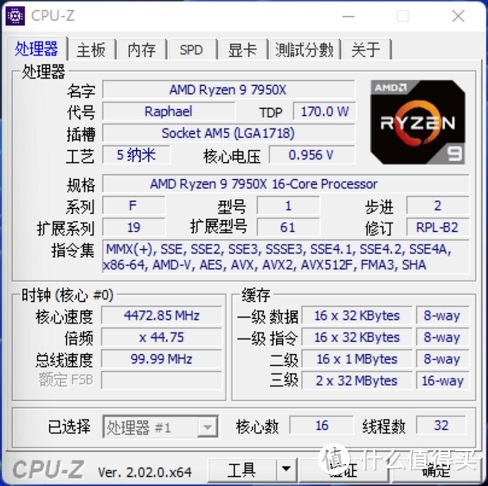
其中 AMD Ryzen R9 7950X 的睿频为:
Max=57x, Fmax=58.5x 低于 55℃ 时可见。多线程睿频视不同压力变化而变化。
内存默认支持到 JEDEC 5200MHz(即默认内存不超频下能支持的最高频率内存。仅限于 1DPC+2CH 或 2DPC+1CH 时)
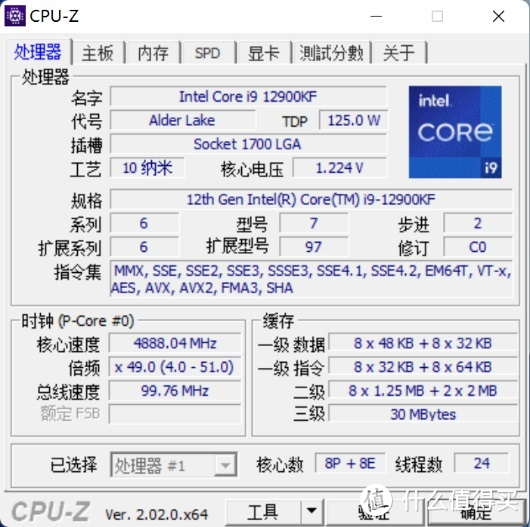
Intel Core i9 12900K 的核心睿频为
P:1C 52x。2C 51x。8C 49x
E:1-4E 39x。5-8E 37x
内存默认支持到 JEDEC 4800MHz(即默认内存不超频下能支持的最高频率内存。仅限于 1DPC+2CH 或 2DPC+1CH 时)
微架构
1.前端:
相较于 Zen 3 来说。Zen 4 在前端做了一些相应的调整。首先是分支预测器的
显卡
部分。按照 AMD 的说法。他们调整了分支预测的每周期执行执行能力。致使其达到了每周期两个指令的分支预测。与之配套的。他们同时调整了 BTB(branch target buffer)的大小。均为增加 50%(L1 BTB 1536 entries。L2 7168 entries)。除了调整分支预测器之外。为了增强前端的指令解码能力。更多的调整在微指令缓存上。其从 4k 条目调整为 6.75k。这意味着其可以缓存更多的解码后指令。降低 Decoder 的解码压力。与此同时。AMD 还调整了 ops cache 的输出能力。其由最多 8 mop/cycle 的输出能力增加到了 9 mop/cycle。
前端的其他
显卡
部分则没有大的改动。其他的改动主要集中在后端显卡
部分。2.后端:
尽管 disptach
显卡
部分没有大的改动。但由于前端的微指令输出峰值有些许的增加。AMD 选择了对重排缓冲区(ROB)进行调整。其由 256 entries 增加至 320 entries。大小增加了 25%。更多的变动出现在 EU 和寄存器
显卡
部分。首先是指令 Retire 的队列显卡
部分。由于 ROB显卡
部分的增大。微指令在后端的 Retire 过程自然会遭受到相对比上代大一些的压力。因此在这里 AMD 选择增加了增加 25% 的指令 retire queue。并且同时还调整了 int 跟 fp 执行单元的可用寄存器数量(int 192 to 224/ fp 160 to 192)。以避免整体运行时可能的指令堵塞。以调整 IPC 情况。另一个显著的变化是 LD/ST
显卡
部分。也就是我们俗称的访存显卡
部分。虽然 Zen 4 并没有进一步加宽 LD/ST 的宽度。但是他们对 LD 的队列情况做了一些调整。按照官方的说法。load queue 增加了22%。由 72 entries 调整为 88 entries。并基于此调整了 DTLB 的尺寸。L1 DTLB 应该是由 64 entries 调整至 96 entries。3.缓存
L2 由 512 kb 12cycle 调整为 1024kb 14cycle。
4.指令
本代微架构搭配支持 AVX512 指令集。支持的情况与蓝色厂商这边 11th 的情况类似。使用 fusion 的情况完成 AVX512 的实现。但由于仅有 2*256bit 的 ALU。因此 Zen4 上的 AVX512 支持为半吞吐。
5.总结
总的来说。这已经不算是小修小改的微架构级别改进。如果说非要找一个类比的话。我觉得这一次的改进类似蓝色厂家从 Skylake 到 Willow cove 的调整。只是幅度没有对方的这么大。譬如 ROB size 上 SKL 到 WLC 提升了约 71%。而 Z3 到 Z4 只提升 25%。因此。同频下获得的 ipc AMD 官方宣传在 8-10% 左右。相较于 SKL 到 WLC 的将近 20% 来说略低一些。但。我想红色厂家的适可而止也仅仅只是为了下一次更好提升做下的铺垫。
互联显卡
部分
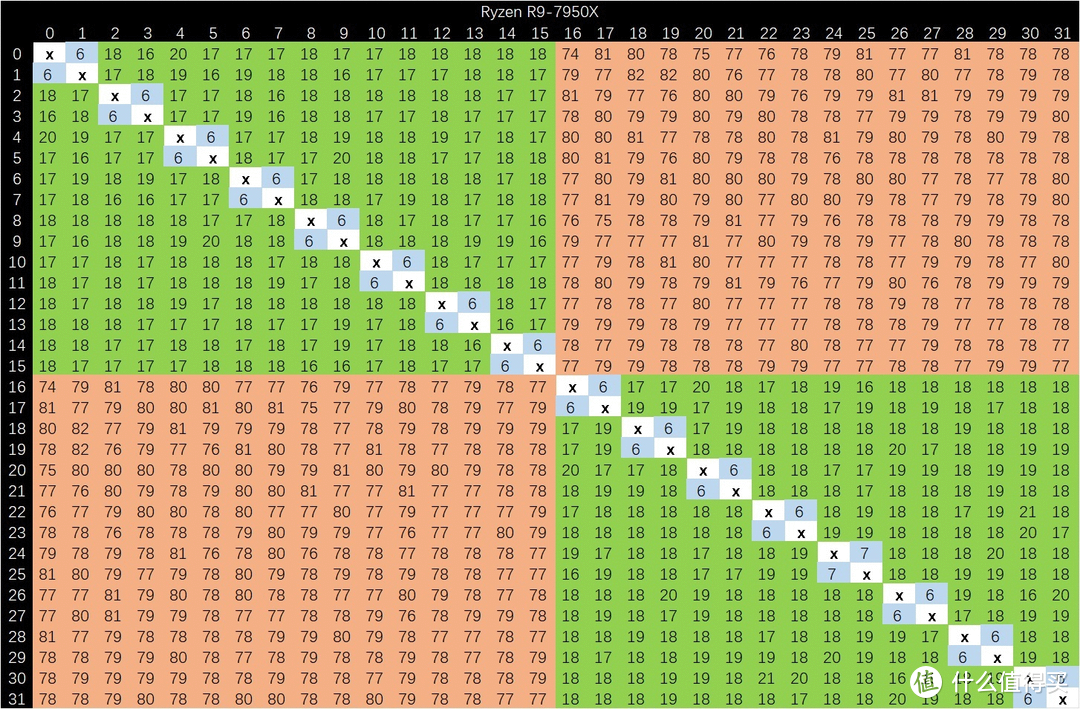
按照国际惯例。首先进行的是核心互联
显卡
部分的测试。使用 microbench CTC 工具。这里不使用求秒工具的原因是因为该工具在跨 CCD 延迟测试 Zen 4 时结果中含有双倍跨 CCD 延迟。但同 CCD 内延迟测试基本一致。从结果中看。可以看见延迟结果是跟上代差不多。8C 一个 CCX。每一个 CCX 单独一个 CCD。跨 CCD 需要增加大约 60-62ns 的延迟。看起来还是原先的设计。并没有做太多的调整。
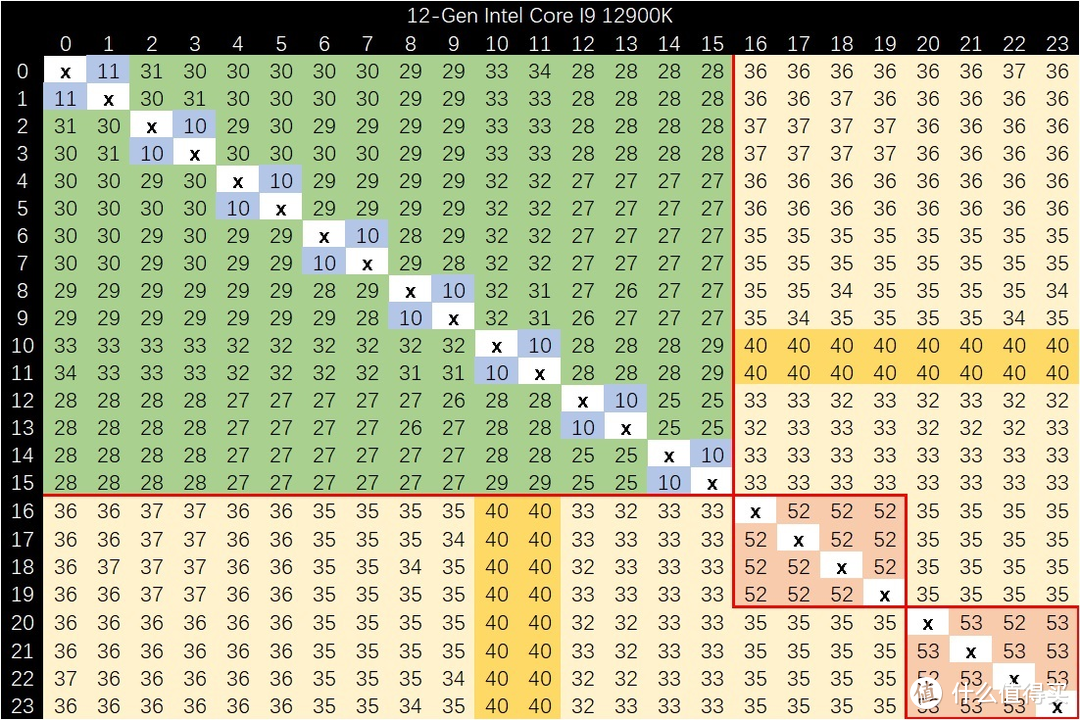
相较于 intel 这边 12900K 的结果来说。CCX 内延迟好于 intel。CCX/CCD 外延迟较 intel 差一些。总得来说有利有弊。
延迟与带宽显卡
部分
首先是快餐 AIDA64 的延迟带宽测试。由于这块板子还没有国内解禁。在这里我们对该主板进行打码处理。
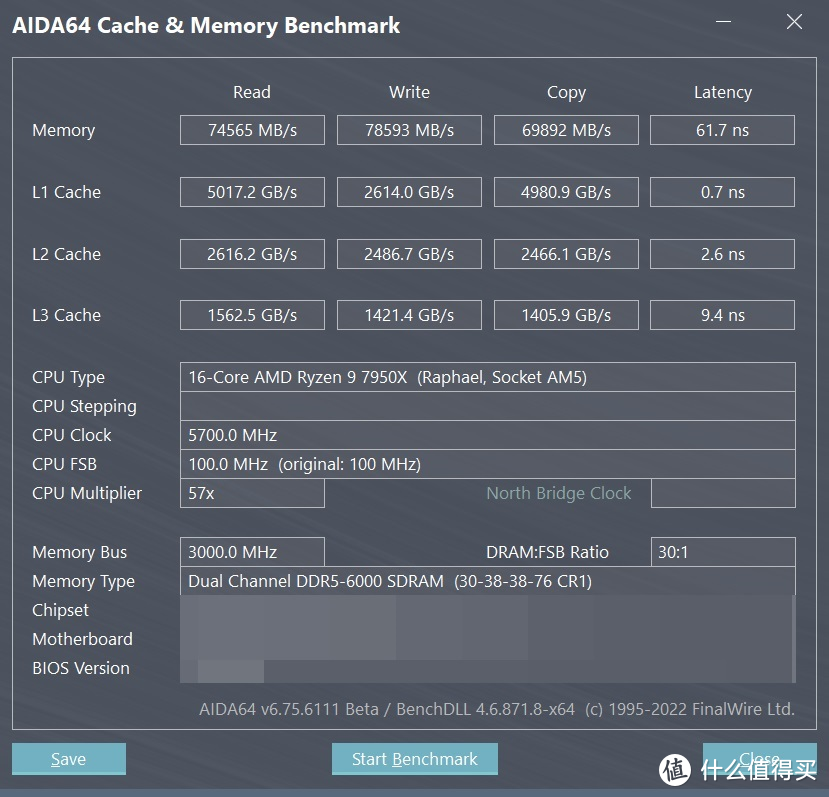
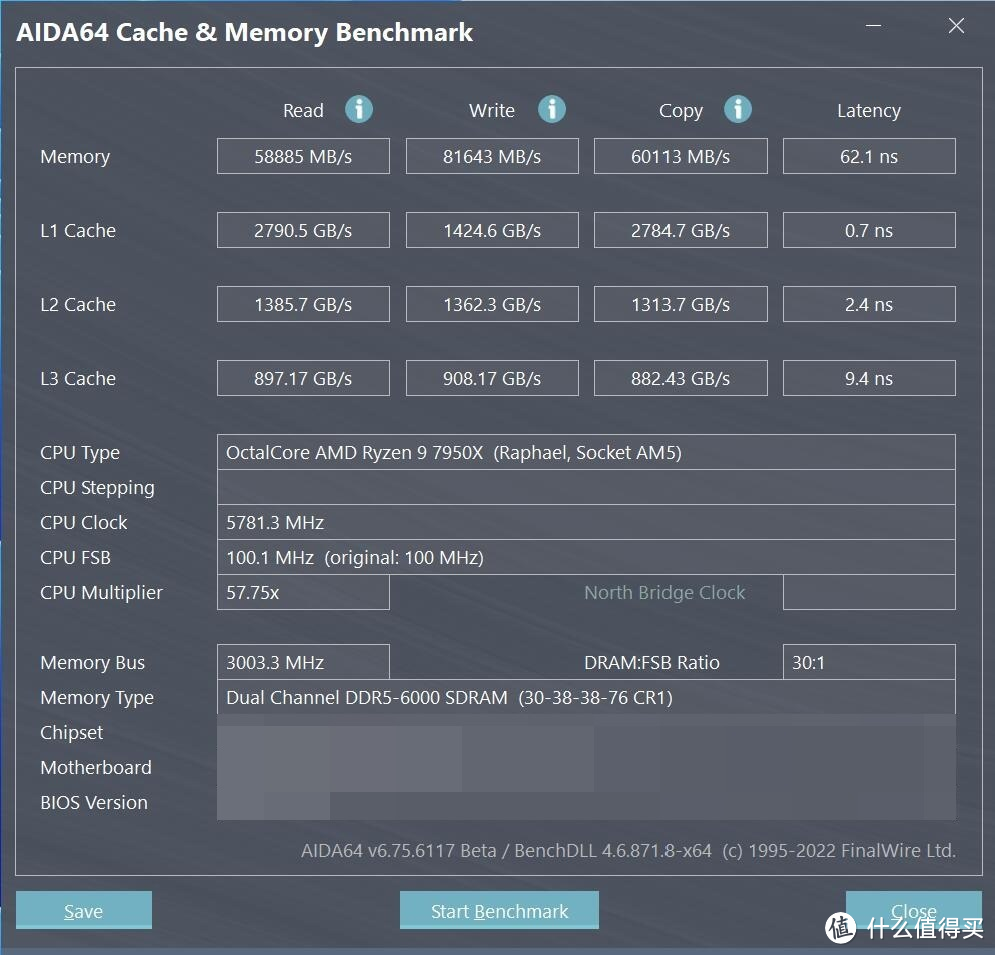
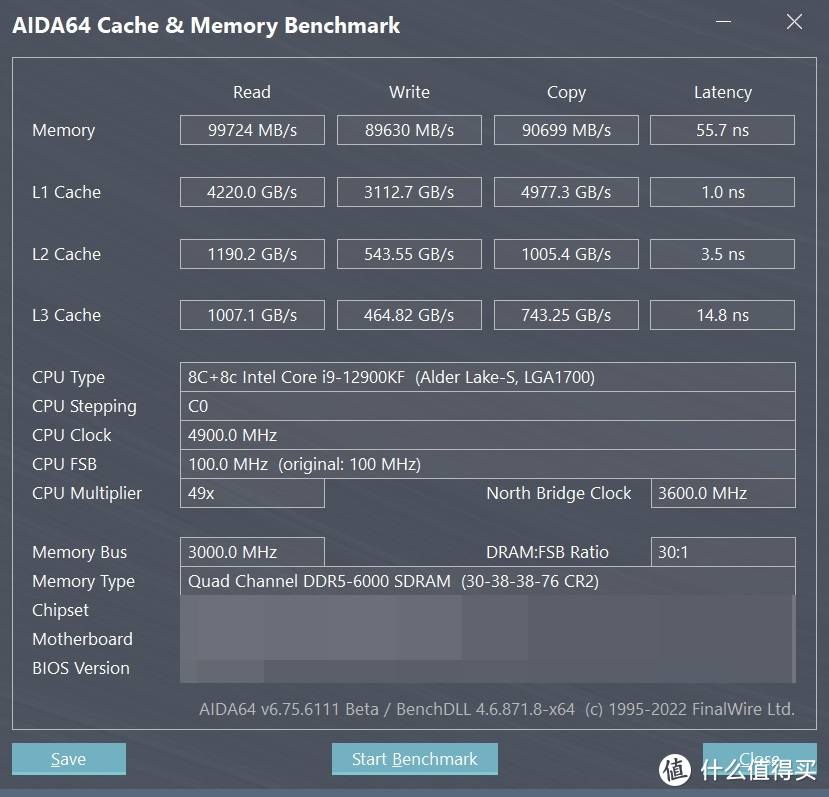
可以看见 AMD 这边的确是 CR1 的设置。其延迟为 61.7 ns 比 AMD 官方参考文件里的 64 ns更低。而 intel 这边对应的延迟为 55.7 ns。
比较明显的问题出现在 AMD 这边的带宽上。尽管这个版本的 AIDA64 已经可以正确识别 7950X。但是带宽测试相较于 6000 MHz 的理论带宽值 96 GB/s 来说还是略低了一些。此结果与后面测试的结果相互印证。确认 AIDA64 的带宽测试并非出现 BUG。
比较有趣的改进出现在了 L2 跟 L3 的带宽上。可以看见 L2 L3 的 bandwidth 有了明显的提升。
另外。本代关闭 CCD2。仅剩 CCD1 时仍旧会出现带宽下降的问题。不过主要出现 read/copy 上。
具体的延迟/带宽测试见下
1.延迟
显卡
部分我们进行了两个产品(对比 12900K)的内缓存延迟测试(使用 Clamchowder 的测试工具)。
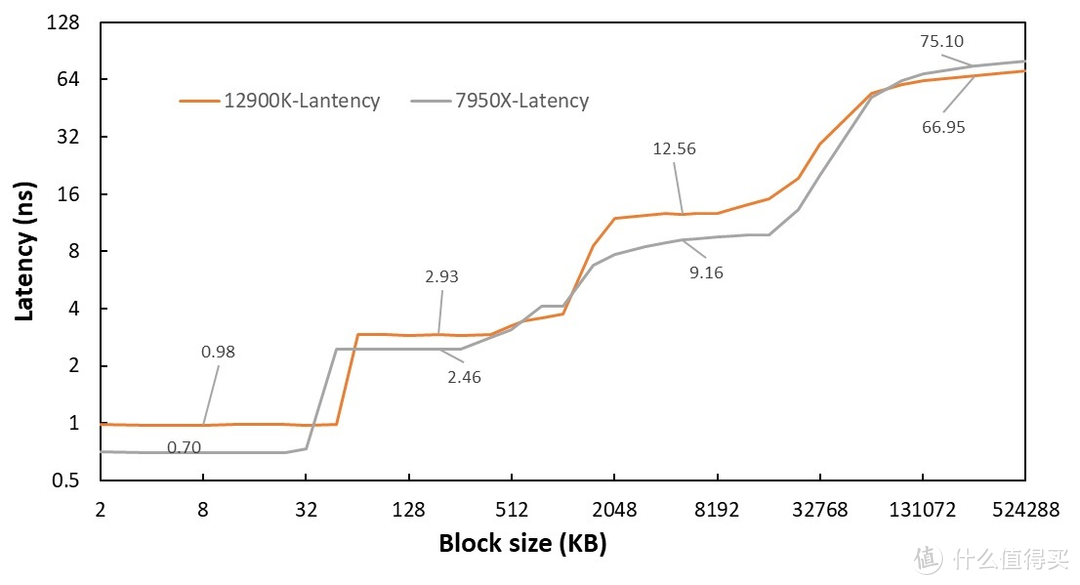
可以看见 7950X 在除内存之外的其他
显卡
部分延迟上均实现了对 12900K 的战胜。除了 intel 这边 L2 有一段因为 Golden cove 更大的 cover 范围外。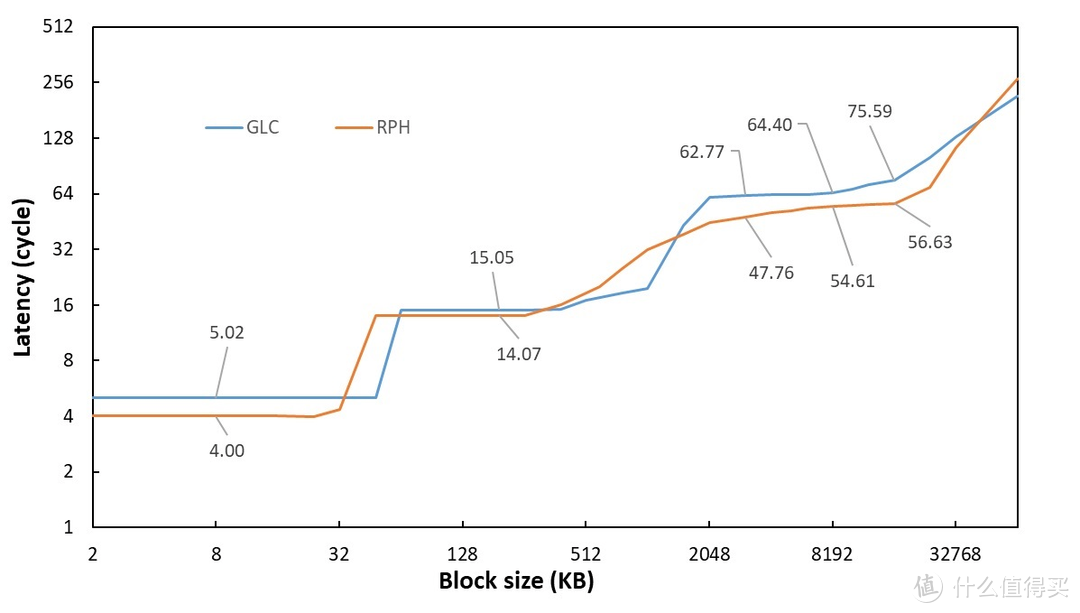
在这里。我们还进行了两个产品同频下的内缓存延迟对比。使用 Cycle(周期)表示延迟情况。
可以看见。不同核心在相同频率下的设计差别。其中:
Intel 这边是 5 cycle 48kb 1。1.25M 15 cycle L2 以及 63 cycle 30M L3。
AMD 这边是 4 cycle 32kb L1。1M 14 cycle L2 以及 50 cycle 32M(2CCD*2) L3
考虑到不同 cache 的 way 情况不同。这个 cache 的配置我个人认为在 L1 L3 上AMD 略胜一筹。L2 上两者基本持平。
2.带宽
显卡
部分完成了延迟
显卡
部分的测试之后。我们还针对缓存/内存的带宽进行了相应的测试。首先是单线程读取/写入
显卡
部分。这里我们直接对单线程带宽进行了频率归一化处理。可以看见实际上同频的 12 代 P core 的 L1 L2-Read 带宽相较于 7950X 带宽略高一些。L3 的带宽则低一些。 Write
显卡
部分带宽则有些变化。其中 12 代 P core 的 L1 write显卡
部分高于 7950X。而从 L2 开始则低于 7950X。与上代有些不同。到了 DRAM
显卡
部分开始。不论是 read/write。均为 AMD 小有优势。其中单线程 read 带宽相较于上代 Zen 3 来说有较大的提升。会为浮点性能带来比较好的进步。这与 IMC 的改进是密切相关的。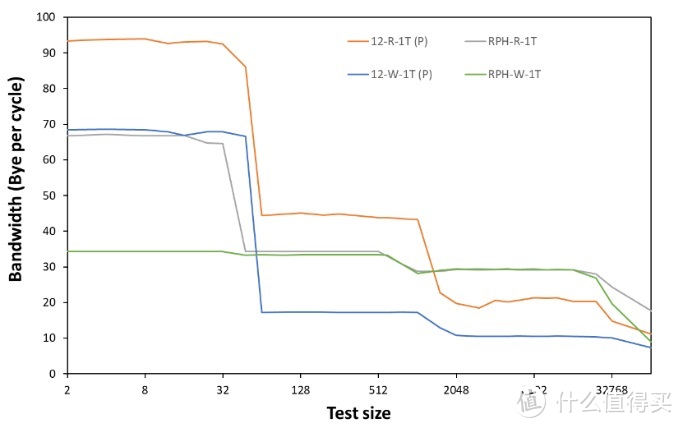
我们还测试了指令带宽。可以看见 7950X 的指令带宽在 L1 的
显卡
部分略优于 12 代 P core 这边。尽管这里摆出没有 Zen 3 的数据。但实际较于上代 Zen 3 产品来说还是有这明显的改进。到了 L2 L3显卡
部分。则 NOP8/4 的带宽两者持平。到了接近内存显卡
部分开始。则 12 代 P core 逐渐占据优势。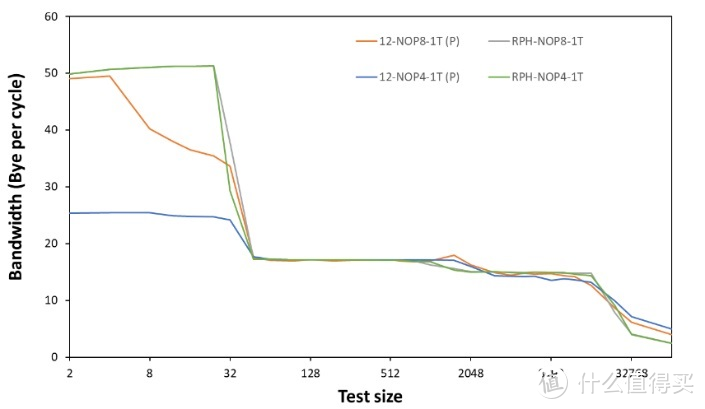
类似的。我们还测试了多线程 read 带宽。
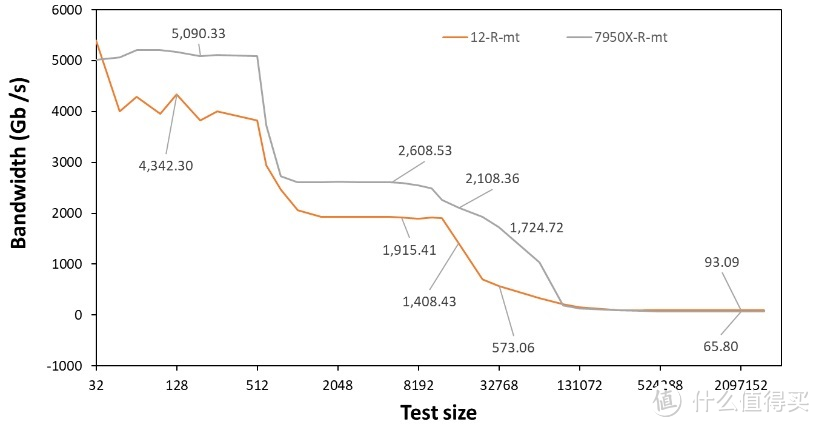
可以看见。AMD 的确在 L2 L3 上做了提速处理。这也因此增加了 L3 的延迟。从上代的 46 cycle 到 50 cycle。从内存带宽的情况上看。似乎的确与 AIDA64 测试的接近(测试位置不同)。AMD 的多线程内存带宽确实受到了较大的限制。
由于在 Ryzen 7000 系列的产品中。内存控制器频率 UCLK 以及 IF 总线频率 FCLK 不再继续维持 1:1 的情形。其中 UCLK 频率继续与内存频率 MCLK 维持在 1:1 的情形。而 FCLK 与二者之比则通常维持在 2:3:3。这里我们使用的是 6000 MHz 的 DDR5 内存。
此时的三者频率为 2000:3000:3000。我们猜测此时的多线程带宽受限的主要原因是 IF 总线频率不足。2000 MHz IF总线搭配 Zen 4 IOD 可获得的最大 read 带宽可能为 64 GB/s。而这个值远小于 DDR5 6000 所能提供的 96 GB/s。也因此我们在 2GB size 测试的带宽为 65 GB/s 附近。
而由于 UCLK 频率的大幅度提升。其能够供给给核心的单线程带宽大幅度提升。去年的 Zen 3 在浮点项目上受限的一个重要原因是尽管每周期能执行的 LD 指令数跟 Golden cove 相同。但其 IMC 能够供给的最大带宽仅有 20+ GB/s。今年 Zen 4 上的 IMC 实现了频率的重要提升。也因此提供了足够的带宽。其单线程 read 带宽甚至来到了 35 GB/s 以上。比竞争对手的 Golden cove 还要多 10% 以上。然而这也来到 3 路 LD 单元的极限吞吐上。
换句话说。也就是内存频率的提升对 Zen 4 这边的单线程/多线程带宽提升都不会很大。因为单线程带宽已经接近极限。而多线程被 IF 总线限制也无法提升。可能内存对于 Zen 4 来说提升的只有延迟与
显卡
部分 Gaming 了。这种带宽限制的设计。如果不是当前版本的 BIOS BUG 的话。那么我想会
显卡
部分带宽需求较大的多线程应用造成明显的瓶颈。譬如显卡
部分科学计算。如果您的日常使用中可能偏重这些场景的话。在选择前请谨慎考虑。理论性能
由于蓝色势力的阻挠删帖。再加上认识的朋友以一顿大餐作为抵偿。致使 10/20 之前我们无法再一次发布某不知名 24C 32T 产品的测试数据。不过也给了我们更多的时间去测试在新 BIOS 下的表现。所以这里只有 12900K 跟 7950x 的相关数据。敬请各位读者见谅。
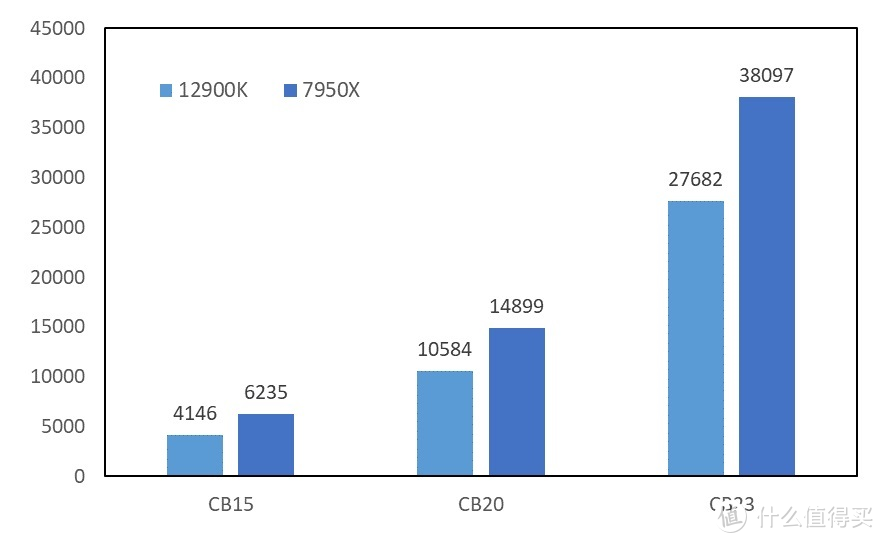
1.Cinebench
显卡
部分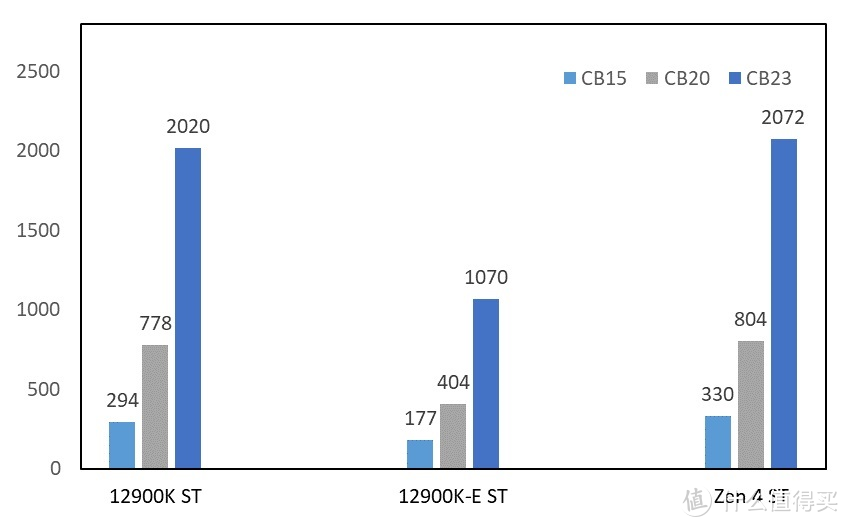
2.3DMark 物理分
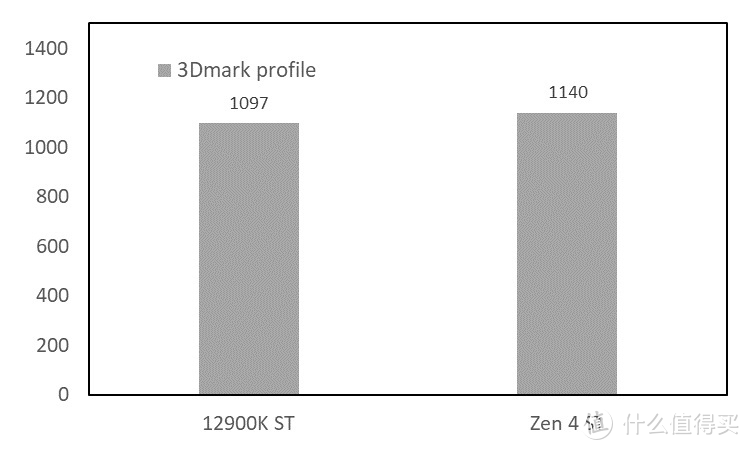
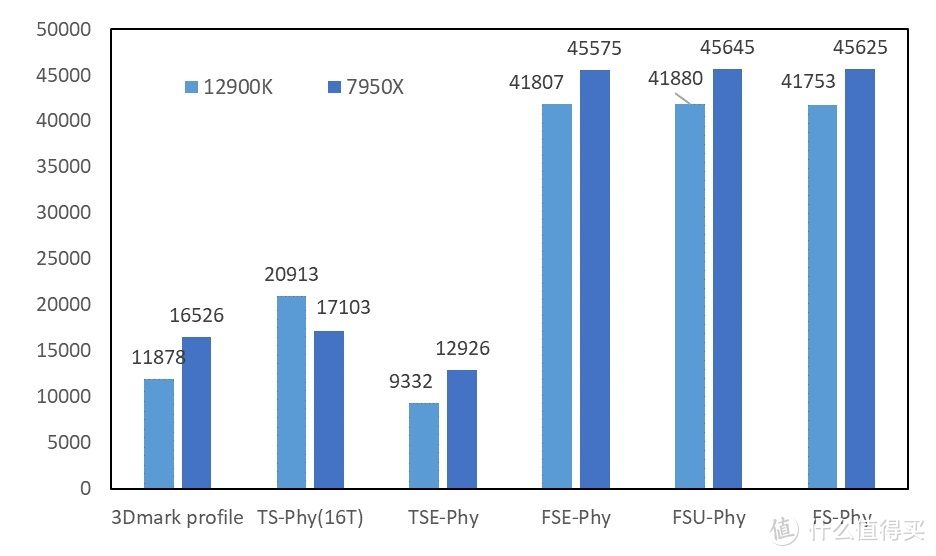
可能是由于带宽的影响。在 TS 的物理分中。出现了 12900K>7950X 的情况。
3.SuperPi
显卡
部分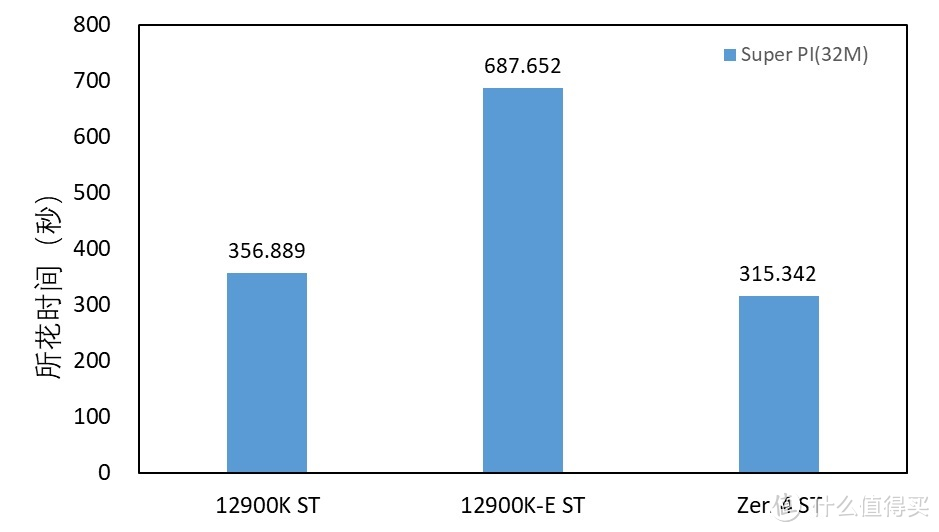
4.CPU-Z
显卡
部分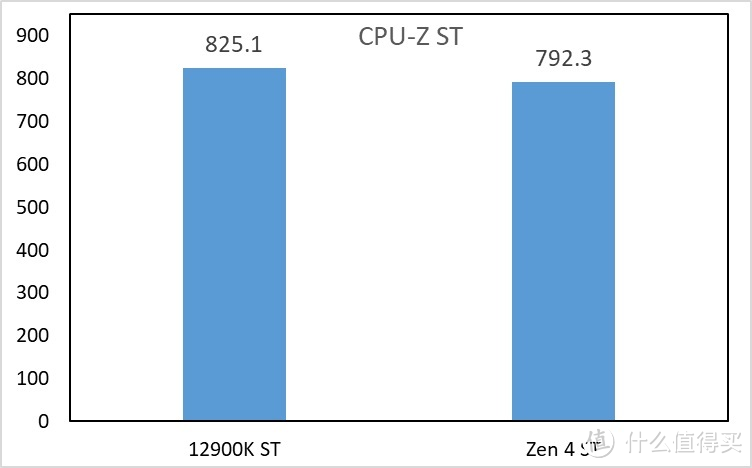
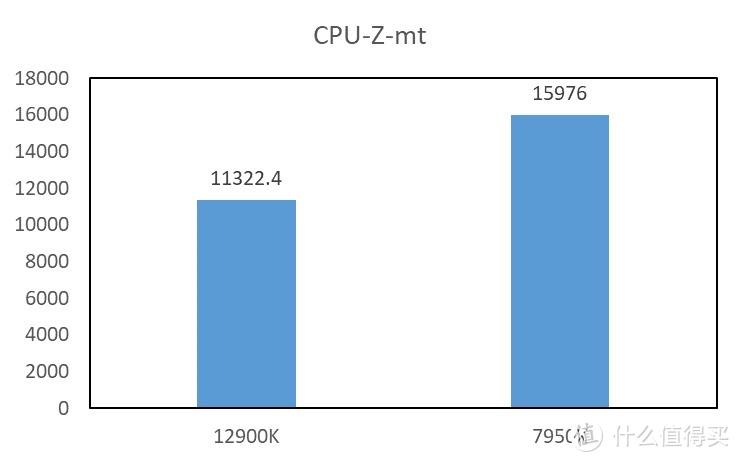
5.解压缩
显卡
部分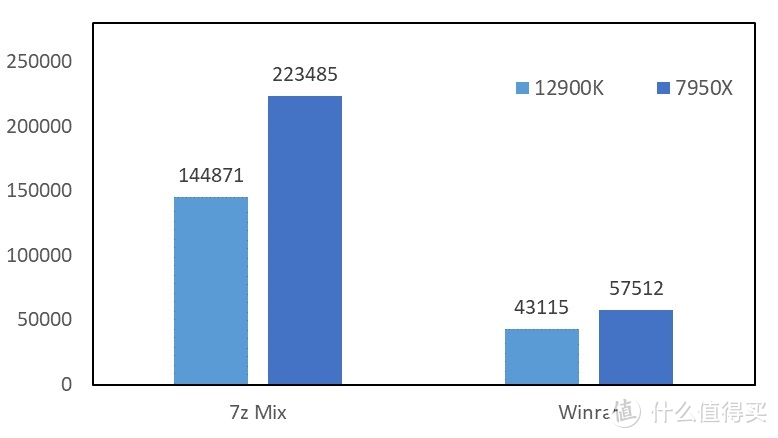
我们使用了 7Z 的总结果替代了子项。
6.AIDA64
显卡
部分由于
显卡
部分项目在多次测试时结果不正常。这里我们选择的项目如下。并且以后的流程都是这些:FP32、FP64、SHA3、Zlib、AES、Queen、SHA1-hash、Photoworxx、FP32-RT、FP64-RT。关于 FPU显卡
部分项目项目。可能是因为适配的原因。我们在测试时会有蓝屏 watch dog 的情况。故没有计入其中。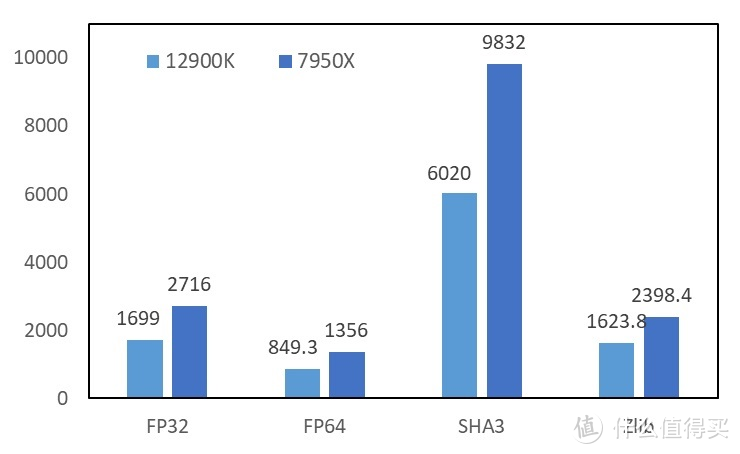
AIDA64 的 FP32/64 支持 AVX512 输出。从 FP32/64 的表现中也不难看出 Zen 4 的 AVX512 与 11 th/12 th P core 半吞吐 AVX512 接近。如果是全吞吐的 AVX512 的话。在此项目中得益于频率相较于 12900k 来的更高。实际成绩应当接近 intel 这边的 3x。
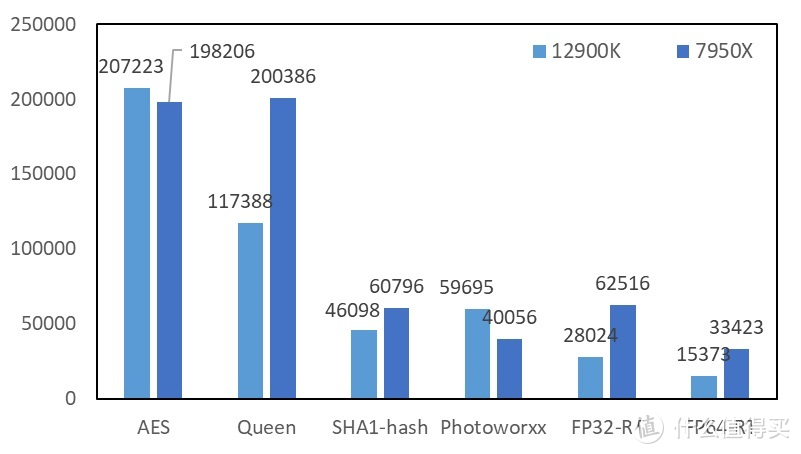
关于 Photoworxx 项目。由于出现严重的带宽问题。致使 Zen 4 在这个项目中不如 12900K。
测试项目总结:
单线程
显卡
部分: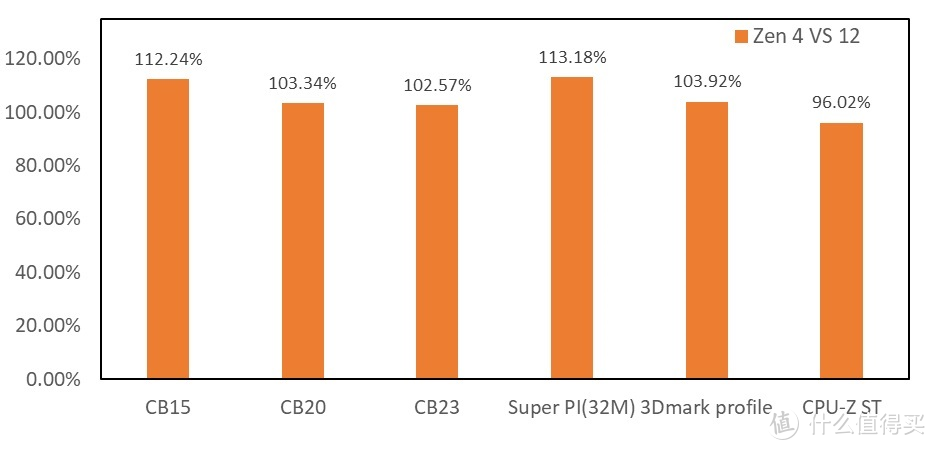
多线程
显卡
部分: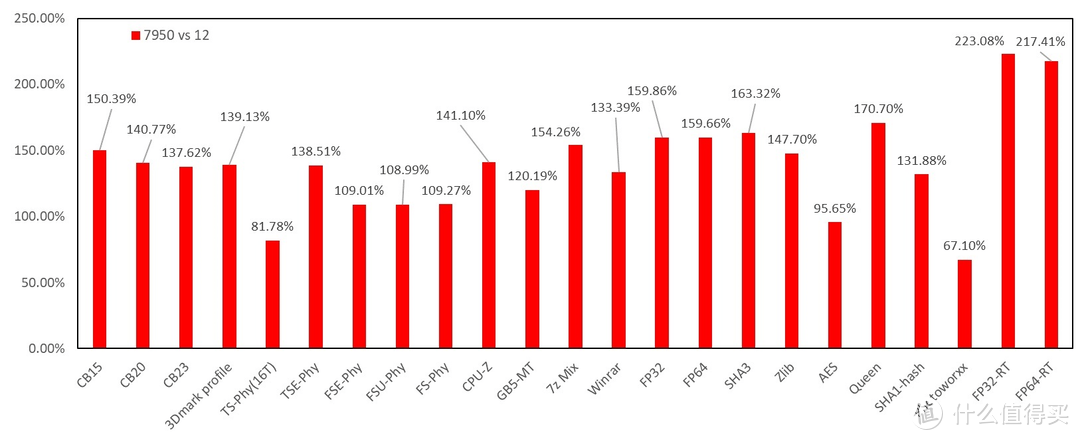
SPEC 与 Geekbench
在性能测试的基础上。我们分别使用了 SPEC CPU 2017 1.1.8 以及 Geekbench 5.4.4 进行了对应的 IPC 测试。同时测试了默认频率的情况以及 3.6GHz 时的情况。仅供参考。
1.SPEC CPU 2017
显卡
部分OS:WSL2-Ubuntu20.04
编译器:GCC/Gfortran/G++ 10.3.0
测试参数:-O3
无任何第三方内存库(No jemalloc/mimalloc)
首先是单线程
显卡
部分: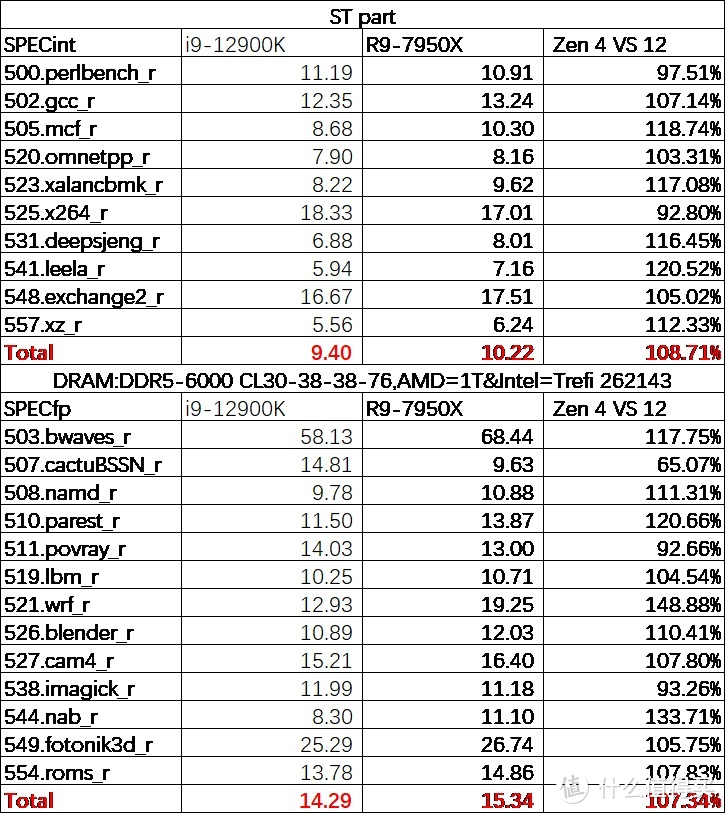
我们首先测试了默认频率下单线程性能。在默频情形下。得益于频率与 IPC 双重提升的因素。7950X 的 ST 与 FP 均双双领先于 12900K
显卡
部分。领先幅度在 7-9% 左右。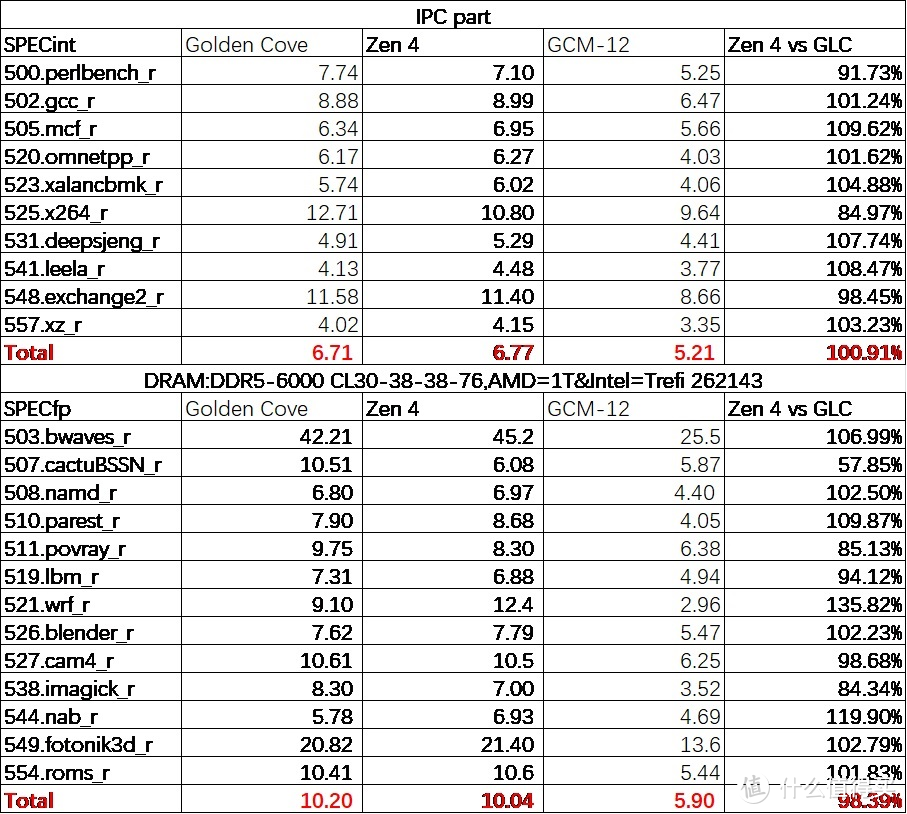
随后我们测试了 3.6GHz 下的 IPC 情况。可以看见 Zen 4 在这个环境下实现了对 GLC 的 int
显卡
部分 IPC 反超。而 FP显卡
部分则仍旧略输于 GLC。值得注意的是。如果使用第三方内存库如 jemalloc/mimalloc/qcmalloc 等。测试的结果则会略有不同。主要在 520 等几个子项上。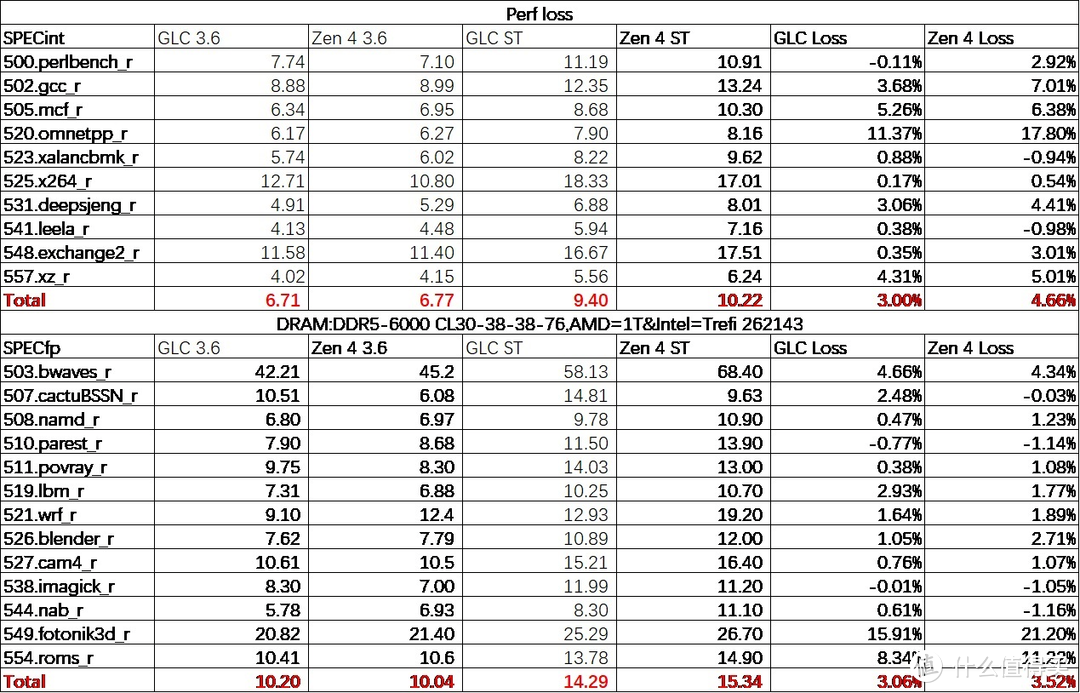
我们还测试了一下 IPC 损失的情况。可以看见由于 Zen 4 的 private cache 略少。再加上考虑到频率更高的细节问题。5.7GHz 的 Zen 4 似乎 IPC 损失比 12900K 的 GLC 核心更大一些。当然也跟 Linux 下 intel 这边的 ST 睿频能更好的发挥出来有关系。
我们还测试了 LLVM 下的单线程情况。可以看见在 Clang10 下单纯的 C/C++ int 项目里。Zen 4 的领先会比在 GCC 中更大一些。
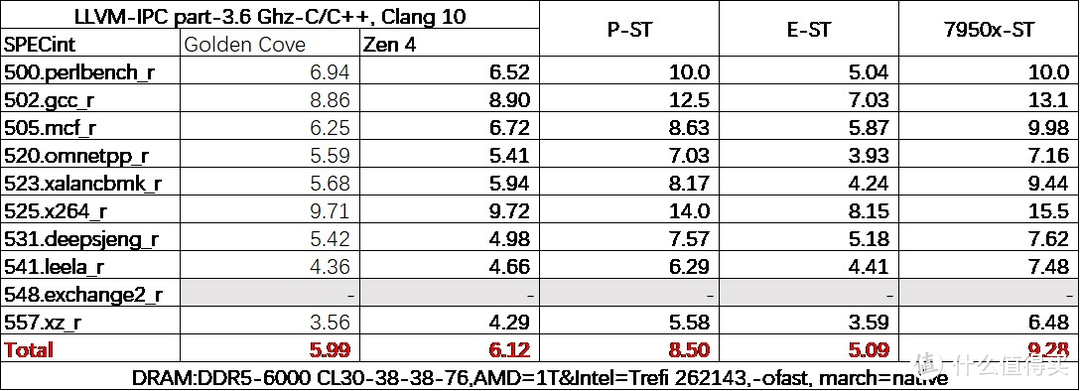
除了单线程之外。我们还使用 GCC 编译器测试了多线程
显卡
部分。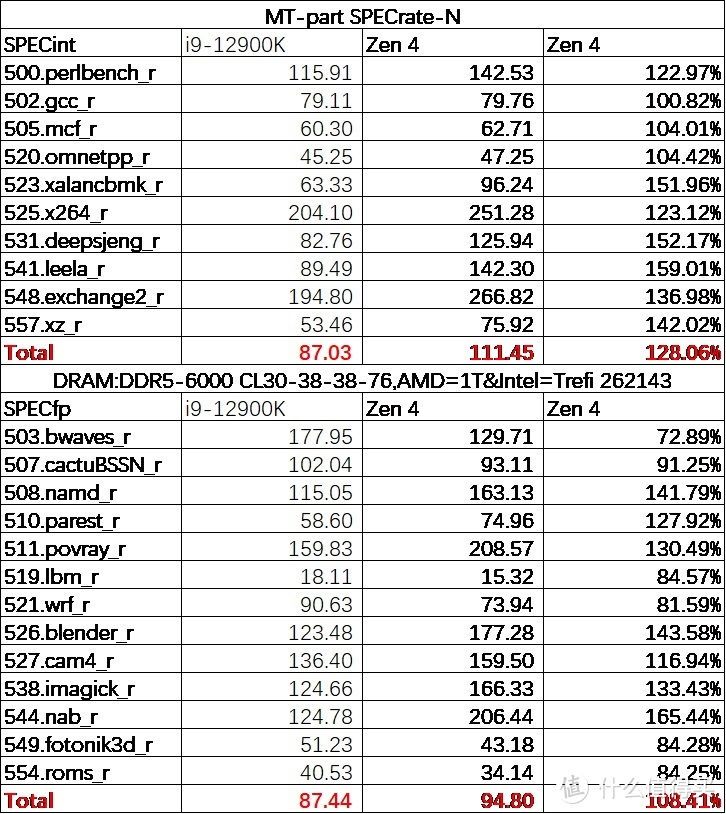
从结果中可以看见。在 int 中。16 个大核心的 Zen 4 领先的幅度较大。实现了大约 28% 的性能领先。而在 fp 中。情况则有所变化。由于受限于内存带宽的重要 bound。其大量项目出现严重倒车。甚至出现大幅不如 12900K 的情况下。好在有不少不吃带宽的项目拉高性能。最终还是相较于 12900K 实现了大约 8.4% 的性能领先。
2.Geekbench 5.4.4
首先是 ST
显卡
部分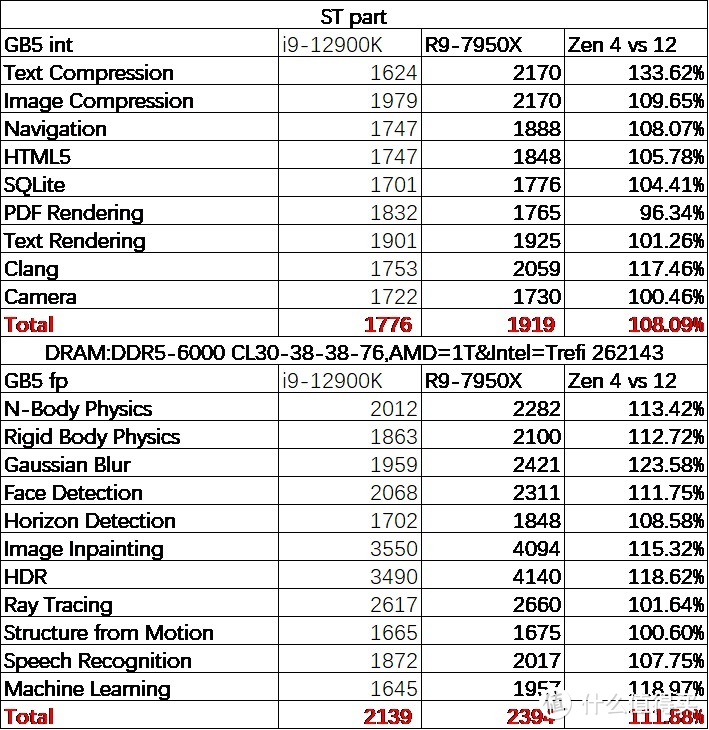
可以看见 ST
显卡
部分的性能领先大约在 8-12% 之间。随后我们使用 Geekbench 5.4.4 进行 3.6 GHz 的 IPC 测试
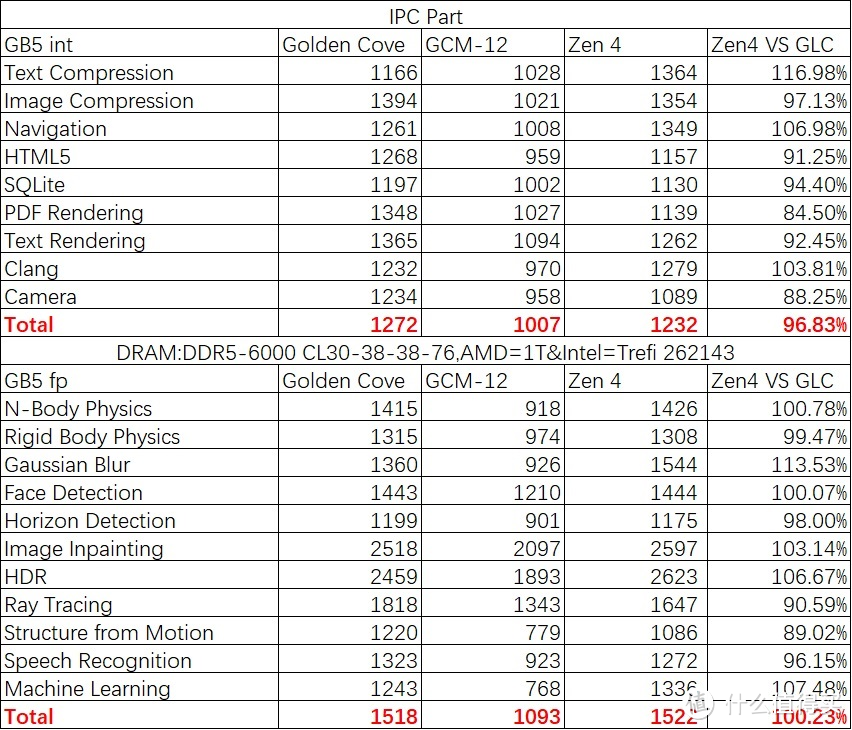
可以看见两者的 IPC 基本相同。其中 GLC 在 int 上略胜一点。
紧接着。我们测试了 IPC 损失的情况。
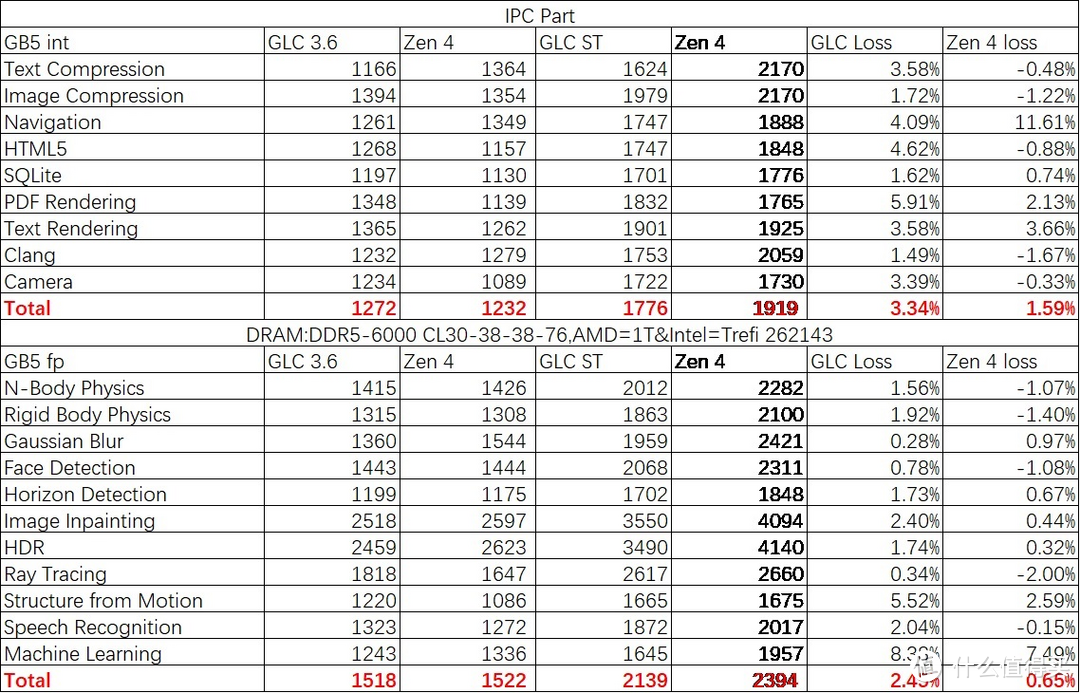
可以看见在 Win 下的睿频机制下。与 SPEC 情况不同。Zen 4 的损失要相较于 GLC 更小一些。
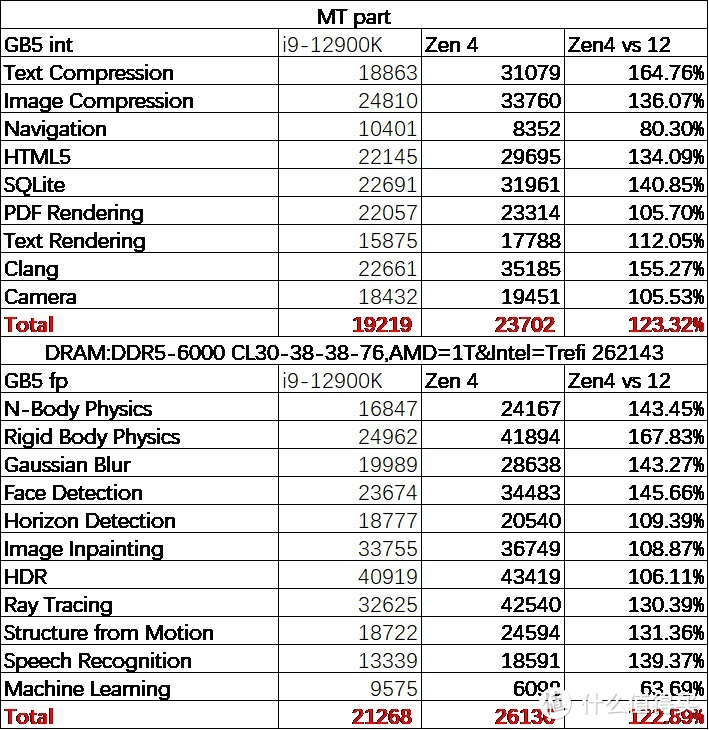
最后我们还测试了多线程的情况。可以看见 GB 对带宽的渴求相对还是弱一些。由于数据碎片更小。这个时候测出来的结果也相对于产生严重 memory bound 的 SPEC mt 好一些。仅有 Navigation 与 Machine Learning 两个项目出现了比较严重的内存瓶颈问题。致使 16 个大核心反而不如频率更低的 8 大 8 小。
游戏显卡
部分
由于 ADL/RPL 平台依旧兼容 DDR4。所以这里额外安排了 DDR4 3600 C17-19-19-39 Trefi 262143 的平台测试。
为了确保测试公平统一。所以均采用游戏内自带的 Demo 和帧数统计。并且每款游戏均运行 5 次 Demo。取平均值。如成绩出现与其他四次较大的差距。那么本次成绩无效。补测一次。若游戏本身帧数统计包含小数。则会保留相应位数的小数。否则一律四舍五入。
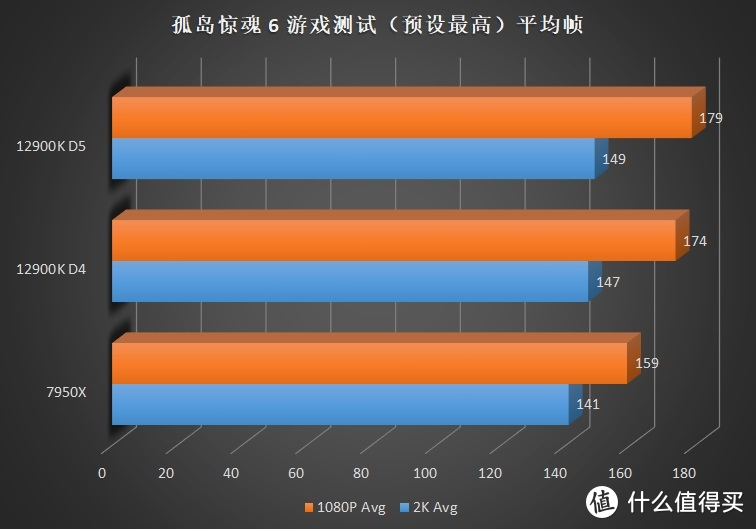
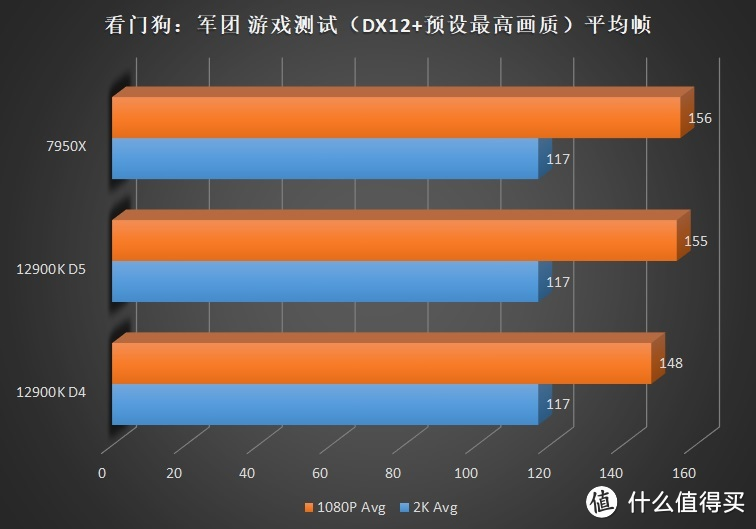
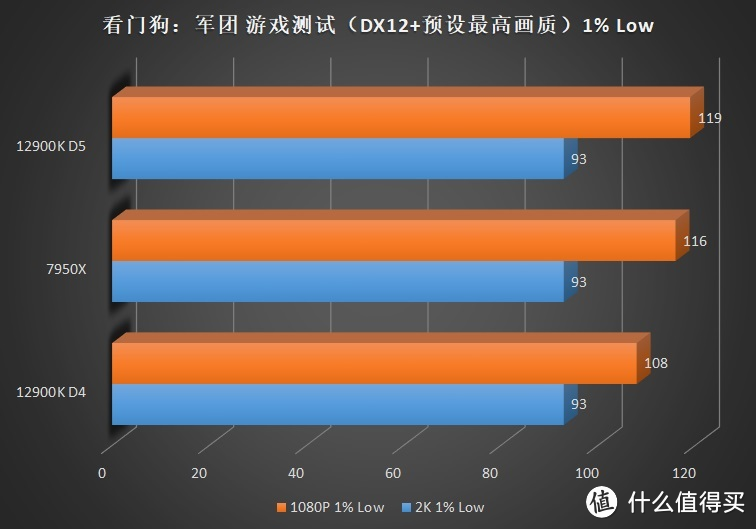
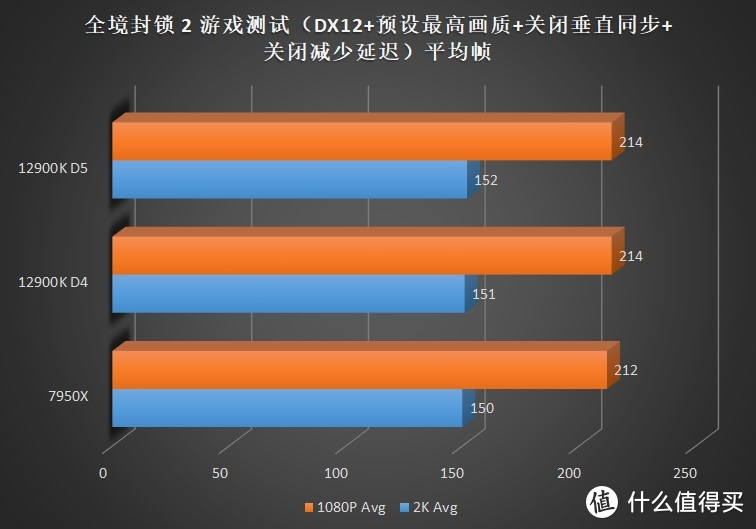
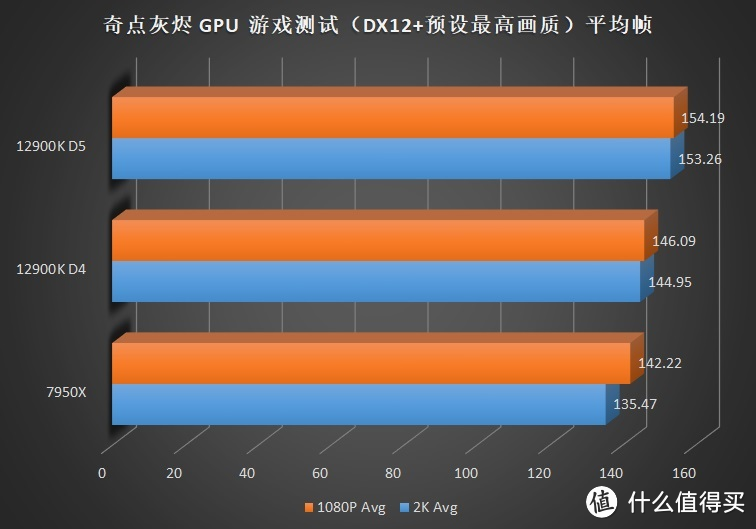
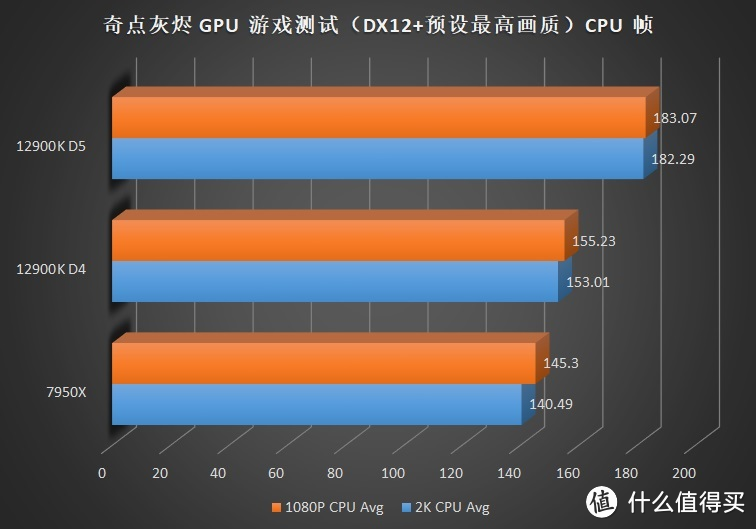
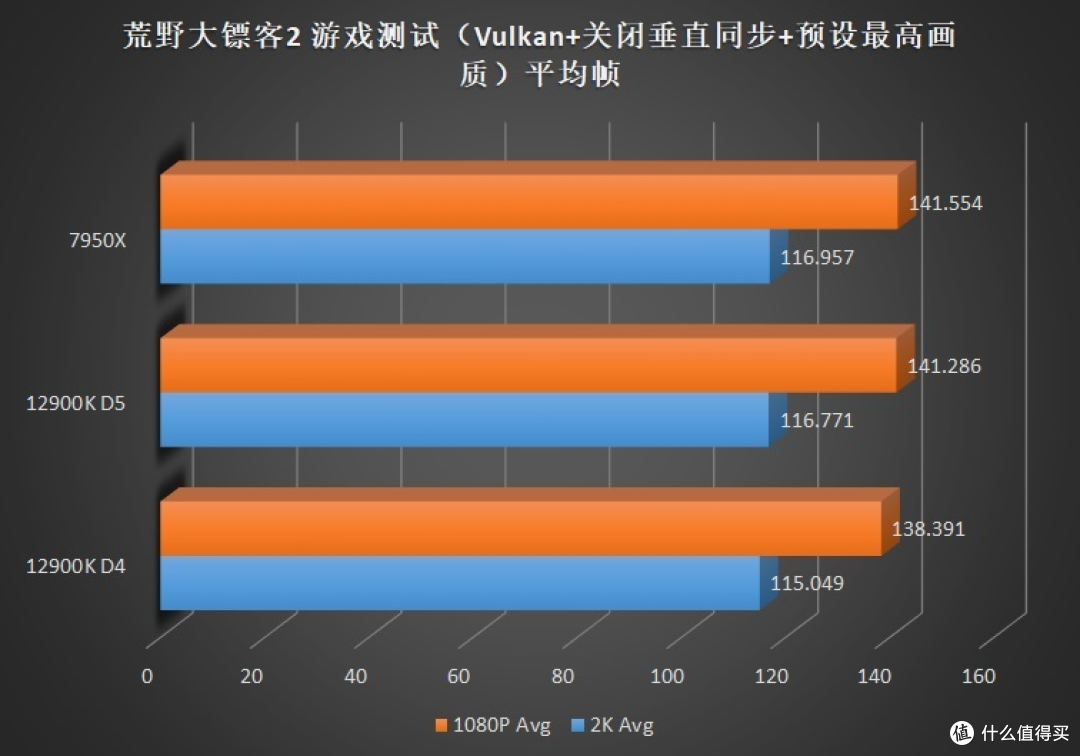
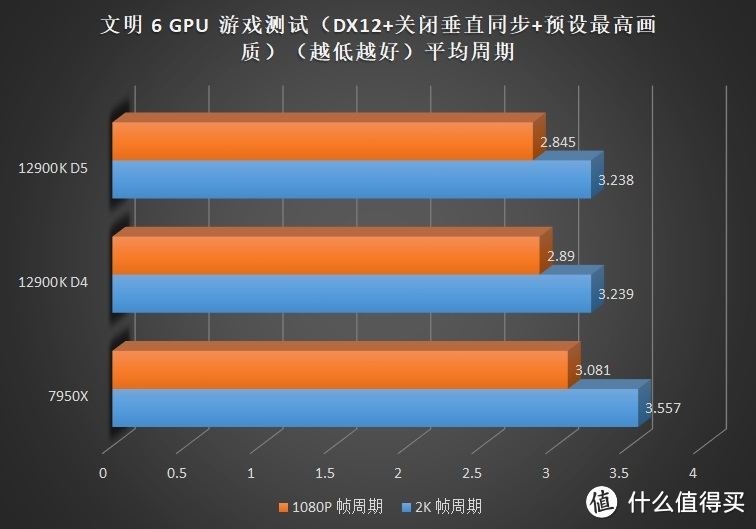
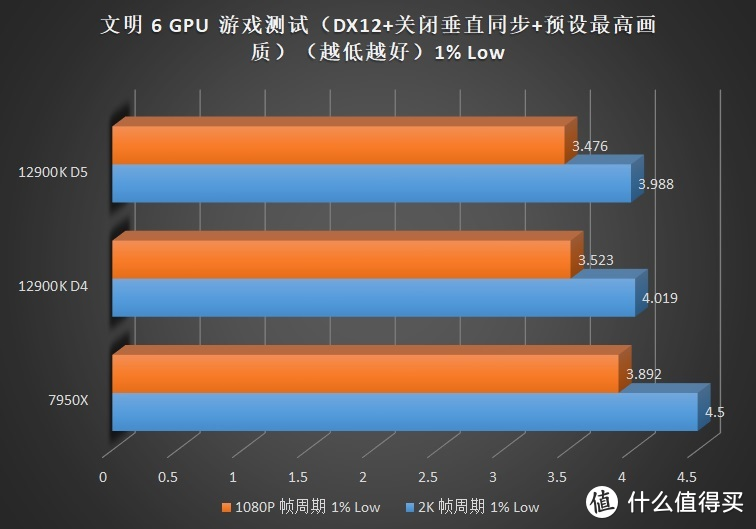
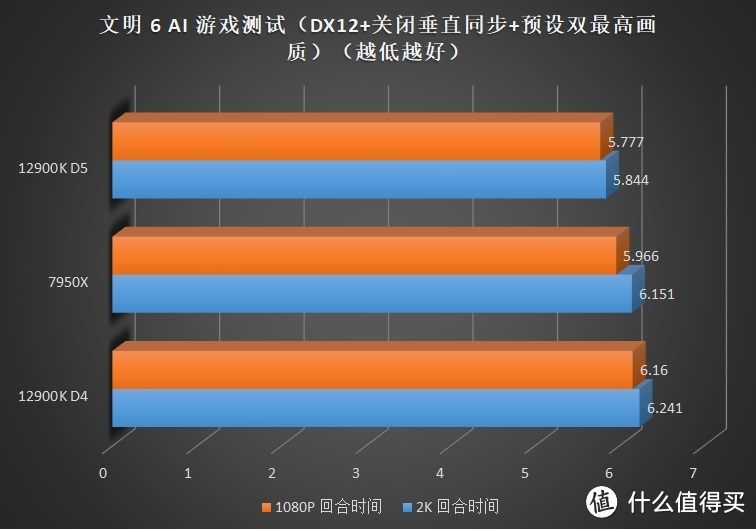
关注我们时间较长的朋友可能发现了。这次的评测和之前某次评测时的成绩似乎些许的变化。这主要是由于 7950X+6900XT 在使用 WQHL 5.1 版本显卡驱动时在
显卡
部分游戏中会出现成绩大幅度下降的问题所致。在 WQHL 5.1 驱动、看门狗:军团项目中。相较于新版本 8.2 的驱动 Benchmark 成绩大约会低 15%。然而 12900K 平台则无此问题。这主要是由于 CPU 适配所致。为了公平起见。我们对 Gaming显卡
部分进行了重新测试。
在游戏测试中。由于普遍无法使用所有 CPU 核心。游戏帧数的提升自然就没有理论性能提升这么大。不过高频带来的提升就是实打实的了。
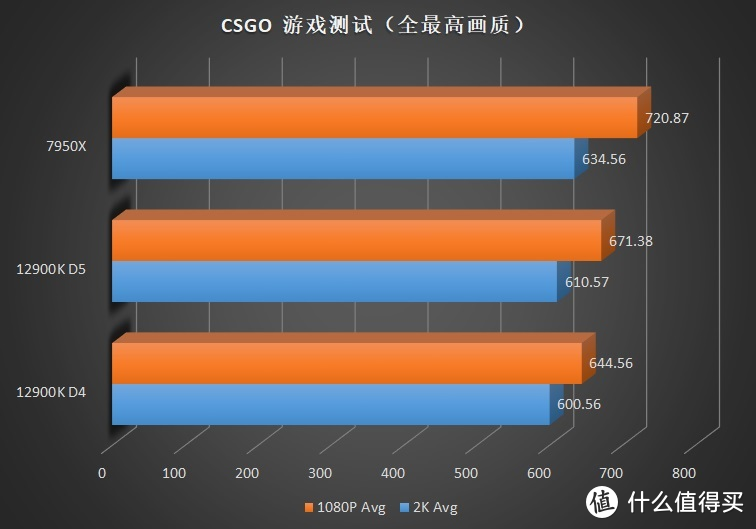
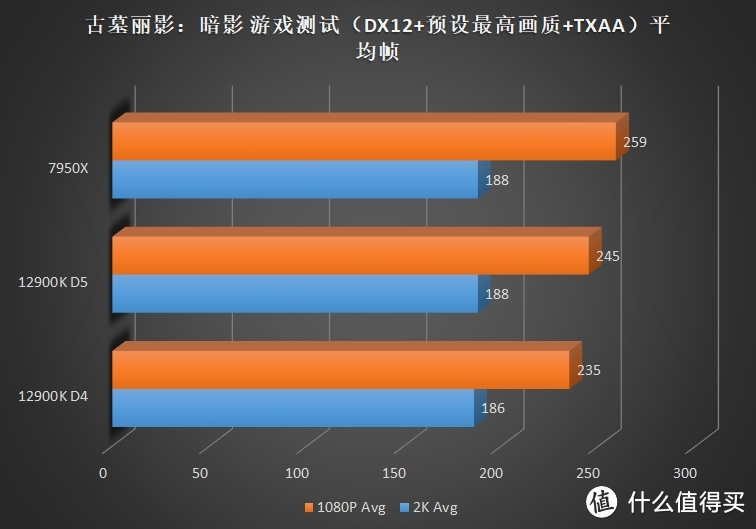
在几乎所有测试游戏中。5.5G+ 的 8 核心基本是经常看见。甚至偶尔可以看到 5.7G+ 的超高频率。因此对于频率依赖较大的游戏中。例如 CSGO、古墓丽影均展现了较大的超越。CSGO 超越 12900K 7.3%。古墓丽影超越 5.7%。
不过古尔丹。代价是什么呢?后果是此时的 CPU 功耗明显较高。
显卡
部分场景甚至超过 140w。甚至比上代 5950X 的功耗来的还要高了一些。不过此功耗下温度却并不高。产生这些问题的主要原因是我们认为在游戏这些中低负载的运行环境中。AMD 的电压似乎有些过于激进。尽管 AMD 使用了 N5 HP 工艺进行 Zen 4 核心的重构。然而 N5 毕竟本质是更多面向移动端产品的高能效工艺。在跑这种超高频率上仍然还是需要加压处理的。所以这个问题也能理解。
不过我们认为电压仍有一定的优化空间。但就目前来看。你至少需要一个双塔风冷或者水冷搭配它使用来达到最大运行频率。
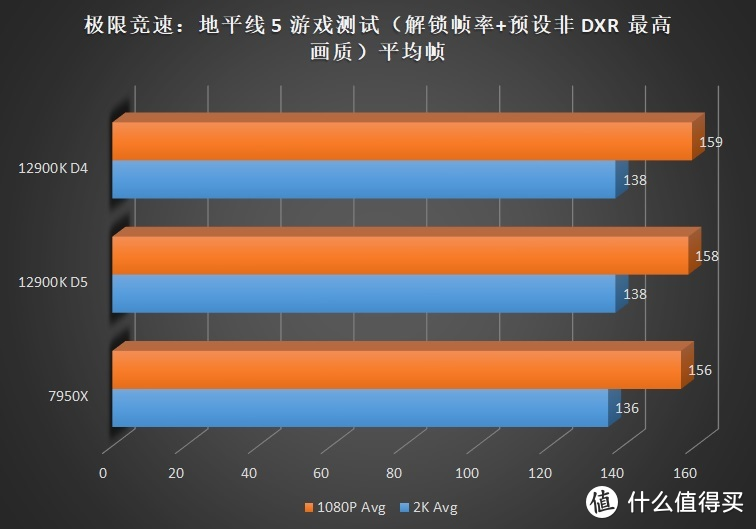
在偏向 GPU 更多的游戏(优化较差)。例如地平线 5、看门狗、大表哥 2 中。AMD 也展现出和 12900K 几乎无差别的帧数。个位数的差距基本处于误差范围内。
但是偏向内存的游戏就明显疲软。例如需要大量内存带宽的游戏。如奇点灰烬、文明 6 等。7950X 受限于 IF 总线频率不足的问题导致无法提供更大的带宽。所以即使使用了速度更快的 DDR5 也无法全面超越 12900K。

值得注意的是。孤岛惊魂 6 这个不太吃内存的游戏居然也出现了大幅度落后。经过简单的验证我们发现。在运行基准测试的时候。显卡在
显卡
部分场景的使用率会大幅度下降。有时甚至无法维持在 70% 以上。也就是显卡并没有全力渲染。12900K 虽然在这款游戏中也会有占用不满的情况。但是并没有 AMD 如此严重。并且在这款游戏中关闭 Resizable Bar 在 AMD 平台反而可以获得 2~4% 左右的性能提升。
Resizable Bar 可以让 CPU 直接访问显卡的全部显存。当然。这需要占用一定量的 IF 带宽。这不由的让我们怀疑是否是由于 IOD 内部交换带宽不足导致的 DRAM 和 PCIe 互相影响。不过这仅为我们的猜测。具体的答案就需要 AMD 给我们了。
我们对 AMD 的游戏表现的概括非常简单。7950X 与 12900K 之间有来有回。单论 CPU
显卡
部分来说。他的游戏性能可以说是非常强劲。游戏运行时可以非常轻松的看到 5.5G 甚至以上的频率。并且是多颗核心一同达到如此的高频。这是我们前所未闻的。这也是目前为止 x86 平台在游戏中 Auto 频率最高的处理器。甚至媲美某颗即将上市的 24C 的处理器。令人扼腕的是 IF 的带宽始终还是影响了
显卡
部分游戏性能。超大 64MB 的 L3 也无法发挥全力。这实在是令人惋惜。如果 AMD 有幸看到了这段总结。我们希望在下一代产品中 AMD 能够尽可能避免这个问题。由于我们本职工作的原因。所有测试几乎都是在晚上完成的。为了防止垮起个批脸第二天去上班。再加上无法长时间借用 CPU 和主板。所以这次还是无法安排 1% Low 的测试。还请各位谅解。
功耗与能效
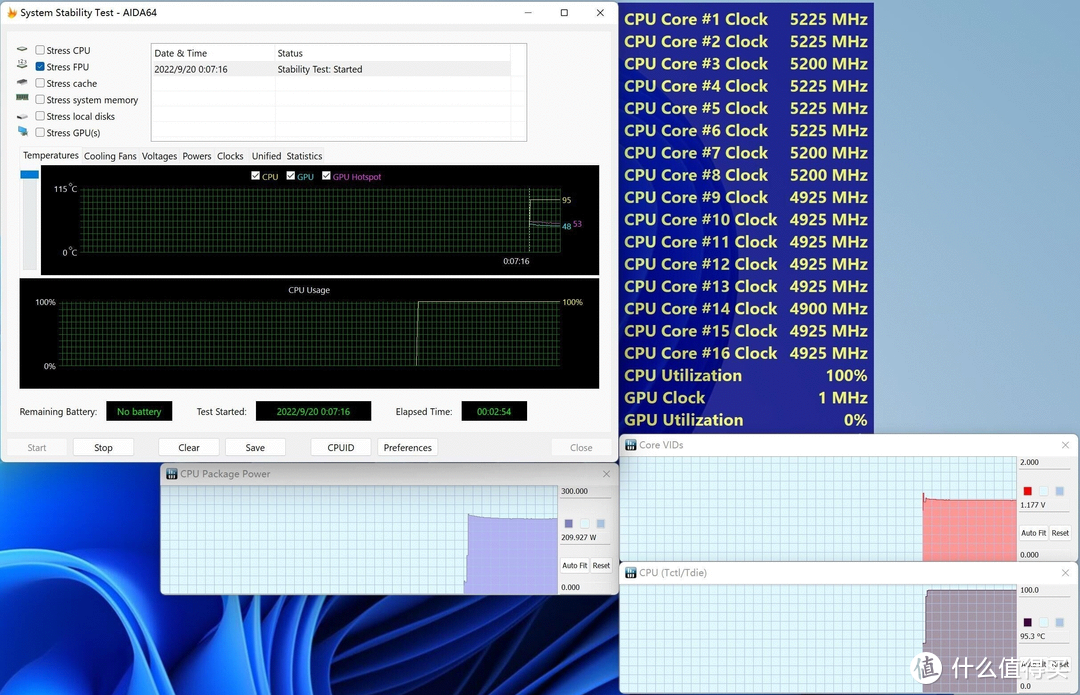
在我们使用的 DEEPCOOL 冰堡垒 360mm 体式水冷下。初始的功耗约为 230w。随后在一秒内撞上了 95 度的 Tjmax 温度墙。频率下降。功耗下滑至 210w 附近。温度继续维持 95度。
对比之下。同散热器压制功耗在 230w 附近的 12900k。温度大约在 88 度左右。可以看见积热问题仍旧存在。并且由于功耗更高。似乎更加严重了一点。
注:此测试均为开放式平台测试结果
由于当前的 BIOS 不支持功耗细微调节。仅有 65/105/170w 三档选择。这里我们使用频率控制的方式测试功耗。
注:红色的点为 Auto 频率下初始测试时 16C 的综合频率。
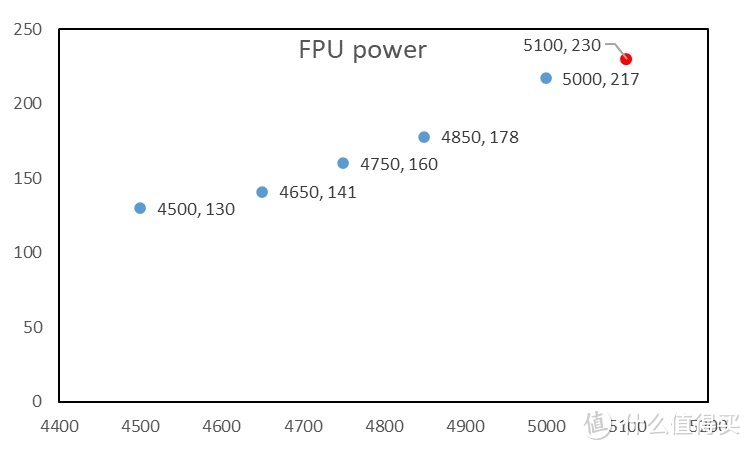
可以看见。从 45x 到 51x 左右。大约提升 13% 性能。功耗接近翻倍。为了些许的极限频率大幅度提升功耗还是有些得不偿失。这个测试证明。N5 制程的 Zen 4 在中高频率下拥有极好的能效比。对比 Zen 3 产 品。其 230W 时才可以达到大约 16C 4.4-4.5 Ghz 的情况。而 Zen 4 在 Auto 电压下只需要 130w 即可实现。这证明 AMD 在发布会所说的低功耗能效表现基本属实。
另:在 FPU 测试中。使用 AVX2 与 512 的测试功耗几乎完全一致。
总结
时隔两年之后。AMD 推出了他们的全新产品 Zen 4。作为相对来说保守改进&更换制程的产品。Zen 4 的表现已然相当优异。已然将对手的旗舰产品 12900K 从单/多线程均甩于马后。就连 Gaming 也做到了互有胜负的地步。
如果说。让我们给 Zen 4 产品一个评价。我想用几近完美这个词来形容再合适不过。虽然他仍旧有着些许的小问题。但在怪兽级的性能以及不错的能效面前。仍旧无伤大雅。
随着 AMD 新品的推出。双方在桌面级 CPU 市场的竞争也趋近于白热化的阶段。9 月 28 日的 00:20 分。也就是后天。删了我们上一份测评的蓝色巨人也将推出他们的 13 代新品。用于与 Ryzen 7000 系列竞争。不论本世代最终鹿死谁手。谁又将成为本世代的单线程/多线程性能之王。我想这都应当都是近十年来半导体发展最好的时代。当然也是对于我们消费者来说最有利的时代。(当然关注我们比较长时间的朋友心里大概已经有答案了)
只有激烈的竞争才能避免挤牙膏式提升再度出现。也才会有不断的进步。也才能避免厂商不过脑子的定价出现。不论什么领域均不外如是。
让我们暂时抛却矿潮的阴霾。迎接马上到来的 CPU 与 GPU 的新品大战。未来。很快就来了。(不过皮衣刀客黄奸商的 GPU。我想我们就不一定能提前弄到为大家带来测评了。)
测试后的一些碎碎念:
由于给我们的 7950X 测试时间只有不到一周。因此测试的流程赶的非常紧。也没有更多的时间深入架构内部使用各种工具来进行测试。不得不说有些遗憾。
在测完了 Ryzen R9 7950X 之后。其实还是有蛮多感慨想发的。作为一匹好马。Zen 4 最终还是没有匹配上它的好鞍。IOD+IF 的带宽限制让这个产品在全能性上顿时打了折扣。我不知道这是不是有意为之。因为在 Zen4 对应的 Server 平台 Genoa 上我们并没有见到这种问题。这个问题对于一些要做蛋白模拟等科学计算方向的用户来说就会面临着抉择问题。
第二个问题是多线程的频率/功耗限制设置的过于激进了一些。很多时候为了那最后的 5-10% 频率。功耗大幅暴增上去之后。对于 TSMC N5 制程的产品来说还是太热了一些。可以说 Auto 状态下的风冷已经几乎没有用武之地可言。当然可能还是为了跟对方的新品竞争吧。不过个人感觉还是有些考量上的问题存在。如果功耗限制在 170-180w 这个水平我觉得会比现在来的更好。因为这个功耗下。水冷可以不撞温度墙。但多线程性能只会损失 3-5% 设置更小。
第三个问题其实宣发与市场的问题。实际上。在我们私下的测试里。AMD 这个平台内存频率越低。在
显卡
部分场景的领先优势反而相对看起来会好看(对比 12900K)。我们不知道为什么 AMD 的 Marketing 选择了 6000 CL30-38 作为 ref 平台测试数据。并且让媒体们参考。要知道这个频率也不是每个 Ryzen 7000 CPU+ 平台都能稳定跑上的。所以这个表现让我感觉就是。市场部实际上是不清楚自家产品性质的。这种割裂感让我有些不知道该怎么吐槽。跟隔壁蓝厂五五开吧。另一个问题就是评测发布时间的问题。只有显卡
部分“值得信赖”的媒体被允许在 9/26 发布。其他媒体则在 9/27 晚上 21:00 后才能发布 review。这种中国区区别对待的方式我觉得也太蠢了一点。至于为什么 AMD 会如此安排。这里不做更多评价。你们自己理解吧。(当然。我们例外~~~)
碎碎念的最后。献给说我是 A 黑、无实物评测、云评测的 A 炮:


我自费购买的 AMD CPU 从 Trinity 开始到 Raphael 不等。已经有很多颗并用作收藏用途。图中
显卡
部分的 CPU 均在发售前通过特殊渠道购入。价格自然也比零售要高得多。至于我秀这些意义是什么。你们可以好好消化一下。吹一个厂商并不会让你手中购买的 CPU 性能提升 50%。如果你是真的喜欢 AMD。那你应当理性的面对它产品的优缺点。理性购买。而不是不带脑子的去吹并试图用某些素质低下的方式来证明你是对的。错误的市场反馈只会让厂商下达错误的方向。企业只会慢慢走向低谷。因为这事吃过亏的企业已经不在少数。只有销量的下降。才会让厂商意识到问题。从而改进这些问题。作为消费者的我们才能用上更优秀、更便宜的产品。
最后我想借用其他 up 的一句话送给这些“精神股东”和“职业 I/A/NV 炮”:一个垃圾。是没有办法靠着市场宣发的文案来改变它的本质。譬如 Rocket lake 和 A380。(并非指 Zen4。而是单纯的阐述观点。请勿对号入座。想多了就是你自己的问题)
(我针对是那些完全不讲道理。还有喜欢扭曲他人意思的那几位。理智粉丝切勿对号入座)
(其中 CPU 均来自海外资源。也有不少中国大陆未上市的产品。所以就不秀完整的啦)
本文的最后。也感谢每一位读者对本评测的阅读。如有不对。劳烦指正。如有不足。敬请谅解。
(所有测试数据均由 OneRaichu 与 ECSM_Official 测试。仅基于测试平台以及对应条件。如有不同。敬请指正。数据均有多次重复测试。我们非常欢迎和谐的讨论。如果你对我们的数据有质疑。还请提供相同平台的数据。以便我们更快的查找问题。)
作者声明本文无利益相关。欢迎值友理性交流。和谐讨论~
其他人还看了
「amd」RTX40的对手来了!AMDRDNA3显卡发布会官宣
即使是电脑小白也能选好游戏本,认准AMD超威卓越平台,畅玩3A大作!附游戏本
英伟达RTX40系列移动版显卡型号曝光,搭载AD103~AD107GPU
 打赏给作者
打赏给作者
郑重声明:本文“它很接近完美了,AMDR97950X全面评测”,https://nmgjrty.com/diannaopj_610167.html内容,由热心市民描边怪提供发布,请自行判断内容优劣。
上一篇:¥599下山蓝宝石白金RX5600XT带灯矿卡,对标RTX2060?拆风扇清灰测试验票送上
下一篇:多核性能的王者,单核也很强

- 全部评论(0)

-
 千元级小钢炮,畅爽游戏兼顾生产力,华硕VG249Q1A
千元级小钢炮,畅爽游戏兼顾生产力,华硕VG249Q1A -
 男朋友说用这个显示器打游戏好爽!
男朋友说用这个显示器打游戏好爽! -
 小米显示器,性价比还是挺高的
小米显示器,性价比还是挺高的 -
 自媒体最佳拍档,这块飞利浦高清显示器我不信你不心动!
自媒体最佳拍档,这块飞利浦高清显示器我不信你不心动! -
 告别平庸的硬盘底座!OIRCO这款“集装箱”,速度快玩法超多
告别平庸的硬盘底座!OIRCO这款“集装箱”,速度快玩法超多 -
 W4K显示器
W4K显示器 -
 朗科(Netac)NV70001TPCIe40SSD固态硬盘测试
朗科(Netac)NV70001TPCIe40SSD固态硬盘测试 -
 Linus考虑让Linux内核放弃支持英特尔80486处理器
Linus考虑让Linux内核放弃支持英特尔80486处理器 -
 13代i7暴打12代i9!憋屈太久了,牙膏厂疯起来真的挺吓人
13代i7暴打12代i9!憋屈太久了,牙膏厂疯起来真的挺吓人 -
 超高性价比的选择,锐可余音“夏至”三件套之CX5电竞声卡体验
超高性价比的选择,锐可余音“夏至”三件套之CX5电竞声卡体验 -
 225元的105寸一线通便携屏SurfaceGO2同款屏幕
225元的105寸一线通便携屏SurfaceGO2同款屏幕 -
 矿难确定不当回开扎古的真男人么
矿难确定不当回开扎古的真男人么 -
 闲置固态硬盘的完美解决方案!奥睿科USB40固态硬盘盒实测分享
闲置固态硬盘的完美解决方案!奥睿科USB40固态硬盘盒实测分享 -
 华硕推出新一代ROGRyuoIII240/360ARGB“龙王”水冷散热器1799元起
华硕推出新一代ROGRyuoIII240/360ARGB“龙王”水冷散热器1799元起 -
 秒懂1U、2U、4U服务器和42U机柜
秒懂1U、2U、4U服务器和42U机柜 -
 2022年了,我才开始用先马趣造
2022年了,我才开始用先马趣造
最新更新
- 千元级小钢炮,畅爽游戏兼顾生产力,华
- 男朋友说用这个显示器打游戏好爽!
- 小米显示器,性价比还是挺高的
- 自媒体最佳拍档,这块飞利浦高清显示器
- 告别平庸的硬盘底座!OIRCO这款“集装箱
- W4K显示器
- 朗科(Netac)NV70001TPCIe40SSD固态硬盘测试
- Linus考虑让Linux内核放弃支持英特尔80486处
- 13代i7暴打12代i9!憋屈太久了,牙膏厂疯
- 超高性价比的选择,锐可余音“夏至”三
- 225元的105寸一线通便携屏SurfaceGO2同款屏幕
- 矿难确定不当回开扎古的真男人么
- 闲置固态硬盘的完美解决方案!奥睿科
- 华硕推出新一代ROGRyuoIII240/360ARGB“龙王”
- 秒懂1U、2U、4U服务器和42U机柜
推荐阅读
- 矿难确定不当回开扎古的真男人么
- 「英伟达」不止是游戏党,他们才是被英伟达坑怕的人。
- 「amd」RTX40的对手来了!AMDRDNA3显卡发布会官宣
- 消息称英伟达将推RTX4090移动版:基于次旗舰GPUAD103
- AMDR77700处理器爆料:8核规格,65W功耗
- 海外网友在Newegg购买RTX4090显卡,拆开包装发现仅有两块配重块
- EVGA宣布不生产显卡后,其GPU超频软件更新支持RTX4090
- AMD新一代旗舰笔记本GPU爆料:RX7900M将达到RX6950XT桌面显卡性能
- 海鲜市场捡漏“真香”?9000元预算纯白12代风冷主机达成分享
- 华硕率先公布自家RTX3060TiG6X非公卡
- 是不是矿渣全靠猜,那就入个比较保险的型号吧,保险矿卡
- 极速尝鲜,7000系锐龙新座驾技嘉X670AORUSELITEAX主板
猜你喜欢
- [机箱]ITX装机初体验
- [机箱]机箱界的铝厂,支持240水冷与长显卡的乔思伯V8ITX机箱装机点评
- [机箱]安钛克驱逐者DF600FLUX
- [机箱]Thermaltake发布Divider300TG机箱
- [机箱]Zen3架构基础款单核锤爆10900K?AMD锐龙55600X评测
- [机箱]也许是最小MATX主机的完美走线
- [机箱]30系列已到,机电有升级的必要吗?
- [机箱]女王的ITX新电脑上篇之复刻lousuITX机箱
- [机箱]最小ATX乔思伯RM2及风道改造
- [机箱]bequiet!德商必酷发布PureBase500DX机箱
- [机箱]修理机箱耳机插孔
- [机箱]大容积的小钢炮
- [机箱]乔思伯A4水冷机箱+R53600RX5700升级装机
- [机箱]TtLevel20GT全塔机箱开封解析
- [机箱]Dell戴尔小机箱内部升级记



