 大家电
大家电  厨卫家电
厨卫家电  生活电器
生活电器  健康电器
健康电器  数码产品
数码产品  五金电器
五金电器  生活用品
生活用品  好物推荐
好物推荐  网站首页
网站首页13代VSZen4VS12代VSZen3最全对比测试看完就知道该买那个了
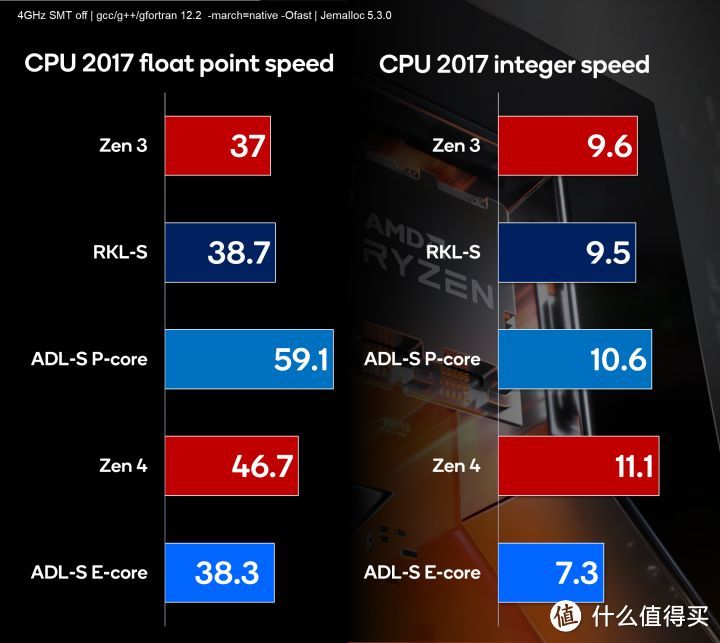
在上月的Zen 4首发测试。Zen 4虽然同频浮点性能没有赶上12代(这样直接导致跑分吃亏。特别是CPU-Z)。但整数性能强悍(实用性能好)。再凭借频率的优势。整体性能还是胜过intel 12代。而现在是intel的回合了。intel已于9月28日发布了13代Raptor Lake。相比Zen 4仅仅晚一天。但上月的那次仅仅是Paper Launch。正式评测解禁和发售。还是要等到10月20日。好。现在就废话不多说。让我们来看看13代Raptor Lake是否能够击败Zen 4再次夺回性能的领先地位吧。
本文内容包括并不仅限于:
13代处理器规格是怎么样的。和12代有什么变化?
13代处理器底层架构和性能如何?
Z790平台和Z690有什么区别。高端Z790是如何形态?
13代处理器功耗温度怎么样。需要怎么样的散热器?
13代+Z790相比Z690有什么变化?
13代的生产力和日常使用性能打得过Zen 4不?
13代游戏性能如何?之前的处理器搭配RTX 4090真的有瓶颈么?
13代值得买么。怎么搭配才合理?
Raptor Lake规格简析

Raptor Lake 13首发13600K/13700K/13900K相比12代P-core对应型号核心数量不变。i5/7各增加了4个Ecore,i9更是一股脑增加8个 E-core。再大幅拉升频率。这就是13代强大的起源。至于上面标注的频率是全核频率。具体的频率和构架问题我会在后面部分具体再说。‘
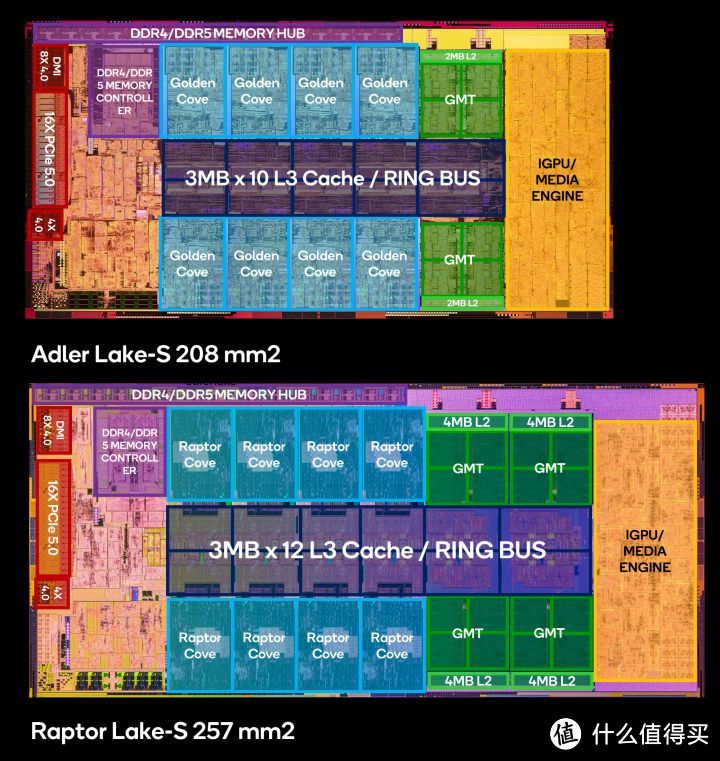
上图是我绘制的Raptor Lake-S的芯片布局。其基本延续了Alder Lake-S结构布局。在Alder Lake-S 8个E-core旁边再加了8个E-core。再就是L2缓存规模翻翻。中间深蓝色是36MB L3缓存和环形总线。右边黄色是核心显卡和解码器。左边是红色部分依次是是到PCH的DMI PCIe 4.0 8x、到GPU PCIe 5.0 16x+M.2 PCIe 4.0 4x。左上紫色的是DDR4+DDR5内存控制器+接口。13代依然同时支持DDR4和DDR5。
很多人会吐槽。加E-core有什么用。只是跑分好看。要理解为什么要加E-core。首先要明白E-core的设计逻辑:GMT的E-core核心4个面积才比一个1个P-core大核心稍大。但在多线程应用中。二个就可以顶上一个P-core大核心的性能还绰绰有余。但其核心面积(成本)差不多4个E-Core才比一个P-core大一点。因此E-core是一个提高跑分性价比很高的方法。当然增加E-core不仅是为了跑分好看。实际跑分和生产力差不多。E-core也确确实实提升了z真实的多线程生产力的性能。
工艺的问题
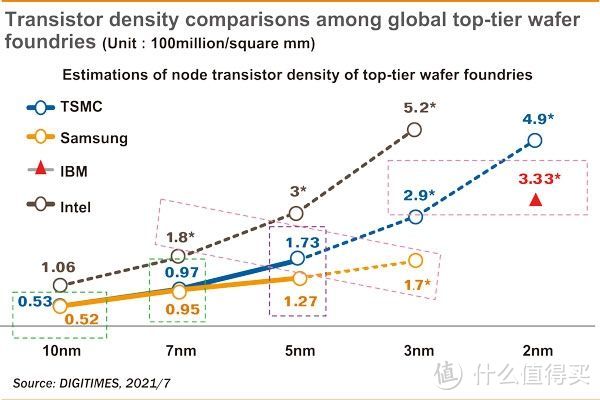
intel 13代还是继续沿用12代intel 7工艺。名为7实为10。取名10更多是市场宣传方面的话术。不过这样做首先是台积电和三星不讲武德虚表工艺线宽。intel 10nm工艺密度就有台积电/三星7nm的水平级别(参见上图的每mm2百万晶体管密度)。不能就自己老实人吃闷亏。当然即使如此。还是跟Zen 4采用的TSMC 5nm有巨大的差距。
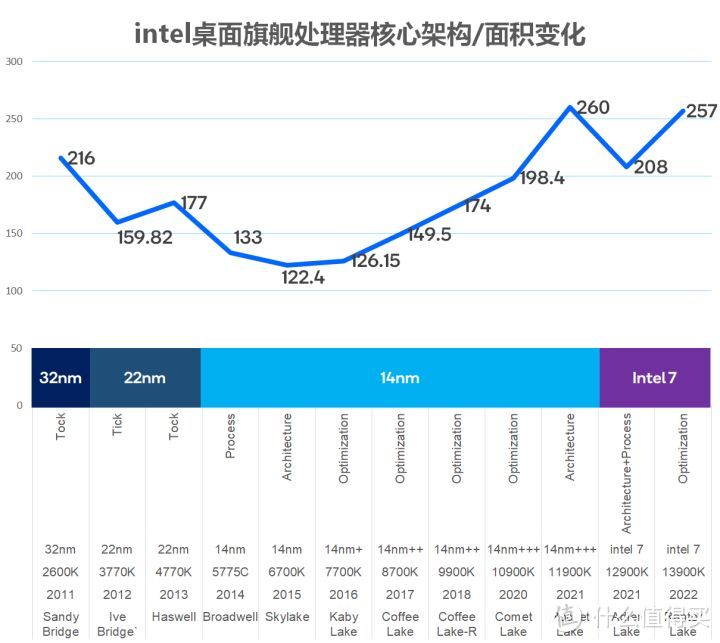
在工艺线宽和架构在不大变的情况下。13代旗舰的8P+16E的规格相比12代8P+8E。面积从208mm2增加到了257mm2。除了增加8个E-core和L2缓存。Raptor Lake为了解决散热问题。应该还故意降低布线密度来提升频率性能。降低功率密度。因此257mm2的核心面积并不小。十分接近11代Rocket Lake 260mm2的历史高位。

但名为7实为10的intel 7作为成熟工艺。良品率应该很高。要不也不敢做780mm2 34核心 MCC SPR这样比H100还大的怪物。所以Raptor Lake 257mm2的良品率和成本对于intel应该还是很舒服的。
测试平台和说明
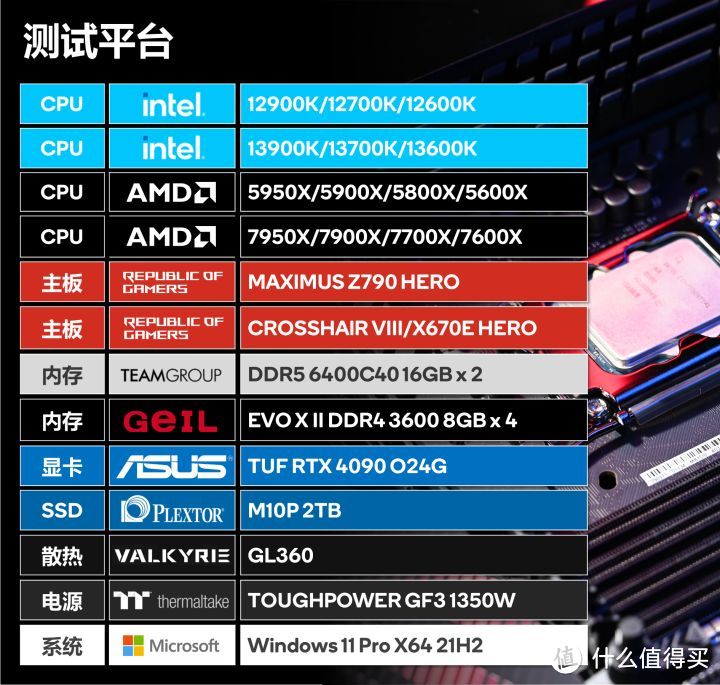
Zen 3在有说明PBO的情况下。是开启PBO进行测试:Max CPU Boost Clock Override设置的+100。AI Core Curve Optimizer Magnitude统一设置的-15到-20。没有时间依据单个核心进行微调。底层测试运行在3600。其他性能测试运行在3800 FCLK 1900。
intel 12/13代SA设置1.15V IVR 1.48V MCV 1.38V。防掉压为默认。内存设置在DDR5 6400 40-40-40-80。
Zen 4平台在没有特别提及FCLK是2000。内存运行在6000 40-40-40-80。默认PBO设置。
测试显卡驱动版本为RTX 4090的Beta驱动521.90。均开启Resize BAR。其他为默认设置。
非3A游戏部分其实大部分我在8-9月使用ROG STRIX Z690-E GAMING测试。后来在更换Z790 HERO后又进行了部分数据验证。
Raptor Lake:增强版 Alder Lake
十三代酷睿处理器沿用了上一代的 P-Core + E-Core 同质异构架构。制程是同属于 Intel 7 但是做了一点加强。被称作 Intel 7 Ultra。采用了 Intel 的第三代 SuperFin 晶体管结构。能实现更高的电压-频率包线。频率和之前的工艺相比高接近 1Ghz。
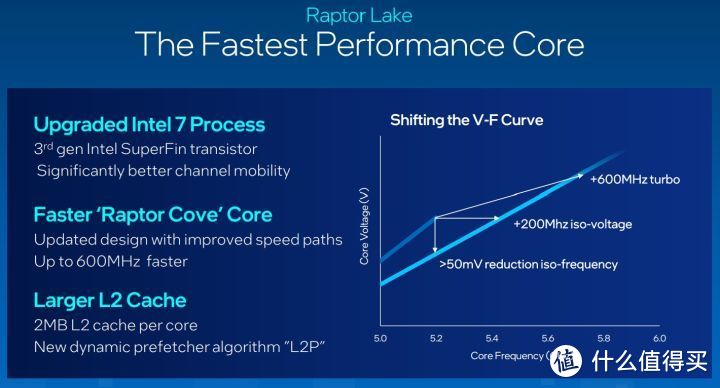
芯片的代号为 Raptor Lake(简称 RPL)。其中 P-Core 的微架构是 Raptor Cove。E-Core 是 Gracemont 增强版。
Raptor Cove 和 Alder Lake 里的 Golden Cove 基本上就是一回事。主要改变的地方是频率上限和 Cache 方面:
Core i9 13900K 的全核加速模式下可以达到 5.5 GHz。单核加速模式下可以摸一下 5.8 GHz(Tcase 温度需要小于或者等于 70 摄氏度);
在 Cache 方面。Raptor Cove 的 L2 Cache 容量从 1.25 MiB 提升到了 2 MiB。P-Core 和 E-Core 共享的 L3 Cache 有所增加。从 30 MiB 提升到 36 MiB。
除此以外。Raptor Cove 的 L2 Cache 引入了名为 L2P 的预快取技术。能根据工作负载动态调整预取器的行为;对于 L3 Cache。则是引入了名为 Dynamic INI 的动态包含/非包含算法。DINI 会尝试根据运行的内存行为在 L3 包含/非包含策略之间实时切换。按照 Intel 的说法。光是在高速缓存上的改进。能让 Raptor Cove 的性能最多提升高达 16%。当然。具体幅度取决于实际的工作负载。
RPL 的 Gracemont 也是类似的情况。微架构基本上和 Alder Lake(简称 ADL)中的 Gracemont 一样。所不同的主要地方有三点:
L2 Cache 的容量从 2 MIB 增加到了 4 MiB;
频率可以从之前的 3.7GHz 提升到了 4.3GHz(Core i9);
内核规模增加了一倍。例如 Core i9 13900K 的 E-core 数量是 16 个。Core i7 13700K 的 E-core 数量是 8 个。
Raptor Lake 无法再像Alder Lake 那样透过关闭 E-Core 的方式来启用 P-Core 的 AVX512 指令支持。但是除此以外。从编程人员的角度来看。Raptor Lake 和 Alder Lake 都是一样的东西。gcc 12.2 编译器为其提供的 native 架构旗标也是 alderlake:

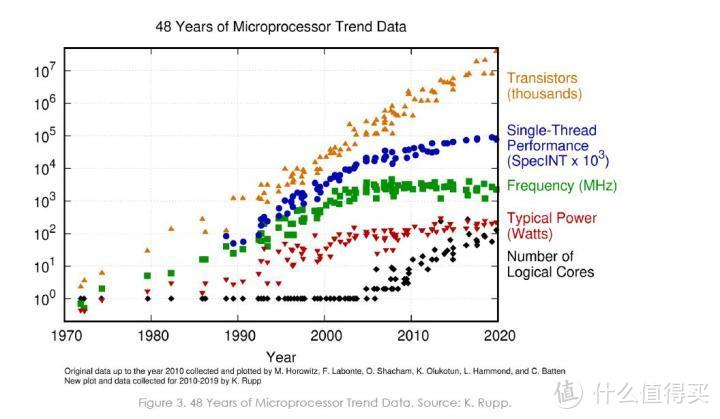
Raptor Lake 以及稍早前 AMD 发布的 Zen4 都有一个共同的之处。那就是都将拉升频率作为重要的性能提升手段。
在 2000 年 Athlon 首次突破 1GHz 大关后。x86 处理器在一段时间里都维持着比较可观的增长速度。例如 2001 年 Intel Pentium 4 首次实现 2GHz。2003 年 Pentium 4 实现 3.06GHz。
当然。之后 NetBurst 实现高频所带来的副作用——高耗电、低 IPC 问题也日益凸显。频率拉升的努力似乎也快到了尽头。如果按照当初 Intel 设定的 NetBurst目标。应该会在 2005 年达到 10GHz。但是这个目标即使在现在也是遥不可及。到了 2004 年。Pentium 4 570J 也只是爬到了 3.8GHz。传闻中的 Pentium 4 580 4GHz 从未发布。
Intel 本应该在 2005 年推出代号 Tejas 的 Pentium 5 处理器。但是由于产品在散热上存在重大挑战。已经进入整机厂商测试阶段的 Tejas 戛然而止。
最终 Intel 回归到了强调 IPC 的 Conroe 架构上。并在此基础上发展到如今的 Raptor Lake。
x86 阵营冲击高频失败后。RISC 阵营并未停止这方面的步伐。其中最让人振奋人心的自然是 IBM 的 Power 6 处理器。在 2007 年实现了 4.7GHz。尽管 IBM宣称其内部测试原型已经实现了 6GHz。但是该处理器最后也只是做到了 5GHz(2008 年的 P595)。
之后。冲击更高频率的表演依然由 IBM 领衔。2010 年的 z196 首次超过了 5GHz。达到 5.2GHz。2012 年的 z12 实现了 5.5 GHz。这个 CPU 频率纪录维持了 9 年多。直到今年被 x86 阵营的 Zen4 和 Raptor Lake 冲破。
既然拉升频率是有效的性能提升手段。那么过去近 10 年里 x86 的频率增长那么缓慢呢?究其原因主要是随着晶体管尺寸的缩小。电路中的漏电流也会随之增长。更高的漏电流意味着芯片即使实在闲置状态下也会产生更大的耗电。
为了避免时钟频率增加引起的热失控。架构师选择了多核架构。在单个芯片上集成两个、四个或更多 CPU 内核。这些内核可以在较低的时钟频率下运行。共享各种片上资源。从而消耗更少的功率。正是在这样的设计指导下。x86 CPU 在一段时间里陷入了漫长的频率滞涨期。
Zen4 和 RaptorLake 的出现让 x86 阵营再现了久违的频率大幅提升。随之而来的问题就是在大幅度拉升频率下。谁的性能/能耗比更出色相信也是大家都感兴趣的问题。我会在本文中提供相关的实测数据供大家参考。
底层性能实测
测试平台说明:
测试基本是在 Linux 下完成。采用 Linux 的原因有几点。首先是可以在纯文本控制台模式下启动。便于我 SSH 执行测试;其次是 Linux 下有较多开源代码便于我修改应用到测试中;
这次涉及到编译的测试都采用 GCC 12.2。最新版本的 GCC 13 提供了 znver4 或者说 Zen4 的支持。在 -march=znver4 或者 -march=native 的时候实现 avx512 扩展指令支持。但是考虑到并非发行版。可能会存在一些问题。所以留待日后再试。
测试使用的底层测试基本都是汇编代码编写。所以编译器的影响非常小。
AMD AM5 处理器使用的内存设定为 DDR5-6000。Intel LGA 1700 处理器内存设定为 DDR6-6400。
访存带宽及耗电测试
内存带宽测试工具来自 Clam Chowder 的 MemoryBandwidth。这是一个开源工具。有独立的耗电代号测试分支。但是这个分支我看到的时候只有 Intel 的 RAPL MSR 信息获取代码。缺乏 AMD 能源值获取的代码。
Intel 在多年前就提供了名为 RAPL 的电力监控界面。让操作系统或者程序透过读取某几个 MSR 的数值。经过简单换算后就能达到焦耳值。结合运行时间。就能得出 CPU 不同供电平面的功率数据。AMD 从 Zen 也开始跟进。将原来的 APM 电源监控方式更改为 RAPL。而且 AMD 的值是 64 位的。不需要像 Intel 32 位值那样在采样一段时间后需要绕回(warp around)计算。
为此。我对 MemoryBandwidth 源代码进行了简单的修改。透过 Linux sysfs 界面获取 RAPL 焦耳值。AMD 和 Intel 目前都提供了封装(Package)域和内核(Core)域的耗电数据。我在这里取的是 Package 域的数据。
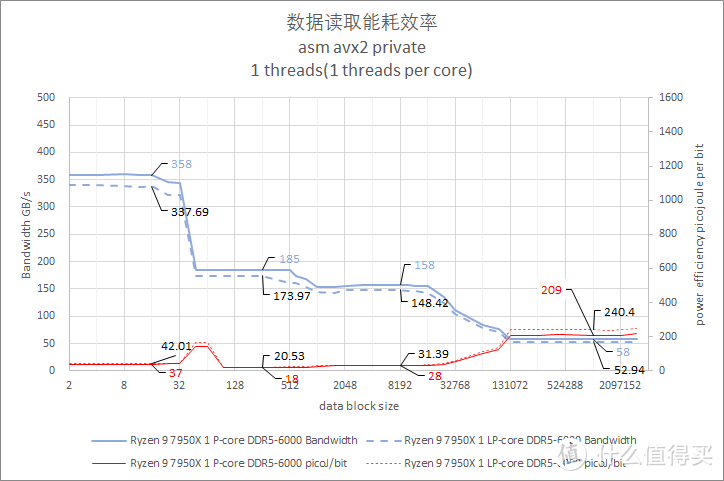
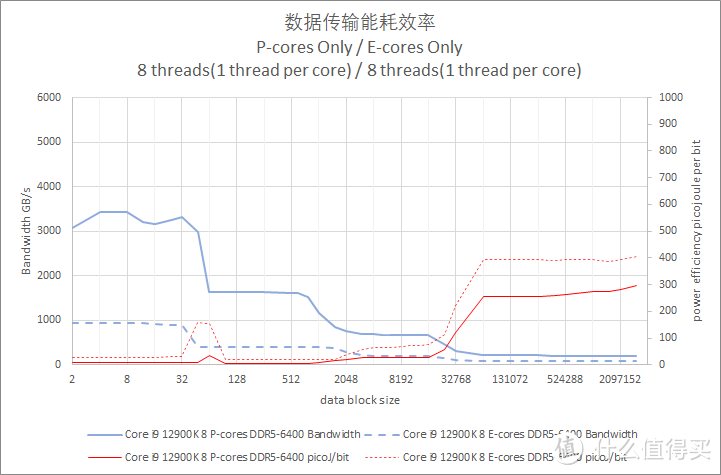
图表中的实线代表 p-core。虚线表示 e-core。
默频单线程读取带宽对比
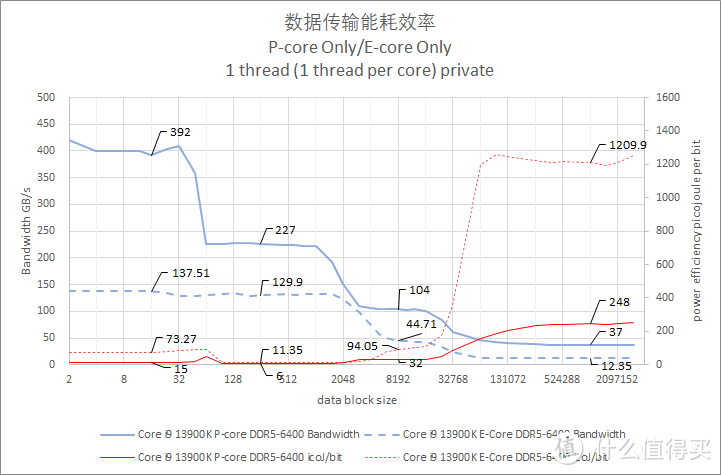
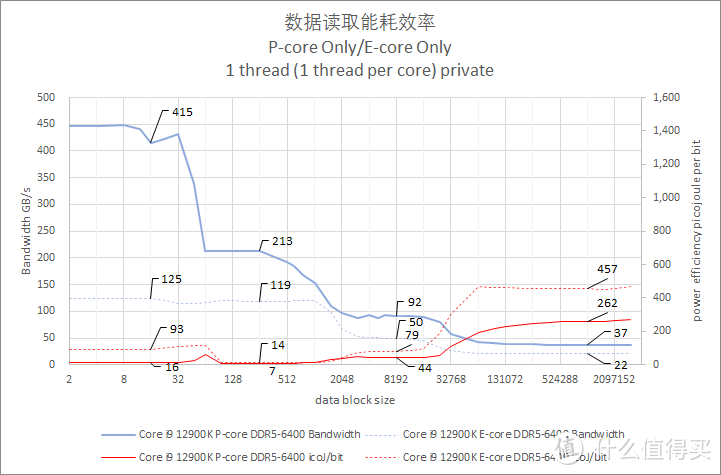
数据是在出厂默认频率规格下测试录得的。电源管理模式已经设置为性能模式。
单线程模式下。Core i9 13900K 的 L1 D-Cache 表现出了比 Ryzen 9 7970X 高频核高 9% 的带宽。并且表现出了比 Ryzen 9 7970X 低大约 59% 的每 bit 焦耳能耗值。
Core i9 13900K Gracemont 增强版方面的表现则比较一般。而且 L1 D-Cache 和 L2 Cache 之间的内存带宽差别非常小。L1 D-Cache 段的每 bit 焦耳值要比 Ryzen 9 7970X 低频核高出大约 74%。
在内存访问阶段(>36 MiB L3 cache 之后的区间)。Ryzen 9 7970X 高频核的内存读取带宽大约是每秒 58GiB/s。而 Core i9 13900K P-core 是每秒大约 37GiB/s。Core i9 13900K P-core 比 Ryzen 9 7970X 高频核低大约 36%。
比较有意思的是。Core i9 13900K E-Core L3 Cache 带宽只有 Core i9 12900K E-Core 的 89%。在进入主内存范围后。更是只有后者的一半带宽。大约是 12 GiB/s。相比之下 Ryzen 9 7950X 的低频核内存带宽大约是 51.2GiB/s。E-Core 单核每 bit 耗电值高达 1200pj。大约是 Ryzen 9 7950X 低频核的 5 倍或者 Core i9 12900K E-core 的 2.6 倍。
默频多双线程核读取写入带宽测试
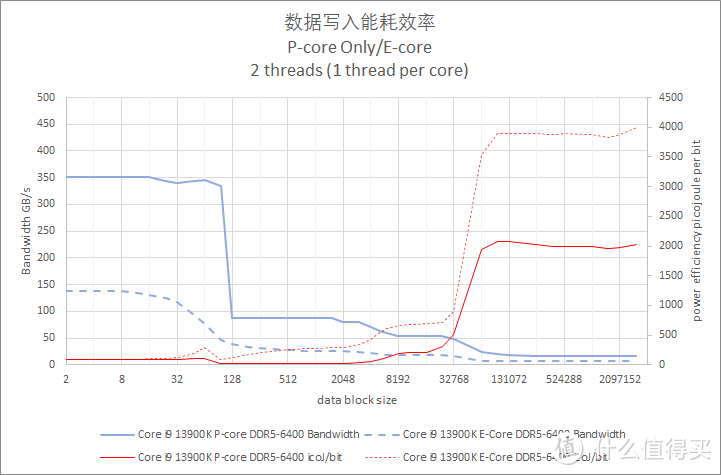
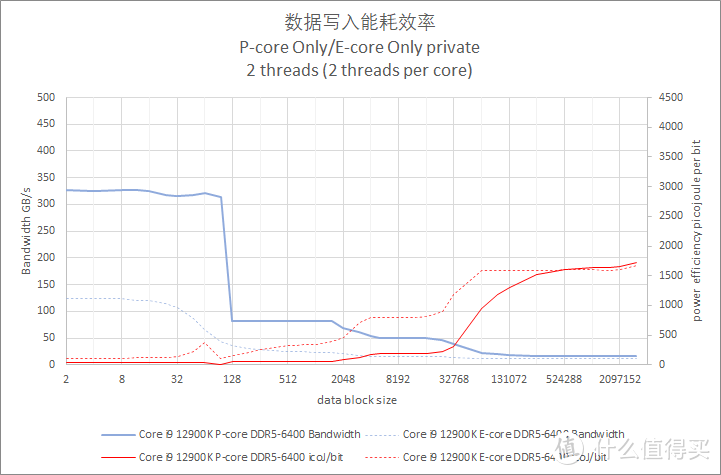
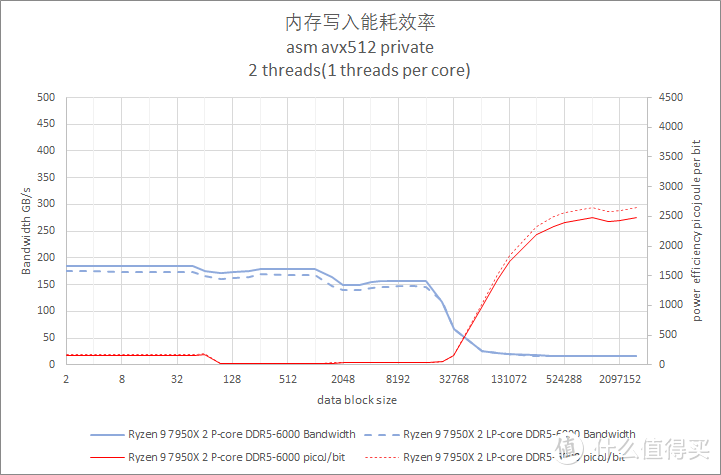
写入测试也是使用 private 模式。以邻近的性能核和能效核各一对进行测试。
从测试结果来看。Core i9 13900K 在 Cache 阶段的写入带宽值最高。但是主内存段的写入带宽三个处理器都差不多。都是 16GiB/s 的水平。其中 Ryzen 9 7950X 要略快一些。
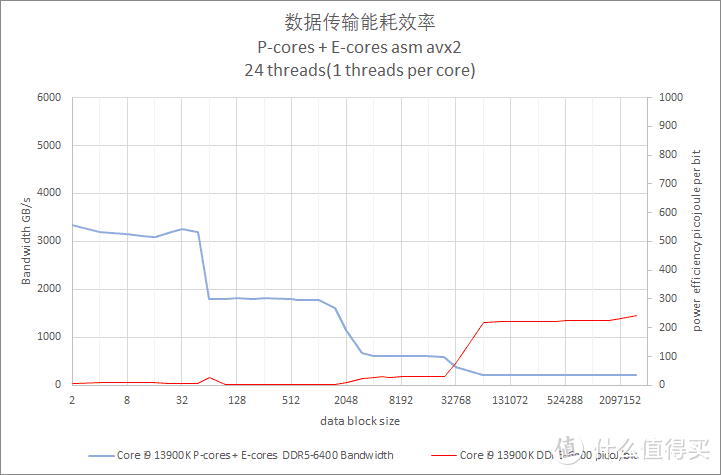
在能耗方面。Core i9 12900K 的 P-core 表现较好。Core i9 12900K P-core 也比较接近。Ryzen 9 7950X 的耗电会再高大约 25%。
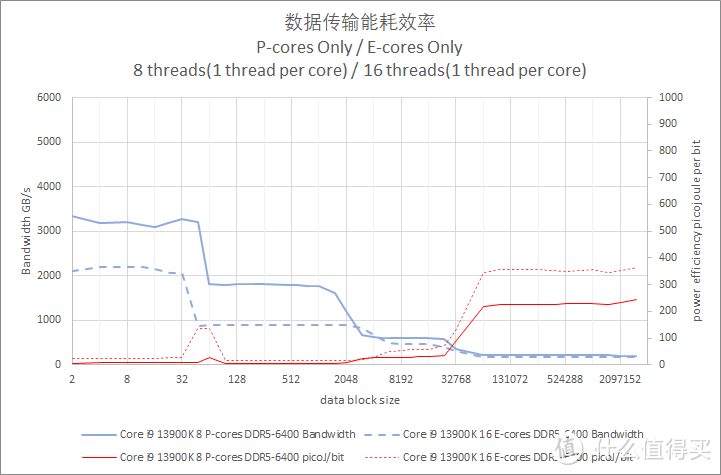
相较之下。Core i9 13900K E-Core 的每 bit 耗电则是比较糟糕。每 bit 焦耳值接近 P-core 的 2.6 倍。
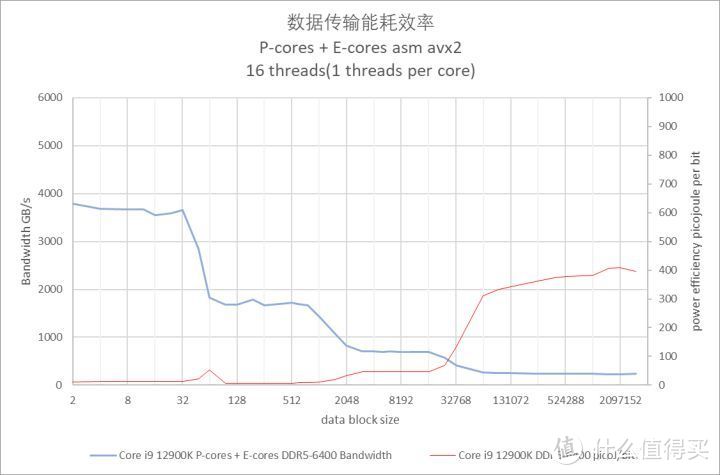
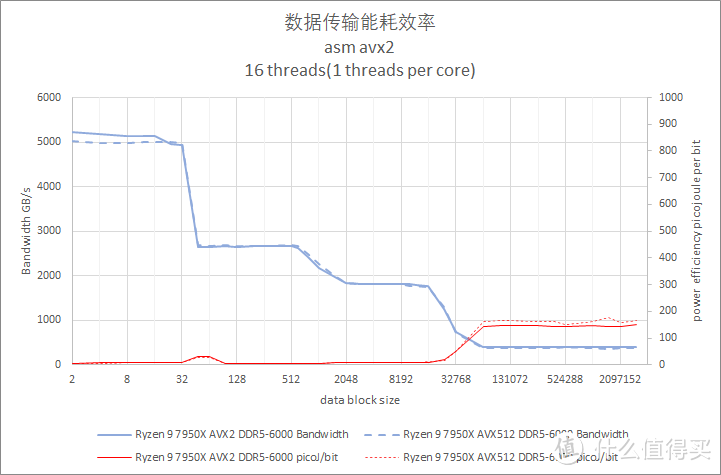
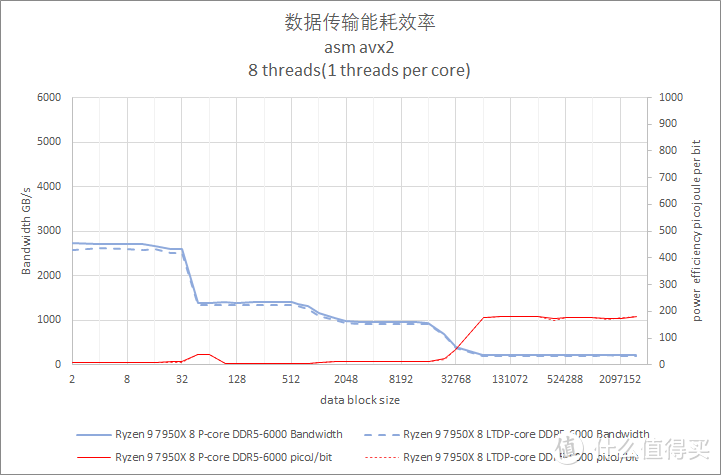
这里提供的多线程内存带宽测试属于共享读取模式。也就是多个线程读取同一个地址。这种模式一般会发生在多个线程要对同一块内存中的数据进行不同的计算。由于 cache 的缘故。跑出来的内存带宽要比理论值高出不少。
每周期访存带宽测试
从探查微架构的角度。我们还希望了解处理器每个周期的访存能力。这个能力涉及到微架构内部的 Load/Store 单元规模以及总线设计。由于处理器的变频或多或少都会干扰采集每周期数据的判断。
举个例子。Ryzen 7 5800X 以默频跑带宽测试的时候。在读取主内存之前或者说读取片上 Cache 数据频率都是 4.7GHz。在读取主内存的时候频率则会提高到 4.8GHz。
由于计算每周期字节的时候需要频率值(或者周期值)。在这个测试中。我将处理器的频率一律固定为 4 GHz。测试出来的内存带宽数据除以固定的处理器频率就能得到处理器每周期的访存能力。
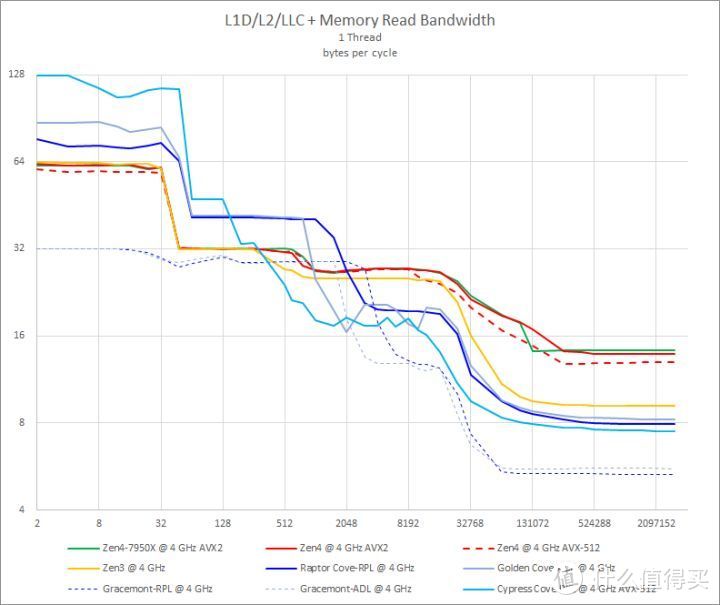
Raptor Cove 的 L1 D-Cache 读取总线带宽略低于 Golden Cove。大约是每周期 76 字节。而 Golden Cove 可以达到每周期 88 字节。都比 Zen4/Zen3 的每周期 62/60 字节高一些。此时 Raptor Cove 相对于竞争对手 Zen4 快 23% 左右。
Gracemont 或者说 E-core 的测试结果除了 Cache 大小差别外。几乎是一样的。
取指带宽测试
前面测试的都是数据带宽。接下来让我们看看 Zen4 的取指或者说指令获取带宽。影响取指带宽的主要因素是 L1 I-Cache、解码器能力、指令并发执行能力以及运行结果写回能力。
以往我都是用 RMMA 来测试取指带宽。但是 RMMA 毕竟是 10 多年前的工具。有些老旧了。所以我这次加入了 Clam Microbenchmark 来实现这个测试。它提供了 4 字节指令(4 NOP)和 8 字节指令(8 NOPs)的取指带宽测试能力:
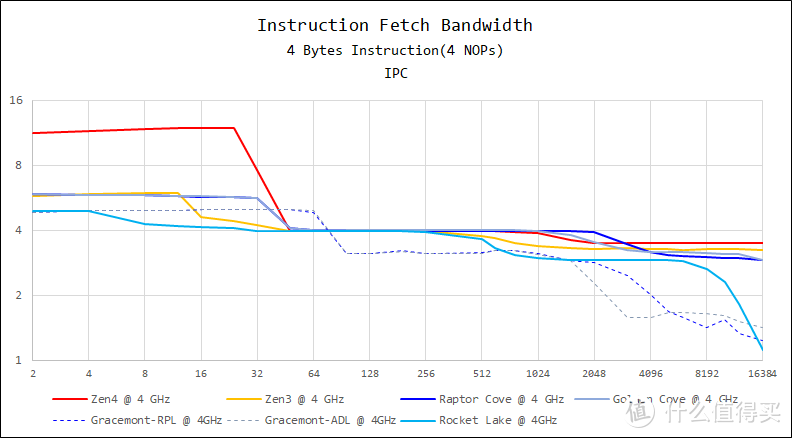
AMD Zen4 的后端会把 nop 指令忽略掉。这样设计的好处是并不影响运算结果。同时可以省略掉后端单元空跑 nop 指令导致的无用耗电。当然。这样的设计会让 Zen4 跑 nop 指令的时候看上去有非常高的吞吐能力。
在 4 NOP 测试中。Raptor Cove 的 L1 指令高速缓存取指带宽和上一代一样。都是每周期 5 bytes。而 Zen4 可以跑到每周期 12 bytes(可维持到 24 KiB)。
为了查看更长、更复杂指令时的情况。这里提供含前缀的 cmp 指令取指带宽测试结果。此时每条指令的长度时 8 个字节。
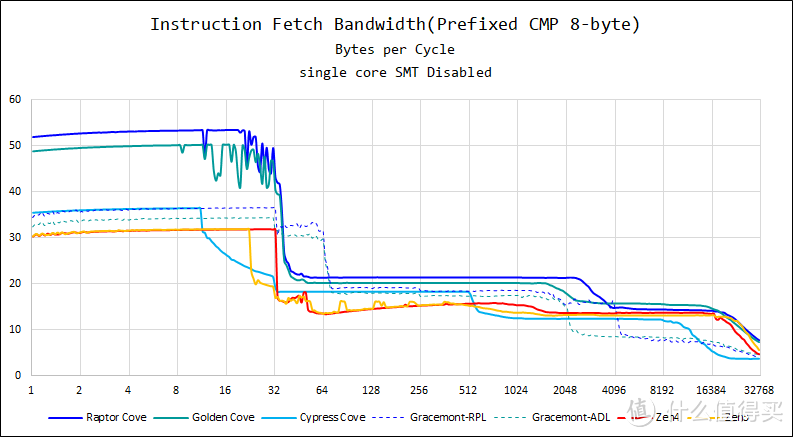
从测试结果来看。Raptor Cove 的最高取指带宽为每周期 53 字节。而 Golden Cove 是每周期 50 字节。Raptor Cove 在这方面是有所提升的。
增强版的 Gracemont 在取指带宽方面也比上一代的 Gracemont 更好。可以达到每周期 36.6 字节。而上一代是每周期 34.4 字节。
流水线深度分析
现代处理器都采用了多级工位设计。大家把这种多级工位设计成为流水线化或者管线化。
流水线深度和处理器频率延伸能力、分支预测失败惩罚有密切关系。
一般来说。流水线工位越细分。各个工位的时间片就越短。处理器的频率看起来越就越高。但是工位越多。分支预测缺失导致的性能损失也就越多。例如 5 级工位的流水线遇到分支预测缺失。可能也就是损失 5 个处理器周期。但是如果是 20 级流水线可能损失的 CPU 周期就会达到 20 个。
现在的内核流水线设计异常复杂。不同指令流向经过的流水线工位数可能是不一样的。
为了探测 Zen4 的流水线深度。我使用了多种代码来测试。
下表中的左侧是以伪代码方式提供分支程序测试片段。以第 7 个测试(Test 6)为例:
Test 6, N= 1, 8 br, MOVZX XOR ; if (c & mask) { REP-N(c^=v[c-256]) } REP-2(c^=v[c-260])
这段伪代码中包含了一个 MOVZX 内存载入操作指令。根据处理器的不同。它可能需要额外的 5 到 6 个周期(可能更少)来执行。在支持乱序执行、乱序 L/S 的处理器中。这个动作占用的流水线工位通常会被掩盖掉。
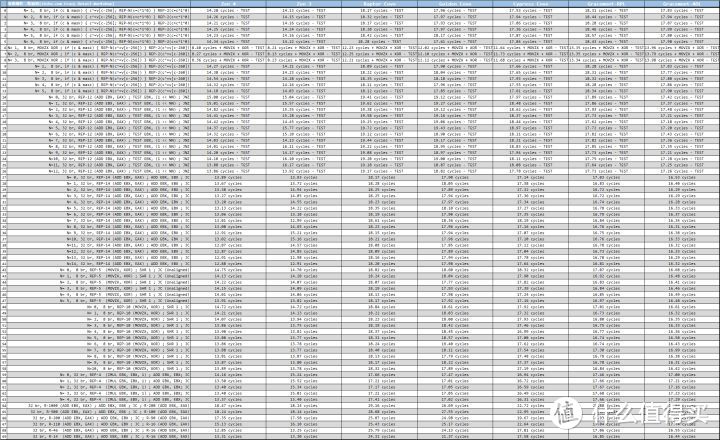
从测试结果来看。Raptor Cove 的分支预测缺失惩罚要比 Golden Cove 更高。最大是编号 69 的测试。惩罚增加了大约 3 个周期。其他的基本落在 0.2 周期以上。从软件角度来看。Raptor Cove 的流水线深度是略有增加的。
相较之下。Zen4 虽然频率比 Zen3 大幅度提升 。但是不少情形下分支预测缺失惩罚甚至有所下降。
分支预测器
分支预测维持流水线充盈的重要性能手段。但是对于现在的长流水线处理器来说。分支预测失败的话对性能惩罚会非常高。因为这意味着运算结果要被抛弃并且流水线要被洗刷。即使是 1% 的命中缺失对性能来说也是非常致命的。当然这也意味着多增加 1% 的命中率收益会非常大。
现在的处理器在内部提供了性能计数器。可以让我们了解处理器运行某个程序消耗的周期数、指令数、分支指令数、分支命中失败指令数等数据。我这里在 Linux 下对 CPU2017 的 intrate 测试包进行了分支预测数据采集。
这次我们使用 SPEC CPU2017 1.18 版进行分支缺失率测试。编译器更新为 GCC 12.2。内存堆分配器Jemalloc 为 5.3.0。编译器的优化参数统一为:
-Ofast -march=x86-64 -mtune=core-avx2 -mfma -mavx -mavx2 -fno-finite-math-only -fno-unsafe-math-optimizations -fcommon
第二行主要是满足 -Ofast 的设置。
众所周知。之前我的 CPU2017 测试都是使用 -march=native。这样的设置能让编译器自动调用 GCC 开发者为不同微架构预置的最佳化编译参数。但是缺点是不同微架构的优化参数可能会有出入。这会导致编译出来的二进制代码有一定甚至较大的出入。在这种情况下做一些分析会出现运行指令差别较大而导致的微架构分析偏差。
所以在这次我选择了 -march=x86-64 -mtune=core-avx2 -mfma -mavx -mavx2 的优化开关。根据我的观察。这个设置得出来的总成绩和 -march=native 非常接近。所以这个优化设置集无论对底层分析还是应用级性能对比。都是可以接受的。
分支预测缺失率
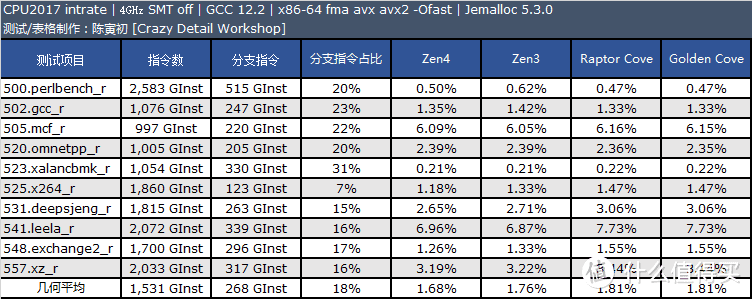
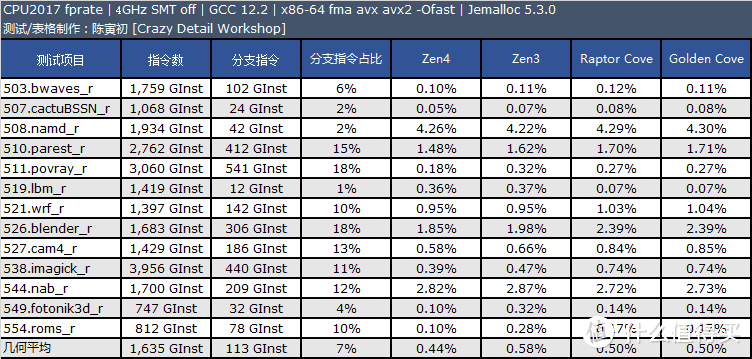
每千条指令的分支预测缺失指令数(MPKI):
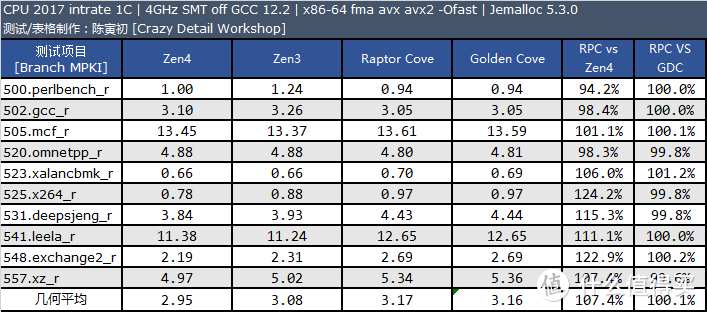
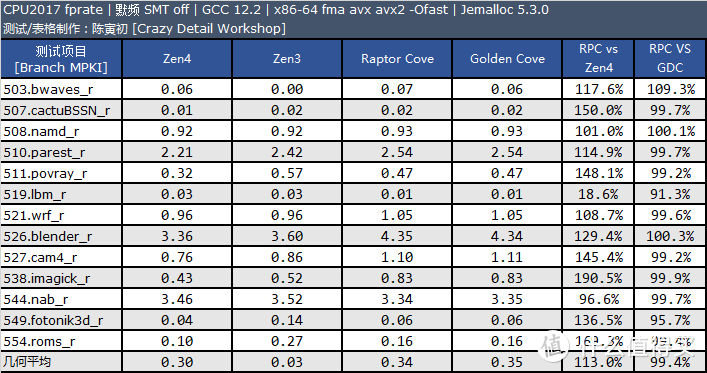
从测试结果来看。Raptor Cove 和 Golden Cove 的分支预测缺失率几乎是一样的。因此我认为两者的分支预测器是没有变化的。和 Zen4 相比 Raptor Cove 仍存在一定差距。
指令窗口测试
由于 AMD Zen4 微架构会在流水线后端阶段将 nop(空操作)指令忽略掉。而传统的 ROB 大小测试手段是使用 nop 指令实现的。这点有点类似 Apple M1 的做法。如果使用 NOP 指令来测试 Zen4 ROB 大小的话。你会看到一条几乎没有起伏、逐渐向上的曲线。
在这里我决定选择混合整数+浮点指令的方式进行指令窗口大小测试(感谢 Travis Downs给我的建议)。这种测试方式通常会比实际的 ROB 略小一点。但是好处是避免了 nop 指令被消除导致无法正确探测 ROB 大小的问题。
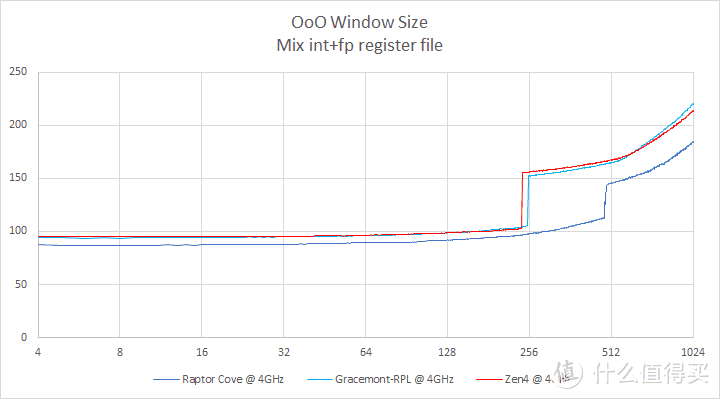
从测试结果来看。Raptor Cove 应该也是 512 条目。而 Zen4 则是 256 条目。因此从程序员角度来看的话。Zen4 的指令窗口大小和 Zen3 是一样的大小。
内核与内核之间的时延
核间时延反映了各个内核数据交换的性能。这个问题随着 Zen1 问世再次在桌面领域引起大家的关注。这次我继续引入该测试。测试结果如下(四方热点图是物理内核之间的时延。条状热点图是内核启用 SMT 后物理线程之间的时延):
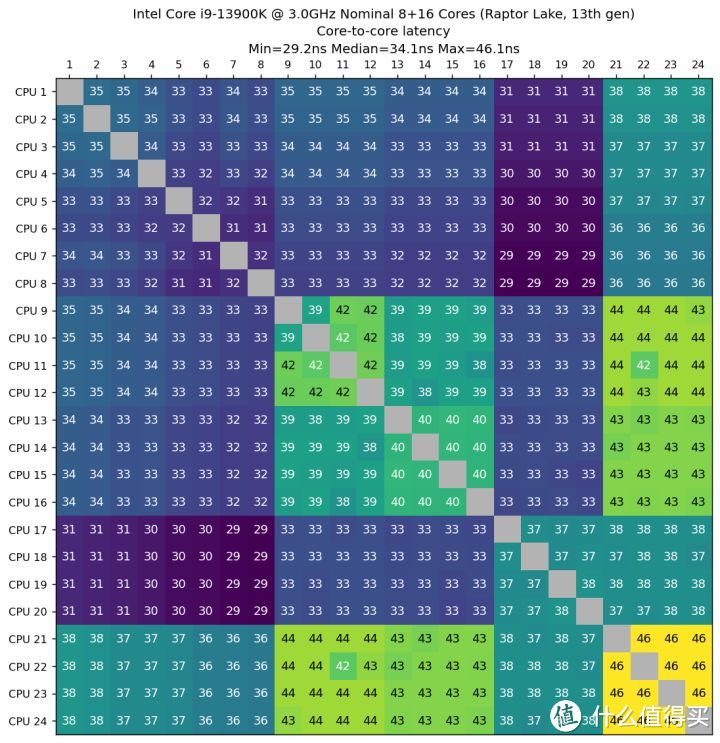
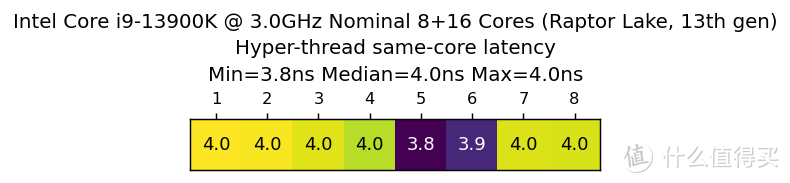
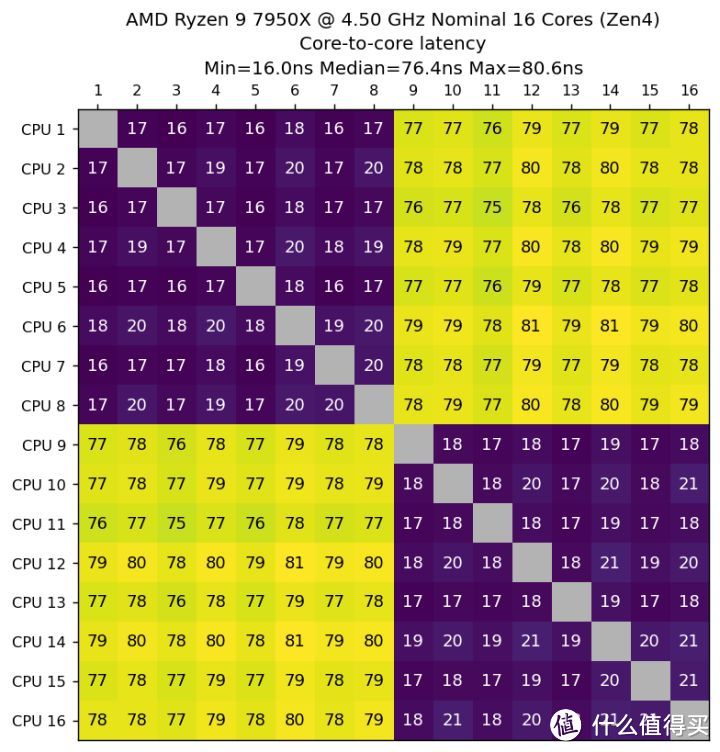

从 Core-to-Core 时延测试结果来看。Core i9 13900K 的最高时延为 46.1 纳秒。发生在 21-24 这组最远端的 E-core 簇。P-core 之间的时延均在 31 纳秒到 35 纳秒。P-core 和 E-core 的最低时延发生在 17-20 这组。时延范围在 29 纳秒到 31 纳秒之间。出现这样的情况估计和环路总线有关。
CPU2017 4GHz 定频测试
CPU 2017 是非盈利机构 SPEC(标准性能评估公司)推出的 CPU 性能评估套件。SPEC 成立于 1998 年。会员包括 Intel、AMD、IBM、DELL、联想、华硕、技嘉等业界大公司。每隔大约 10 年就会推出一版新的 CPU 性能评估套件。CPU 2017 是该机构在 2017 年推出的。是所有处理器、电脑厂商做处理器性能评估的最重要手段之一(如果不是使用上有一定门槛。上面这句话的“之一”是可以省略的)。
SPEC CPU 的特点是由各个机构提供实际应用的源码。它的每一个子项目其实都是源自真实应用修改而来。其修改主要是针对可移植性和遵循的语言标准。例如 x264 的真实版本采用了大量的汇编代码。但是这样的形式不利于移植到不同指令集架构上测试。因此 CPU 2017 中的 x264 采用的是纯 C 语言版本。
和上一版本 CPU 2006 相比。CPU 2017 的代码已经全面更新。虽然依然使用 C/C++ 和 Fortran。但是相对以前的版本来说。已经变成了多语言的大混装。Fortran 语言同时出现在浮点和整数测试集。而非像以往那样只出现在浮点测试集。
CPU 2017 的规则更加严谨。speed 测试集允许使用 OpenMP 多线程处理。主要测试较大数据集和较大访存压力下的单任务多线程性能。而 rate 测试集则只允许单线程。禁止自动并行化。但是允许以多任务的方式跑多个 rate 测试。目的是测试吞吐率。单个 rate 任务的访存压力要比 speed 小很多。
不过 speed 测试集也不是全部项目都支持多线程。只有浮点密集型的 fpspeed 所有项目支持多线程。整数密集型的 intspeed 10 个子项目中只有最后的 657.xz_s(数据压缩)是支持多线程的。
这样的规则让以往 CPU 2006 以及更早版本中常见的编译器自动并行化“优化”手段被禁止使用。减少了测试结果的混乱(测试如果使用了编译器自动并行化后。实际上变成了编译器比拼)。提高了可比性。
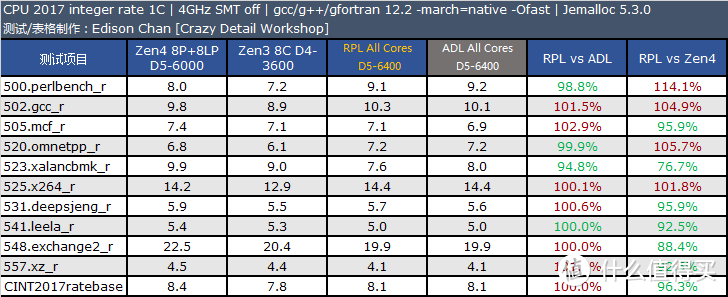
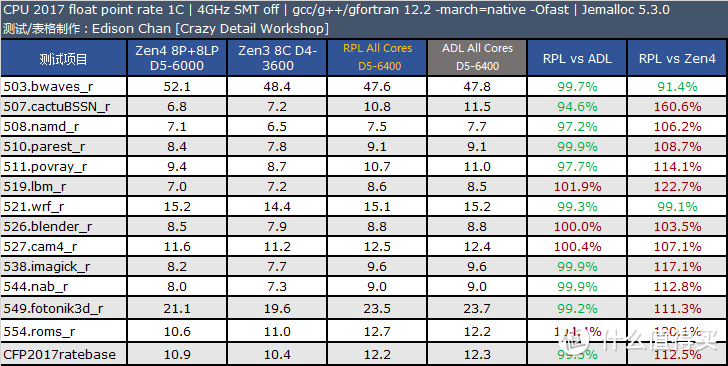
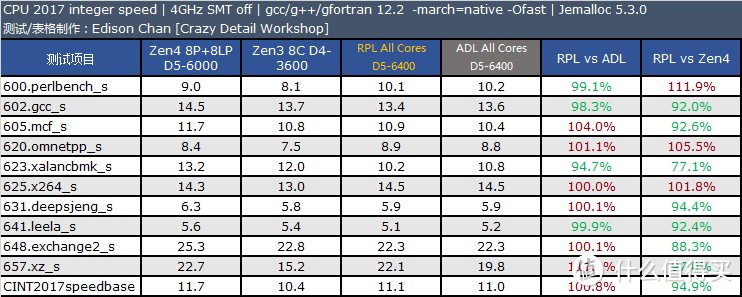
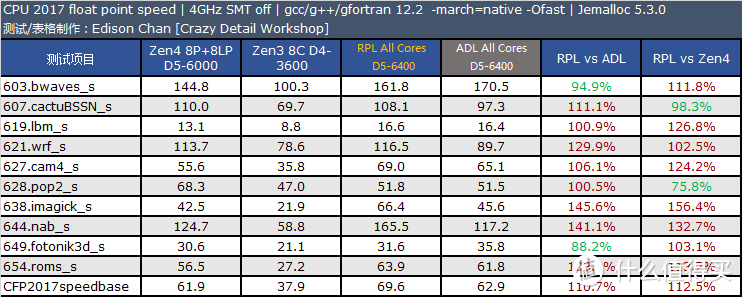
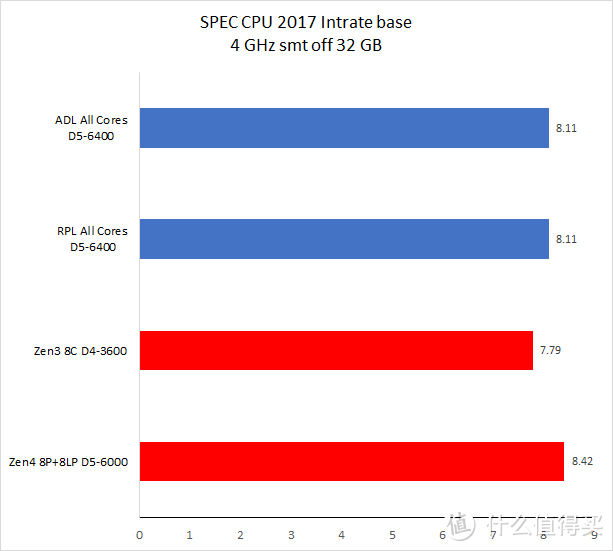
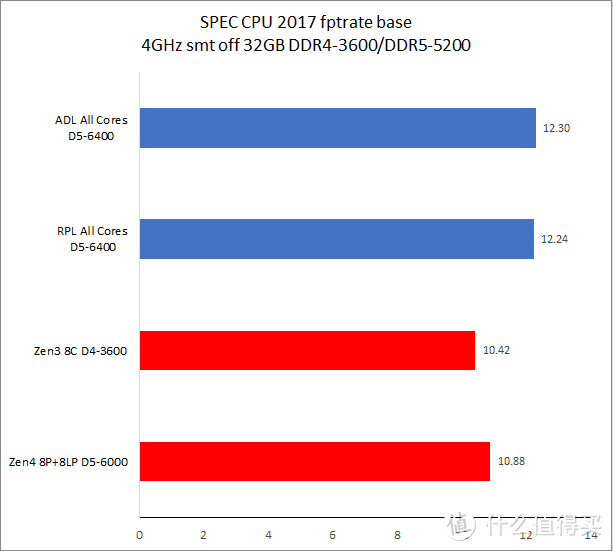
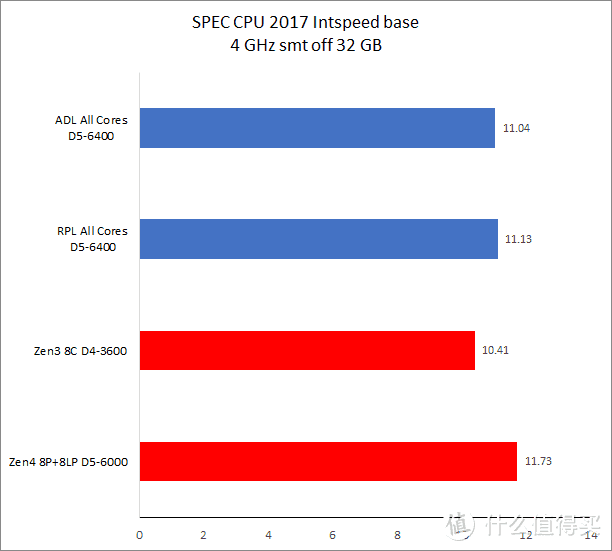
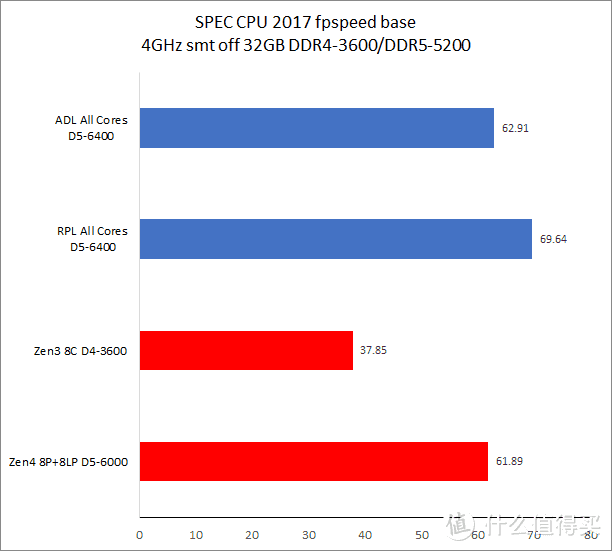
在同频测试中。Raptor Lake 的优势项目主要在多核和浮点测试上。而在单线程(此时测试运行于 Raptor Cove 上)整数测试中要比 Zen4 慢大约 5% 左右。
CPU2017 默频测试
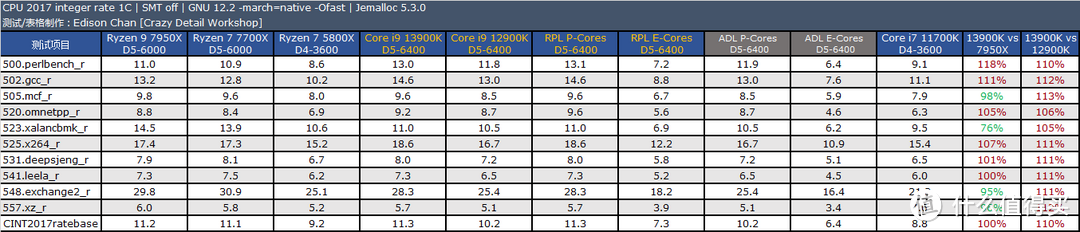
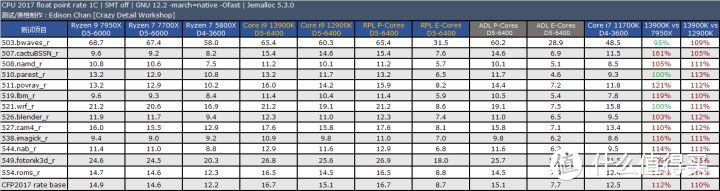
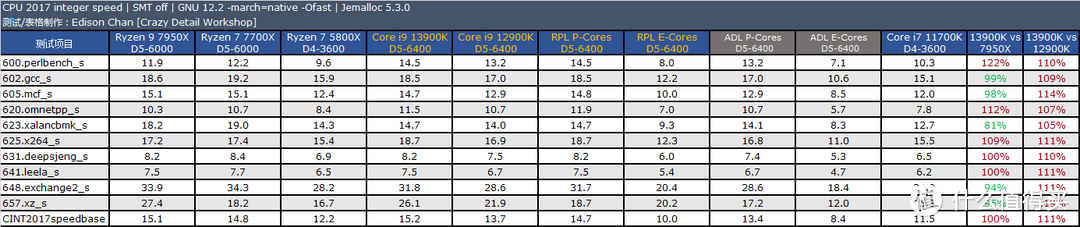
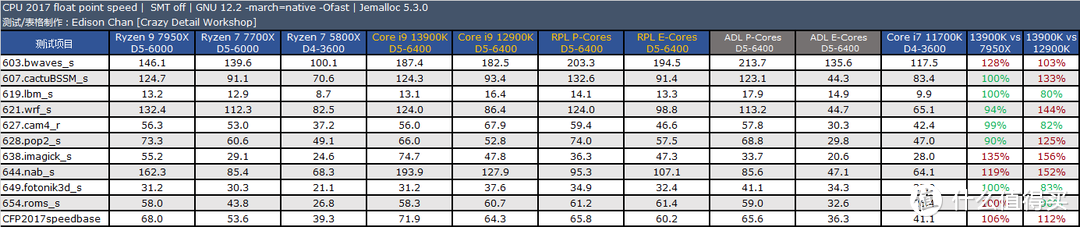
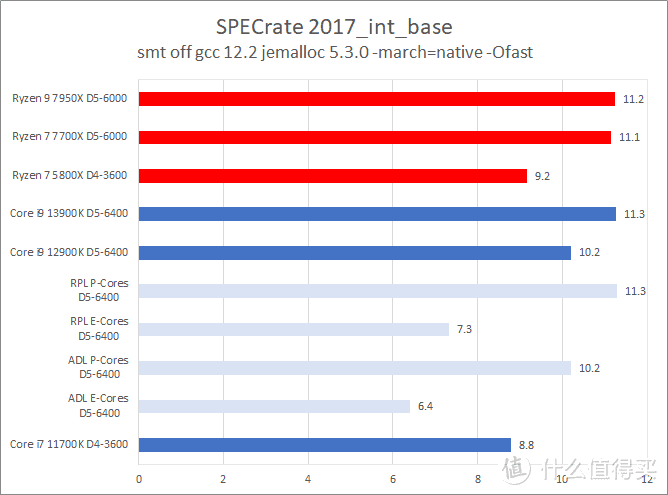
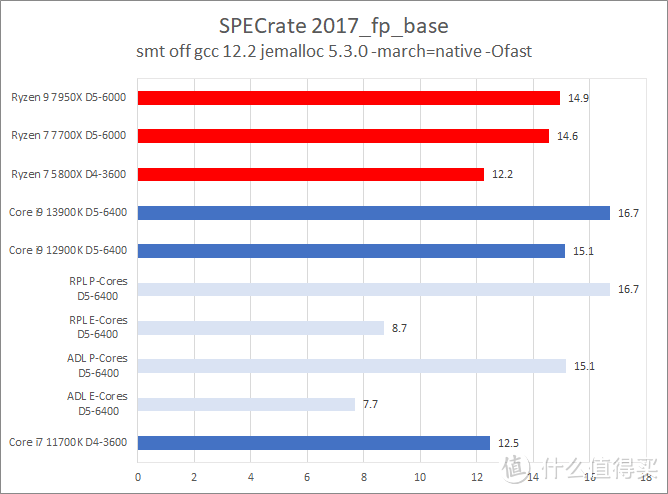
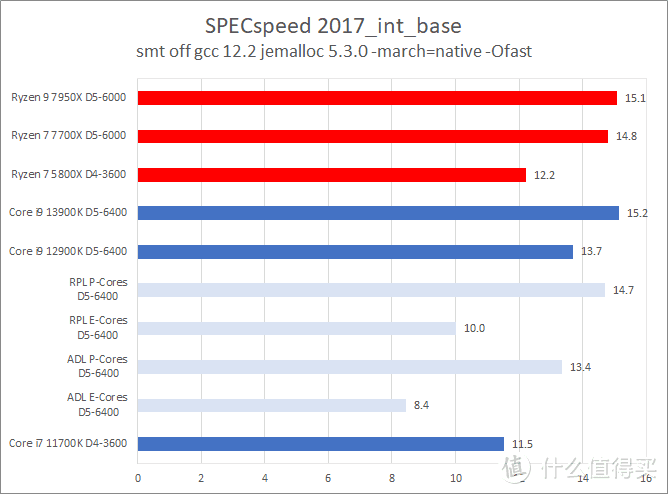
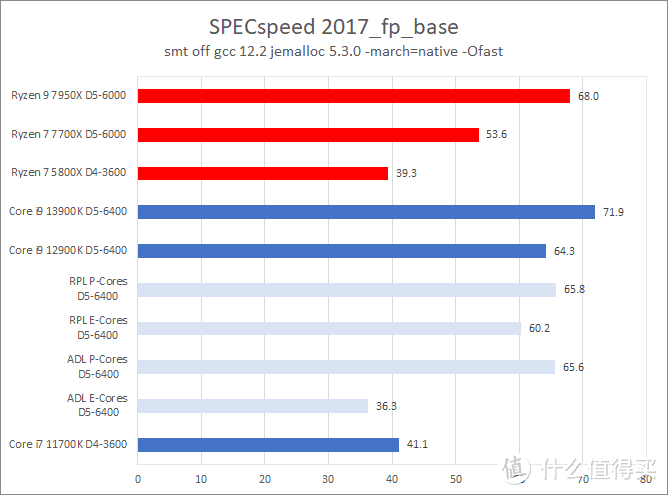
CPU2017 的测试结果表明。Core i9 13900K 的主要优势是在浮点上。此时它比 Ryzen 9 7950X 快大约 12%(单核)到 6%(多核)。而在整数测试方面。Core i9 13900K 和 Ryzen 9 7950X 基本持平。在个别项目中例如 xalancbmk 和 Ryzen 9 7950X 相比存在不少的差距。
但是需要注意的是。Intel Core i9 13900K 取得的优势是有代价的。那就是对系统电源有较高的要求:
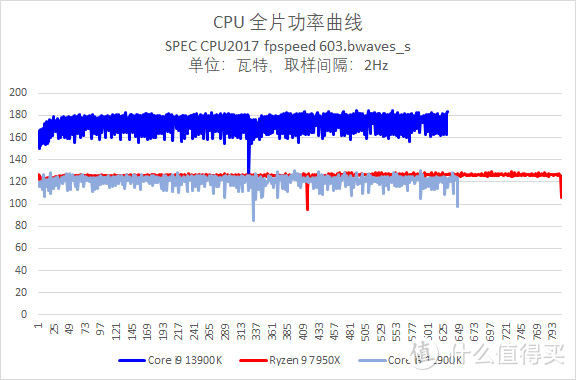
大家可以看到。Core i9 13900K 的耗电明显要比 Ryzen 9 7950X 高出一大截。其最大值为 184 瓦。均值为 174 瓦。
相比之下。Ryzen 9 7950X 显得温顺许多。最大值是 129 瓦。均值大约是 126 瓦。Core i9 13900K 分别高出 43% 和 38%。
芯片组和平台简析
之前传说Z790将CPU直连的4X M.2升级到PCIe 5.0。但实际是FAKE NEWS。因此在CPU直连扩展上Intel 13代+Z790的5.0 16x+4.0 4x在规格上是低于Zen 4+X670E的5.0 16x+4x+4x的。
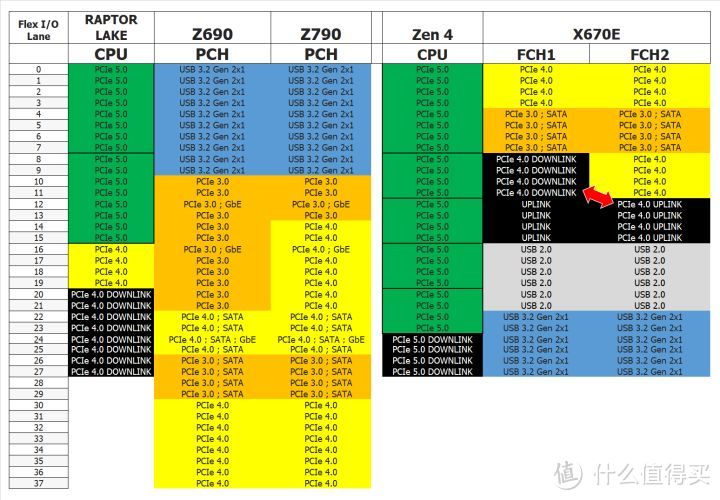
但CPU到南桥的DMI intel的8x 4.0是Zen 4的4x 4.0的两倍。这样Z790 PCH的整体带宽就更大。并且Z790 PCH将Z690的16个3.0通道+12个4.0通道。调整成了8个PCIe 3.0+20个4.0。因此南桥的扩展性有进一步的提升,AMD 2个FCH串联不仅是浪费上下行通道。并且扩展性实际还是比不过Z790的PCH。
除了扩展性。Z790另外一点变化就是支持Fast V mode。Fast V mode在SoC内部集成监测器监控SoC的负载电流并按实际负载的需求进行动态调节。可以避免大动态的突发负载(SoC电流超过ICCMAX)的情况发生。
ROG MAXIMUS Z790 HERO赏析

我们稍早测试的ROG Crosshair X670E Hero基本还是延续了之前Z690 HERO的设计。但Z790 HERO在一些设计方面发生了比较大的变化。采用了不少新的设计语言。

主板供电散热部分延续了之前Z690 HERO的设计。LGA1700接口并未升级。也能够支持老旧的12代处理器。

13代处理器在封装和空间兼容性方面和12代没什么区别。就无需多言。

对于Z690和X670E而言。4条DIMM只能跑4000的基础频率。性能还不如D4。基本没有意义。但Z790在13代处理器的配合之下。4条也可以跑到更高的频率。这部分测试我们会在后面具体再说。除此之外。主板右上的区域有Q-code灯。开机和重启物理按键。还有一组5V和12V的AURA接口。24pin下方是前置Type-C接口。和加强PD供电的6pin。旁边还有显卡卡扣释放按钮。这些设计都和Z690 HERO一致。

PCIe上也维持了Z690 HERO的布局。一根全速的PCIe 5.0 16x。再加拆分出来的8x 5.0。底部则为PCH下的8x 4.0,也可以拆分为4+4。但现在4090普遍3.5-4槽。第二个槽会被挡住。其实我觉得最合理是第二个CPU拆分再往下挪一位。最下再保留个PCH下的4.0 8X。

PCH散热片外观重新设计,放弃了亮面点阵。相对Z690 HERO的亮面Logo更为内敛。6组SATA两边是横插的USB 3.0接口。稍上则是Type-C和Type-C的加强供电6 Pin。还有显卡卡扣释放按钮。
CPU
这是好文明。特别是对于我这样的风冷党。
底部密密麻麻的风扇接口。水流传感器还有AURA接口一字排开。

原有金属背板是Formula专属。但ROG取消了Z790 Formula产品线。就将金属背板下放到HERO。斜45度的纹理再加上ROG的Logo整体显得十分有质感。在美观的同时。也可以更好的保护PCB。特别是在将主板放入机箱的时候。可以避免PCB背面被铜柱刮伤。此外供电下方还有导热垫同背板贴合。起到辅助散热的作用。
更新:在测试RTX 4090后。我还发现金属背板还可以起到避免主板PCB变形的作用。要知道STRIX RTX 4090 GAMING O24G就差不多有5斤重。

上图是Z790 HERO被拔得一丝不剩的裸照。还是颇为性感诱人,我们可以清楚的看见PCIe释放按钮的连杆结构。

拆下供电散热片。我们可以发现供电部分采用19+2并向设计(紫色)。加金属散热片的双8pin接口(黄色),Procool金属散热片可以降低供电接口的温度。

MOSFET是Renesas ISL99390FRZR。仅仅是在刚刚发布的X670E上见过。单相可以承担110A电流。整体供电规格是要高于20+1 90A的Z690 HERO。

主板上一共有3个M.2,靠近CPU的为CPU直连。靠下2个则是PCH下的。均为4.0速率。Z790 PCH虽然是单芯片。但其比X670E的东西桥其实还有有更好的扩展性和性能。并且功耗更低。

M.2 Hyper Card也延续了之前Z690 HERO的设计。8X接口可以扩展出两个M.2。插最后一个槽的话总计就可以扩展出5个4.0的 M.2。

IO COVER上依然是Polymo照明区域。但采用全新的设计。灯光照明区域更大。效果更华丽。

后部接口有9个USB 3.0 Type-A。1个10G的TYPE-C。USB方面的规格数量要差于之前的X670E HERO。但有2组雷电4接口。最左端为清空CMOS和盲刷BIOS的物理按钮。
处理器的频率控制机制
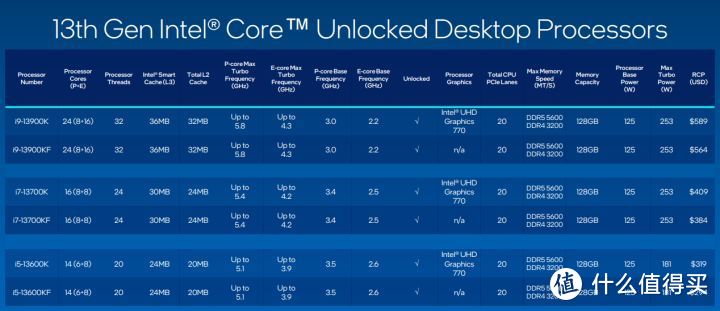
在intel官方公布的13代规格。可以发现有标注有各种各样不同话术的频率。TVB频率。TBMT频率。Max turbo频率。Base频率。这些眼花缭乱的频率让人迷迷糊糊。但实际最重要的全核心稳定频率却没写明。
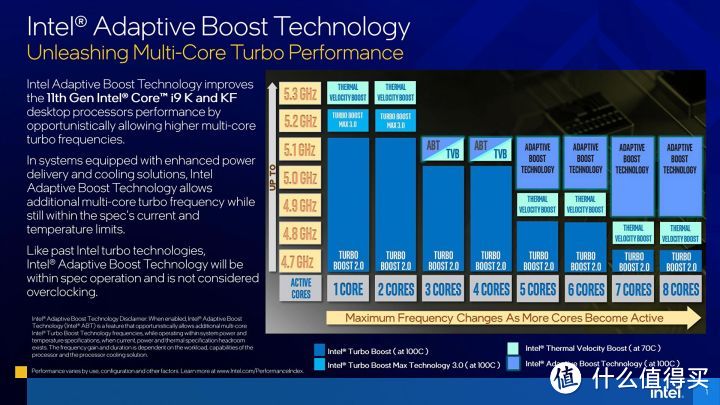
在说13代的频率之前。我们要先明白intel处理器的频率控制机制:intel的频率控制机制主要是TVB和ABT。ABT是i9专属。但也和TVB差不多。就是依据不同的核心占用数量对应运行频率(在没有触及功耗和温度墙的情况下)。
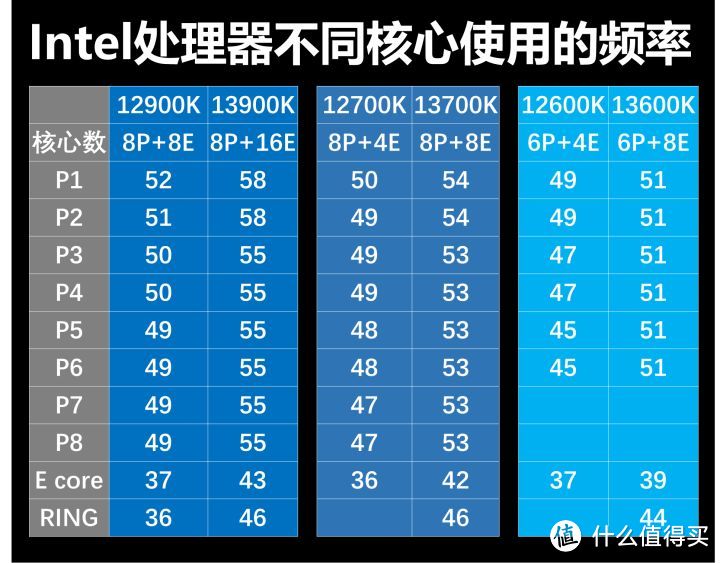
13代13900K在1-2核心占用的情况下。频率可以达到5.8GHz。在3核心以上是5.5GHz。13700K/13600K相同核心数量负载的P-core频率基本都提升了0.5GHz。而E-core则提升幅度更大。基本都提升了0.6GHz。这样的频率提升是在工艺依然是10nm没改线宽制程的情况下实现的。
13900K在跑CPU-Z和CINEBENCH的单线程和多线程测试的时候。就是反馈的是5.8GHz单核心性能和5.5GHz的全核心性能。5.8GHz的频率使得13900K的单线程性能一骑绝尘。
但13700K的1-2线程的频率54。仅比全核心53高1个倍频。而13600K甚至都是51。可以说是近年来少有完全没有Boost的处理器。我在用AIDA64查看后以为自己看错了。又用XTU再检查了一次才确认。
之前12代的uncore频率基本是被E-core频率拖累。默认全核心只能在3.6GHz。现在13代的E-core频率大幅提高,uncore也鸡犬升天。默认也达到了4.5-4.6GHz。
但我在这里引入第一个暴论:
intel处理器的单线程性能其实是没多大意义的。
在跑CPU-Z和CINEBENCH测试的时候。一般后台是及其干净的。基本不会有其他程序占用。在这样的情况13900K只会有1-2个线程使用。可以boost到最高的5.8GHz频率。跑分就十分的好看。
这样的boost频率除了跑单线程测试。在干净后台的情况下。点开窗口或者程序。瞬时也可以达到。
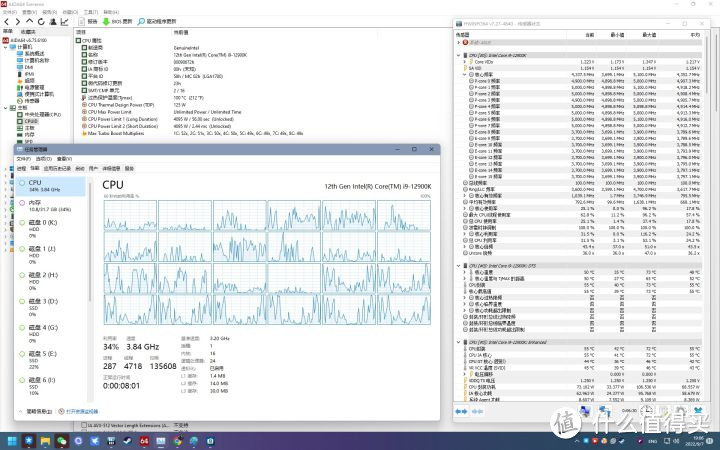
但这样的状态。是和实际使用情况脱节的。我相信大多数人使用电脑的时候会和我一样。多开一大堆程序。比如QQ。Wallpaper Engine。音乐播放器。还有打开十几个页面浏览器。Office甚至 Adobe。虽然这些程序不可能都同时占用CPU。但足以使得处理器Boost不到最高的频率。
再来说说游戏。任何游戏都不可能是单线程游戏。即使是CSGO/LOL这样的轻量级游戏。就说13900K运行游戏因也只能跑5.5GHz的全核心频率。即使都是轻载。
5.8GHz的ABT MAX BOOST其实并没多少实用价值。仅仅是为了单线程测试跑分好看而已。
我再来说第二个暴论:
intel的频率控制机制落后AMD 5年。

AMD在Zen+之后就引入了PBO的机制。处理器可以依据SoC功耗、VRM供电电流和温度动态调整处理器频率(默认设置也一样。只是限制数值更严格)。
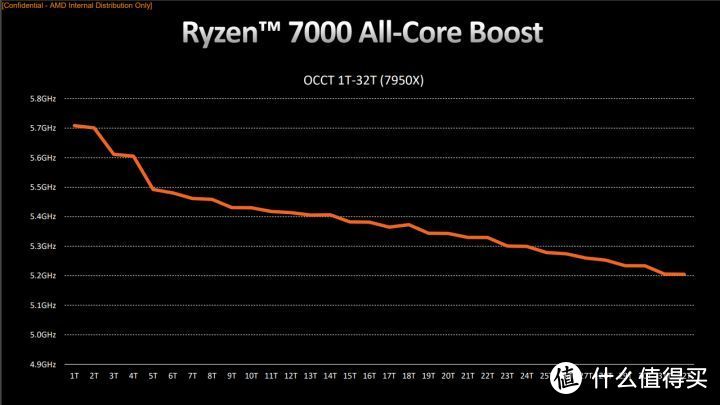
Zen 4在开启PBO后。7950X全核心重载可以有5.2GHz左右。单核心重载可以有5.7GHz左右。这样的简单情况和intel按核心占用数量决定频率从实现效果上来说差别不大。
但在游戏这样的典型多核心场景。处理器虽然每个核心都雨露均沾。但实际整体负载并不高。SoC功耗、VRM供电电流和温度决定了处理器依然可以跑到5.5GHz以上。运行在十分接近单线程峰值的频率。这是intel现在TVB/ABT机制无法实现的。
AMD XFR/PBO的机制更为灵活和智能。这就是为什么说intel的频率控制机制落后AMD 5年的原因。
频率功耗和温度
但也即使如此。intel可以在10nm工艺线宽不变的情况下实现全核心5.5GHz。还是很NB的。但这样的NB是需要付出代价的。这个代价就是爆炸的功耗和不可能压住的温度。
前面说的intel频率控制机制。仅仅是在没有触及功耗和温度墙的状态。现在再来说说功耗和温度。
13900K(8P+16E),13700K(8P+8E)和13600K(6P+8E)的TDP(热设计功耗)都是125W。但对于DIY市场而言。这个TDP并没什么意义。所以现在intel强调的是PL(Power Limit 功耗限制).
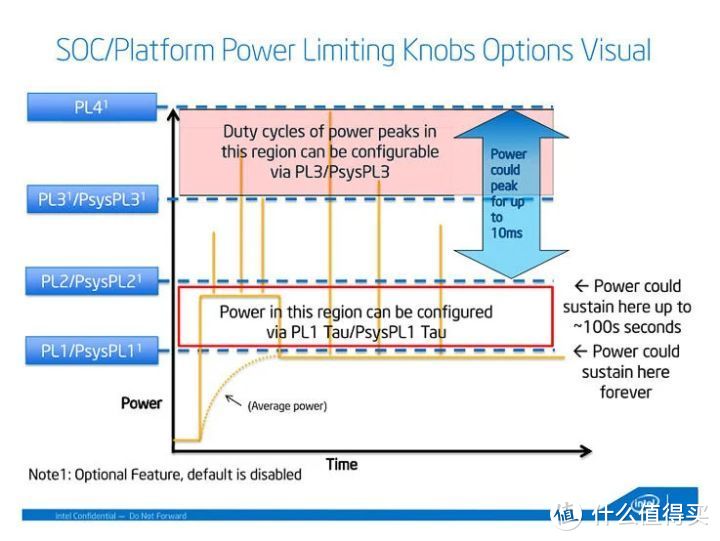
PL1是可以一直稳定工作的功耗;
PL2是可以持续稳定工作一段时间的功耗。PL2一般高于PL1。PL2在持续工作一个限制时间(Tau_PL1)后。重新会被限制在PL1;
PL3是瞬时可以达到的功耗范围;
PL4是可以安全工作不能逾越的绝对功耗;
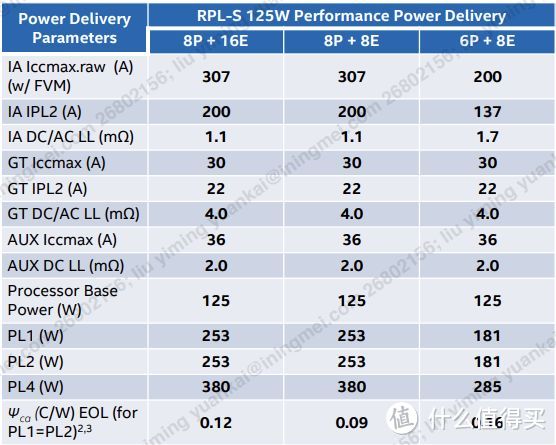
如果追求性能。厂商可以将PL1/PL2统一设置成一样。13900K/13700K为253W。而13600K为181W。在这样的情况下intel建议主板供电在8相以上。并增加供电散热。
253W和181W基本就是13700K和13600K可以达到的极限功耗。但253W对于13900K则是完全不够的。在这样的情况下13900K的性能是不足以充分发挥的。
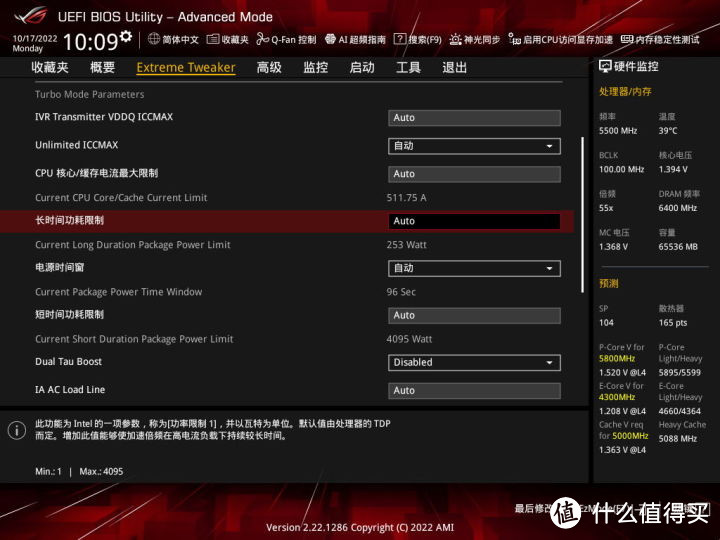
实际上一线主板厂商的之前的Z690都将PL1/PL2直接设置成了4095W。就是说完全没限制。不过在Z690更新13代BIOS和Z790后稍微收敛了点。设置PL1 4096。在96秒之后降低到intel规定的253W。(不同型号的处理器会自动匹配PL,有所区别)
我们使用AIDA 64单压FPU 10分钟(环境温度25度。开放系统)。记录稳定温度和功耗。Vcore电压。如果处理器温度超过TJmax发生降频则为Fail。我们测试主要是使用的雅浚GA5工程版和VK的GL360进行。这基本是目前AIO的性能标杆。
需要注意的是。不同处理器个体存在较大的差异。功耗和温度可能有比较差的差别。我这里处理器都标明满载电压和SP数值(ROG Z690-E GAMING数值。如果是Z790 HERO会更高一点)。再者我测试是在设定25度的空调房。房间比较大。环境温度也有波动。结果仅供参考。并不代表所有情况。
CPU体质好的在比较低的默认电压就可以稳定。而对于体质比较差的默认电压就比较高。特别是对于13代。频率相比12代高了很多。因此默认电压也就更高。
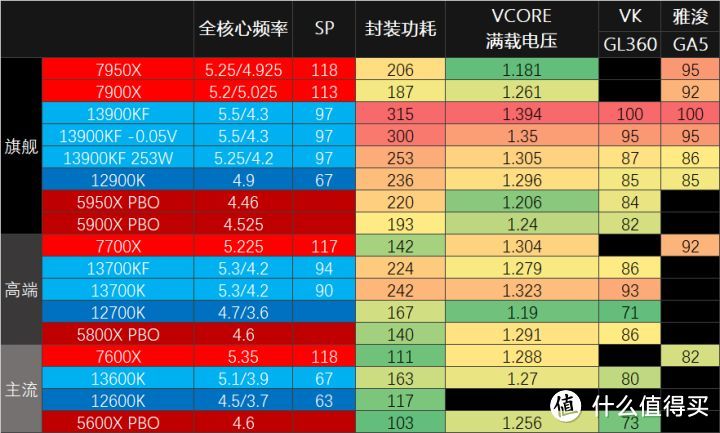
我手头SP为97(ROG Z690-E GAMING数值。如果是Z790 HERO是104)的13900KF FPU功耗315W。负载Vcore电压1.394V。使用VK GL360大概1分钟到100度。降频,Fail测试不通过。
其实要完全压住默认的13900K。一体式水冷这样的通常手段是完全不可能。高功率水泵+大规模冷排估计也不行。如果想要完全压住。你考虑的应该是用压缩机还是冷水机。
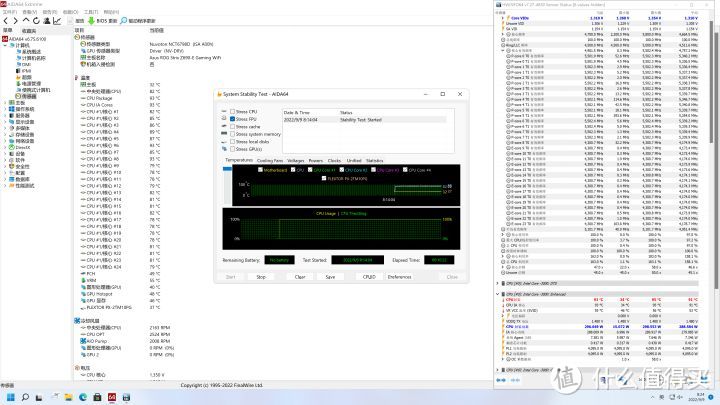
如果将BIOS核心电压-0.04V(实际Vcore电压1.35V)。功耗可以控制在300W以内。温度也基本可以稳定在95度,10分钟FPU全程不降频,并且可以通过y-cruncher测试。我也尝试过更低电压。虽然也可以过10分钟 FPU。但并不是绝对稳定。
这样常规360还是可以勉强压住默认频率的13900K。但这样压得住的条件还是比较苛刻的:
需要CPU体质足够好。默认电压比较低。并且降压也可以稳定;
需要有足够好性能的顶级360水冷。就如我这次测试的VK GL360;
然后要求环境温度足够低。夏天30多度不开空调还是要挂。如果装进机箱风道散热也要足够好;
这样的条件可以说是缺一不可。现在CPU体质好坏的意义不在于可以超多少。而是在于默认电压和功率可以低多少。降低多少电压还可以稳定。
如果按照intel指引将13900K PL1/PL2都设置在253W。那处理器满载频率大概在5.2-5.25GHz。使用雅俊GA5和VK GL360都可以压制在86-87度。
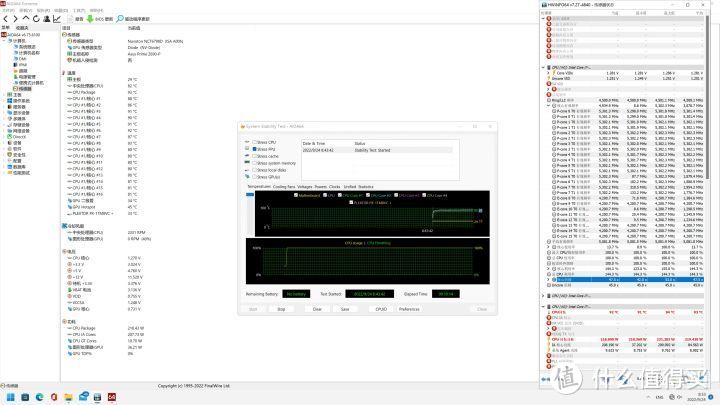
手头94 SP 13700KF默认满载Vocre 1.279V。功耗224W。而90 SP的13700K默认满载Vocre 1.323V,满载功耗242W。温度甚至相差近10度。
即使是220-240W的13700K也同样需要顶级性能的360水冷。如果是体质较差。电压较高的13700K即使旗舰双塔风冷直压就比较困难。还是需要降压到210-220W的功耗水平才能压得住。
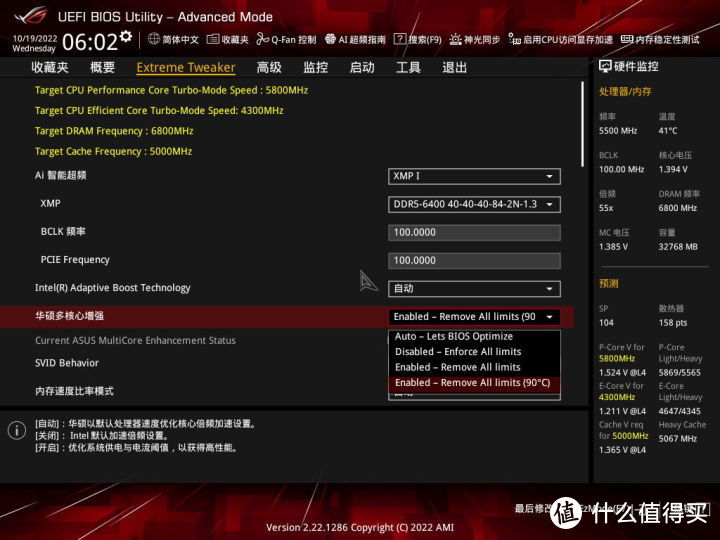
板商也知道13900K根本压不住。因此ROG给BIOS加了个温度墙。可以在多核心增强部分设置90度的温度墙。
13600K大概是163W。另外个13600KF大概体质更好。大概150多W。其实4热管单塔也比较困难。需要240水冷或者5-6热管这种比较好的单塔。甚至入门双塔。
13代高功耗的核心原因不是因为更多的E-core而扩大的规模。而是因为为了保证高频稳定。intel进一步拱高了电压,。
想要压得住13900K/13700K。还是需要一个顶级的360。这里说的顶级360水冷并不是那些2xx/3xx的便宜货。而是各家的高性能方案。高价的有Astesk。而性价比比较高的如我本次测试使用的VK GL360。基本有300W的散热能力。性能相比Astesk 7代都还有一定优势。
而雅浚也在近日推出了GA5。其有与GL360十分相近的性能。并且售价更低。也很值得推荐。
当然。Astesk也会有回击。ROG联合Astesk设计了8代泵方案的龙王3金属冷头。冷头的散热面积有比第七代提升32%。水冷管加粗了40%, 屏幕采用Metrics LED 像素风。 可以显示参数及自定义文案。也将与近期上市。相信届时又将再次夺回AIO性能之王的宝座。
当然。前面说的是全满载情况。实际13代日常功耗控制很好。在默认频率设置下。桌面待机的处理器功耗就10W水平。大多游戏功耗也就七八十瓦。相比Zen 4其实是更低的。
另外还有朋友问我13900K超频怎么样。但我问他说你是想上冷水机还是压缩机。劝他不要有不切实际的幻想。现在问题是默认3xx W能不能跑负载不碰温度墙不降频的问题。就不要想超频了。即使是13700K。相比13900K也是体质较差的个体。5.3上到5.5也需要更高的电压。这样长期用也不舒服;不过13600K还是可以折腾的。整体功耗较低。小超到5.3还是有玩头。现在CPU的体质意义SP得分高低意义已经不在于可以超多少。而是默电功耗多少。降压多少可以保持稳定。现在旗舰处理器虽然不是出厂灰烬。但需要更高电压更高功耗才能稳定。这样的使高电压高功耗使得通常的散热方式远远不能满足散热需求。日常使用超频已经成为了过去式。
内存:Z790最大的提升
DDR5虽然频率和带宽高。但相应的延迟也高。这是很多用户讨厌DDR5的主要原因之一(另一个是贵)。很多人就注意到DDR5的CL动辄30-40。但这个CL仅仅是时钟周期。我们还需要考虑每个周期的耗时。我在12900K首发评测的时候就推导过:
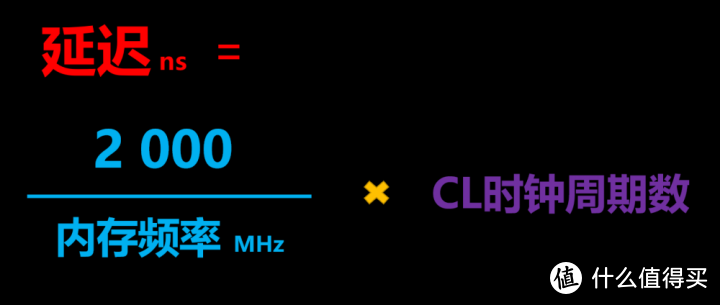
就是说内存延迟同CL成正比。同内存频率成反比。内存频率提升是可以覆盖掉CL周期的增加的。
我们使用AIDA64内存带宽延迟测试测试ADL-S,RPL-S。Zen 3/4的内存带宽和延迟。
我们测试的内存分别是
TEAM DDR5 16GBX2 40-40-40-84Gskill DDR4 8GBX2 19-19-19-39
我测试的5950X之前是可以上FCLK 2000。但在升级AGESA后。虽然FLCK 2000可以点亮。但稳定性和效能存在问题。5950X的4000频率测试频率为3866。
Zen 4的FCLK同MCLK内存控制器频率比例不再是1:1。而是2:3。在DDR5 5200的情况。MCLK是2600。而FCLK则是1733。FCLK体质上限一般还是2000。那MCLK就是3000。内存频率则是6000就差不多毕业。当然这仅仅是差不多。实际可以上到6200同步的频率。就是FCLK为2066。
13代和12代一样DDR4为GEAR1 BCLK和内存控制器同步。3600和以下为自动。3600以上需要手动。一般可以到2000 BCLK;DDR5为GEAR2。FCLK和内存控制器频率为1:2。13代内存频率在Z690上支持上没有明显提升,但配合Z790。还是有明显变化。
我手头只有自己买的CL40 Mdie的便宜货。带宽延迟不好看。请各位见谅。但Z790对于这些便宜货而言也有化腐朽为神奇的效果。我自己的金士顿HyperX 6000在Z690即使使用的13代处理器。也只能稳定6400。而在Z790 HERO上就可以轻轻松松过1小时的6800 C36-39-39-76的memtest。
当然。便宜货上到6800频率并不是简单的开个XMP就可以。还是需要手动调节SA,IVR,MCV电压来提升稳定性。
DDR5 4根插满是老大难问题。五年是Z690还是X670不折腾4根XMP 4800都难得点亮。而13代在Z790 HERO配合下。4根直接开XMP轻轻松松6400还是没问题。4根32GB DDR5就有128GB 6400。这对于生产力用户还是有很大吸引力。
测试采用默认的XMP参数设置恒定。再调节频率。我们这个设置并不是最优化参数设置。仅仅是分析频率对于延迟的影响。如果要优化小参。那 就不是一下的事情。一杯茶一包烟。花个半天也冒个泡(我不抽烟)。
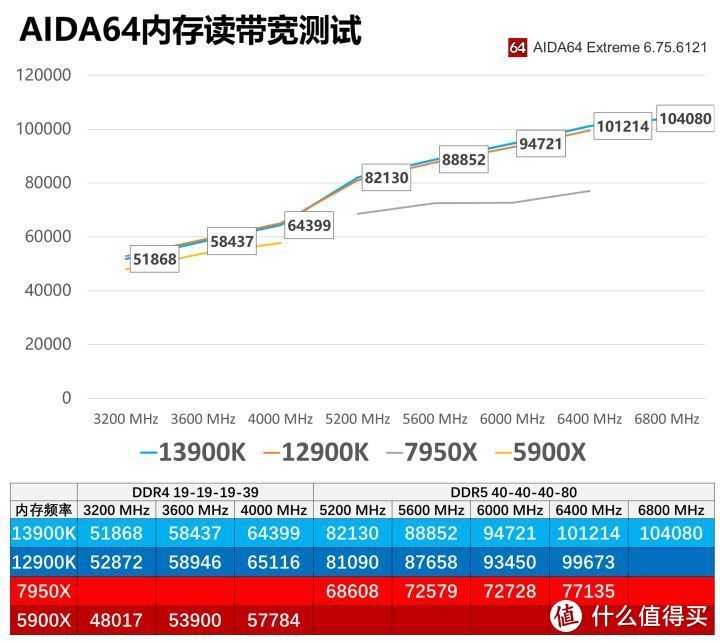
13代RPL内存带宽基本和12代ADL一样;
Zen 4同频内存带宽大概只有ADL/RPL的80%左右;
Zen 4和Zen 3一样,单CCD型号写带宽只有双CCD型号的一半水平;
Zen 3 4000频率实际为3800MHz。Zen 4 6400频率实际为6200MHz。
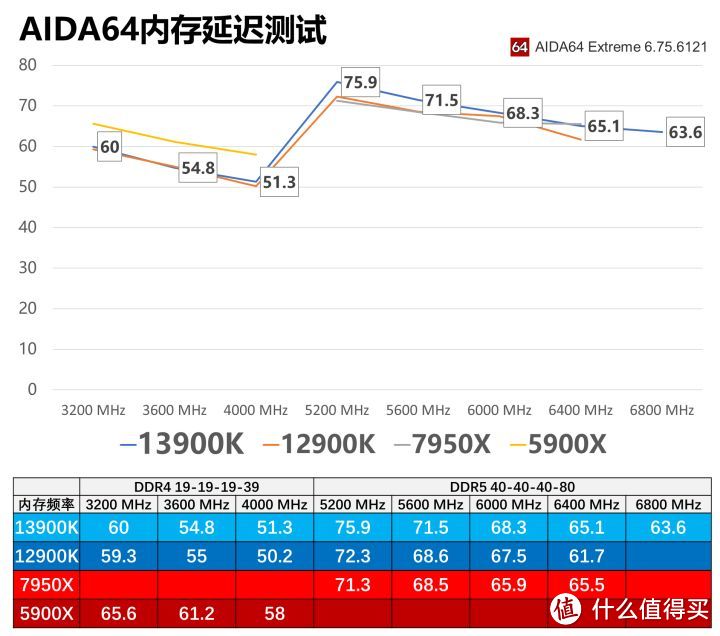
Zen 4的内存延迟相比intel ADL/RPL稍低。尽管分开封装的IO芯片增加了延迟。但FCLK同内存控制器频率比例为2:3。而intel D5为1:2。在6000MHz的内存甜点频率。FCLK频率为2000。而6400的intel BCLK仅为1600。
这部分我最后说明下DDR5内存颗粒选择问题。目前DDR5
CPU
颗粒基本有4个类别:首先是美光颗粒。除开原厂的4800/5200基本都是美光颗粒。基本没超频余地。基本也就5200水平; 再就是三星颗粒。基本5600频率都是三星颗粒。少部分6000也是。一般体质是6000-6200。上6400就比较困难; 最后是海力士颗粒。海力士颗粒目前主要是Mdie。Mdie一般体质在6400-6600。特挑在电压足够高的情况下可以上到6800-7000;

另外海力士还有新的Adie。颗粒型号是H5CG48AGBD,目前基本仅有海力士原厂条是。其是JEDEC规范。没XMP。在1.1V下就是5600的频率。一般在加压以后可以稳定7200。传说GSkill 6600 PN为TT48KXS820A为Adie。但我没具体验证。
对于Zen 4平台而言。既然6200-6400MHz就是极限。那一般的海力士Mdie就可以。没必要追求高频特挑。再压压小参就差不多了。不过三星还是差点意思。6000虽然可以。但大部分再高就很难绝对稳定。

而intel Z690/Z790用户其实可以等一波Adie。在intel官方的XMP 3.0列表上。已经可以看见芝奇7600了。就连我们本次测试的Z790 HERO在上2根的情况下也可以到7466。而Z690 HERO。一般XMP就6600。手动细调基本6800就是极限了。
生产力/应用性能测试
很多人比较CPU性能。就简单的看个CPU-Z的分数。Zen 4的CPU-Z分数不太好看。就觉得垃圾。
在开始性能测试之前。我们要明白各个测试项目是考察什么方面的性能。对于日常应用代表什么意义。
Cinebench R23/Keyshot这类渲染是重SSE。是浮点运算;
y-cruncher和X265是重AVX运算;
Office/Photoshop/Lightroom Classic是重整数运算;
游戏是重整数运算。
就是说日常使用和游戏是重整数性能。而渲染/视频这样的生产力是浮点/SSE/AVX性能。CPU-Z的说明是使用SSE/SSE2进行二维噪音函数计算。也是重浮点运算。并不能反应日常使用和游戏性能。
从前面的理论部分测试看。Zen 4的整数部分基本和RPL持平或者稍强。而浮点部分则稍弱。
CINEBENCH R23
13900K如果将PL限制在253W。频率基本维持在5.1-5.2GHz。性能相比PL不限制稳定5.5GHz的13900K性能有10%的损失。也低于功耗更低的7950X。
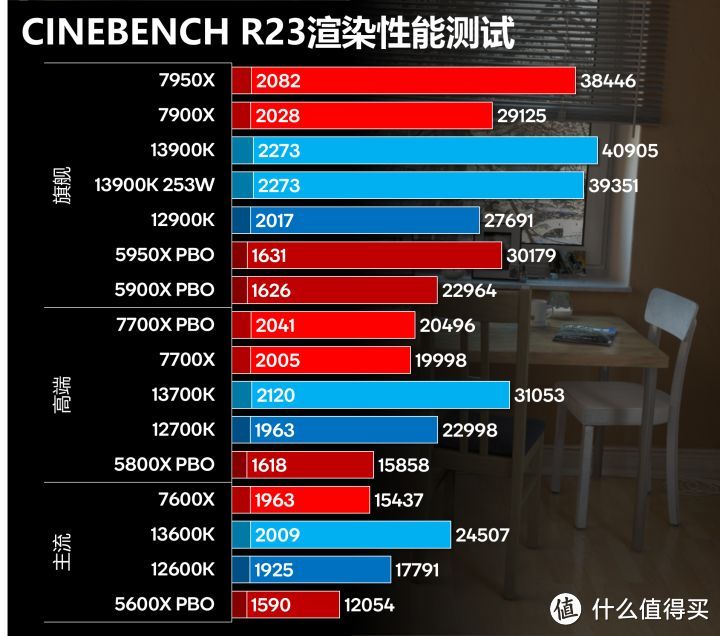
但13代RPL相对Zen 4有跨级的优势,13600K胜7700X。13700K力压7900X。这得益于13代再度扩大的E-core规模和更高的频率。13代频率是固定的。可以参看前面全核心频率表;
13900K将频率限制在253W。相比不限制可以实现96%的性能;
如何开启13900K 90度温度墙。在使用VK GL360水冷的情况下。大部分P-core会落到5.4GHz。封装功耗可以跑到290W。最终得分40545,性能损失不到1%。这个功能十分实用。建议打开。
13900K单线程可以达到2273分。这得益于1-2T的5.8GHz ABT频率。但其实这个频率意义不大。单纯刷分而已。实际使用和游戏基本是不会出现的。
而7600X/7700X/7900X/7950X单线程基本可以到5.37/5.5/5.6/5.65GHz。实际使用和游戏可以轻易达到这个频率。甚至更高(因为多核心轻载比单核心重载温度更低)。具体可以看后面的游戏测试部分。
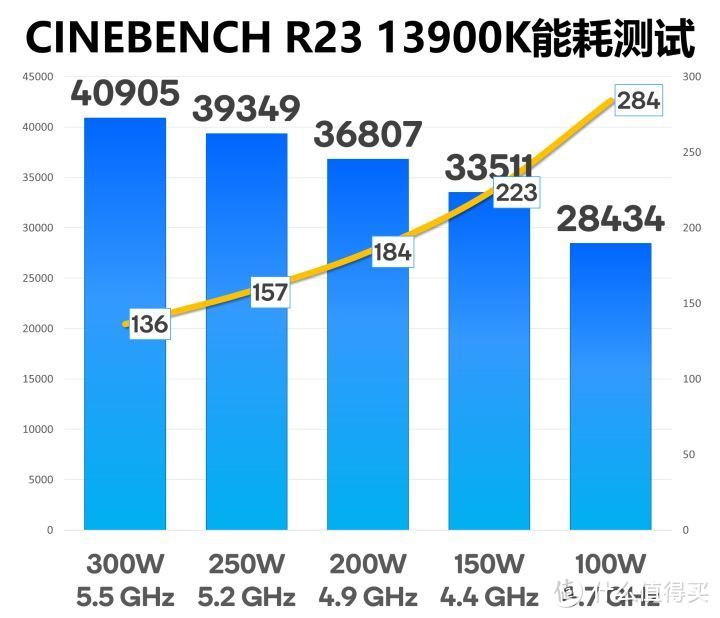
我们使用13900K分别限制在300/250/200/150/100W的PL。测试能耗。13900K在一半功耗150W时候依然有81.9%的性能。而在250W则更是有96%的性能。更为鲸人的是。100W的13900K多线程性能就要高于240W默认的12900K。究竟更多核心会导致更多核心分功耗。但核心频率更低。需要的电压就越低。能耗比就越好。反过来说13900K为了上到更高频率需要更高电压。在功耗上还是付出了很大的代价。
Keyshot 11渲染性能测试
Keyshot我们选择一个比较简单的室内装潢渲染图,KEYSHOT 11和CINEBENCH类似是重SSE测试。但整个完成时间需要十几分钟甚至几十分钟以上。对于稳定性相比R23有更高的要求,不过相对于AIDA64 FPU和后面的AVX项目功耗负载更低。
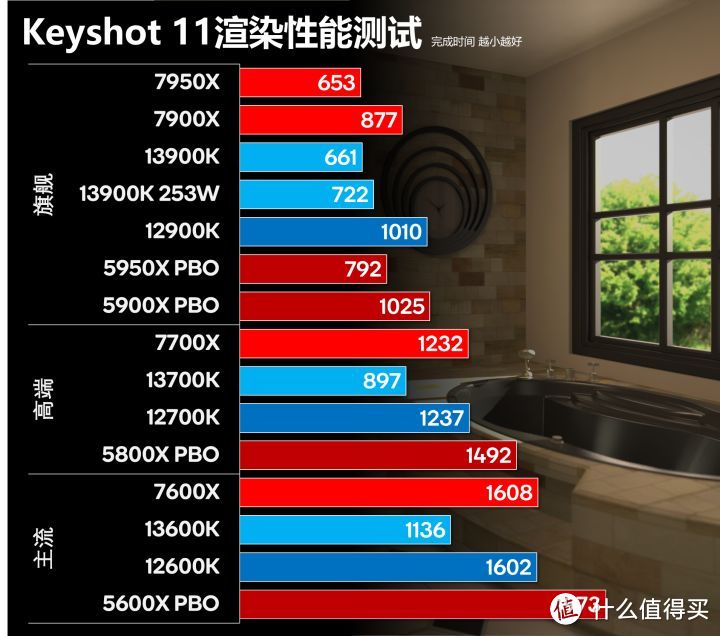
Zen 3和Zen 4的稳定频率和前面的R23差不多。功耗也不高。13代i5/i7借助E-core优势明显。但16核心的7950x打过8P+16e的13900K还是有点出乎我的意料。
7ZIP性能测试
7ZIP测试主要是对内存延迟敏感。对内存/缓存带宽不敏感。而对于数据缓存容量/速度和TLB。还有乱序执行/分支预测敏感。这个测试不使用FPU和SEE。大部分代码是32位整型。少部分是64位整型。压缩测试有大量随机访问内存和缓存。执行时间的很大一部分CPU都在等待缓存或内存的数据。
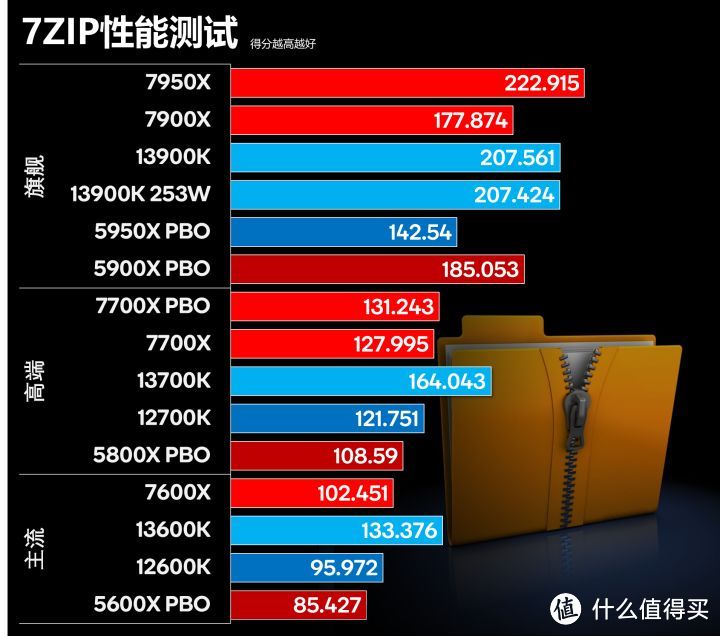
Zen 4性能虽然超过了12代。但相比再度增加E-core和频率的i5/i7仍然有差距。不过7950X还是超过了13900K。这应该还是和Zen 4的整型性能优势和增加50%的TLB相关。
此外分支预测失败率对于7ZIP性能影响也很大。13900K大概在10%。而7950X大概在6.35%。解压测试在分支预测错误后。流水线在下个时钟周期就无法正常工作。导致CPU资源就会利用不充分。但超线程可以改善CPU资源的利用率。因此超线程可以大幅提升解压缩性能。而GMT E-core又没超线程。利用率和效率就会存在问题。
7ZIP的由于是整型负载。功耗较低。13900K功耗都没有超过253W。因此时候限制253W的PL性能没有什么差别。同时Zen 4的稳定运行频率相比前面的渲染也更高,7950X可以运行在5.45/5.2GHz的频率。这特进一步拉升了Zen 4的性能优势。
y-cruncher性能测试
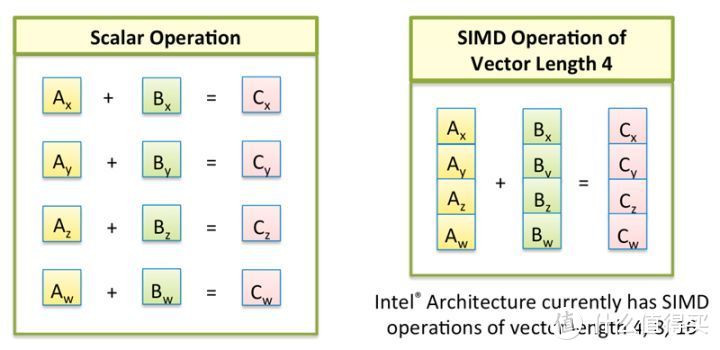
在AVX性能测试之前名为用尽量浅显的语言介绍下AVX是什么。一般计算是标量操作。一个时钟周期只能进行一次计算。而以SIMD(Single Instruction Multiple Data 单指令流多数据流)方式可以以向量的方式。在一个时钟周期并行进行多个运算。
AVX (Advanced Vector Extensions 高级向量扩展)则是实现SIMD的路径。AVX-512相比通常的AVX2能够支持更大的寄存器位数。有更好的性能。AVX虽然由于并行度高。性能更好。但具体使用需要程序在编写的时候专门优化。并且需要在处理器内有相当大的专用电路来支持。但实际情况是。除了科学计算专业领域有较为广泛的支持。在通用的消费领域程序。除了视频编码都很少提供对AVX-512的支持。AVX-512部分被不少人(特别是AFAN)说成是毫无用处。只能发热的电热丝。
intel在11代Rocket Lake提供了对AVX512的支持。在12代虽然大核心GDC支持。但小核心GMT并不支持。导致intel并未提供对AVX-512的官方支持。而在13代Raptor lake则彻底的放弃了对AVX-512的支持。但Zen 4却提供了对AVX-512的支持。这个时候不知道之前叫电热丝的AFAN是否还继续坚持之前的观点。
y-cruncher是一个多线程计算Pi的测试程序。可以充分利用AVX甚至AVX-512进行计算。最新的7.10版还增加了对Zen 4的AVX-512的支持。我们选择50亿位的多线程进行性能测试。
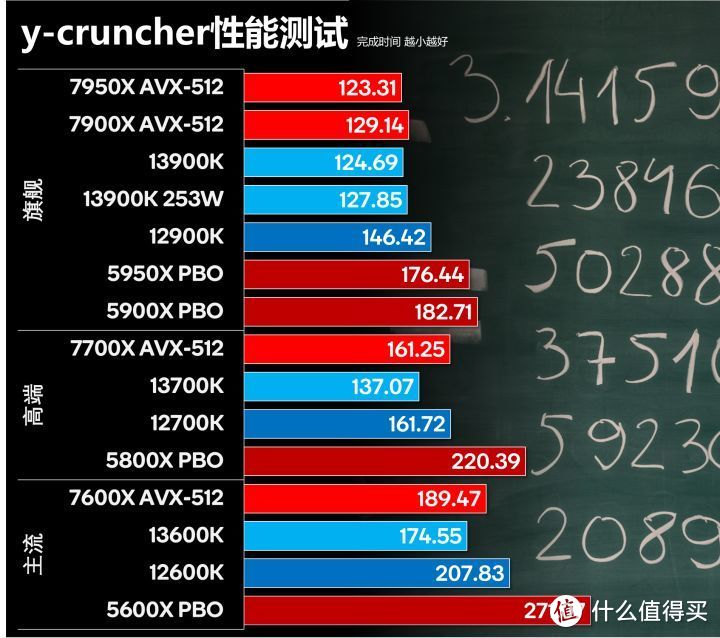
Zen 4在y-cruncher测试中是运行的AVX-512路径。目前BIOS没有AVX-512开关。程序也没提供参数选择。在y-cruncher测试中Zen 4相对intel 13代有明显优势。8P+8E的13700K打不过12核心的7900X。8+16E的13900K也打不过7950X。主要原因是E-core在AVX项目中性能较差。FMA基本只有P-core一半。如果算上FADD那就三分之一的规模水平了。
y-cruncher负载比AIDA64 FPU更高。13900K我即使降低电压。峰值功耗也到达了320W。温度超过100度。我在BIOS调高温度墙。才能不降频完成测试。
y-cruncher这样的AVX项目对于内存带宽也比较敏感。13900K如果内存频率从6400提升到6800。还是可以有2秒的提升。并且能够超过7950X。
另外50亿位测试需要占用22.8GB内存。其除了对CPU有极高负载。还对内存的稳定性有极其苛刻的要求。我自己的一组金士顿DDR6 6000 OC 6400按照1.435V的VDD/VDDQ在Z690都不能通过测试。需要打开高电压模式加压到1.48/1.46V才能通过,而现在相同设置在Z790 HERO上可以6800通过测试。y-cruncher也内置了压力测试功能:我在超频内存后。首先运行y-cruncher的性能测试。再运行稳定性测试。其能够比memtest更快发现内存的不稳定。
X265编码性能测试
X265编码是重AVX的测试项目。这个测试基本是CPU最高负载的测试。同时我们使用X265考核处理器的极端条件的功耗和温度。 编码使用的视频源文件是ducks_take_off_2160p50.y4m。使用 slow 预设。以 28 恒定速率因子来压缩。码块树 CTU 数量为 64 个。对于Zen 4我们分别使用了AVX2和AVX512两种指令集进行测试。使用的命令行如下:
x265.exe ducks_take_off_2160p50.y4m –preset slow –crf 28 -o duck.mp4 –ctu 64 –profile main10 x265.exe ducks_take_off_2160p50.y4m –preset slow –crf 28 -o duck.mp4 –ctu 64 –asm avx512 –profile main10

intel 13代在X265中性能也不如Zen 4(即使不用AVX-512),具体原因同上。还是E-core AVX性能不佳导致。2个E-Core打不过一个Zen 4。
X265支持AVX-512。Zen 4在跑AVX-512路径的时候。大概性能有2-3%的提升。这低于12900K 8个P-Core 8%的提升幅度。
如果将13代内存上到到6800,性能大概还可以提高0.03 FPS;
12900K屏蔽E-core跑AVX-512功耗比不屏蔽的功耗还高。但AVX512性能依然原顶不了少E-core的性能损失。因此intel在消费级处理器为了E-core砍掉AVX-512是十分正确的决定。
前面测试的Cinebench/Keyshot是渲染。X265是视频编码。但实际应用这几个软件并不是很广泛。现在渲染实际使用更多是V-Ray/Blender。视频压制是ffdshow,视频编辑是PR和达芬奇。但这些生产力工具更多依赖是GPU。而不是CPU。在稍早的RTX 4090测试。GPU可以在渲染和视频编码任务提供相比CPU数倍甚至数十倍的性能。还有更高的能耗比。因此CPU对于一般消费者的生产力性能也会越来越不重要。因此我们需要更多关注处理器的日常和游戏性能。
Office 2021测试
办公室生产力基准测试是根据在办公室里典型一天的常见任务而设计的。该基准测试打开Excel 表格、PowerPoint 演示文稿、Word 文档和 Outlook 电子邮件。这些应用程序会同时运行。而焦点会从一个任务移到另一个任务。例如。该基准测试从 Excel 中复制一个图表并将其添加到 PowerPoint 幻灯片中。它从一个 Word 文档中获取文字并将其添加到另一个文档中。该基准测试着重于测量直接影响用户体验的性能方面。如提供流畅的互动和快速处理大型任务。
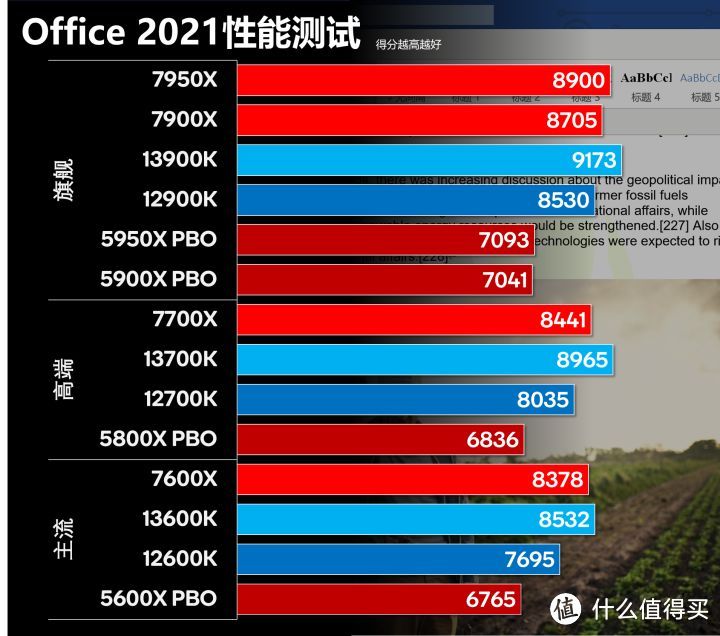
由于数据量太大。我没有列出单项数据。Zen 4在Office测试中性能超过了intel 12代。但同13代还是存在差距。在开始阶段的Word上差距较小。但后续Excel/PowerPoint/Outlook测试中性能差距被略微拉大。
Lightroom Classic & Photoshop 2022性能测试
UL Procyon 照片编辑基准测试在典型的照片编辑工作流程中使用 Adobe Lightroom Classic 和 Adobe Photoshop。其中包括批处理和图片修饰。UL Procyon 照片编辑基准测试首先将数字负片 (DNG) 图像文件导入 Adobe Lightroom Classic。然后应用各种预设。一些图片被裁剪、拉直和修改。在测试的第二部分中。将多个编辑和图层效果应用于 Adobe Photoshop 中的照片上。基准测试分数用来衡量电脑执行这些任务的速度。
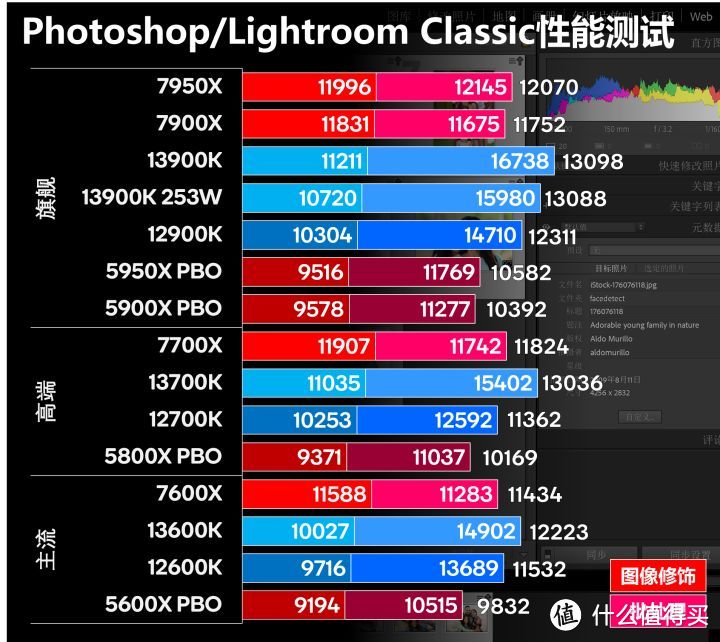
Zen 4很大程度弥补在图像修饰方面的劣势。使用轻载的频率优势实现了对intel 12/13代的反超。但在批处理部分。还是明显落后。并没有像intel处理器性能随核心数增加而有明显的同步提升。也许还是AMD处理的核心调度和Adobe的优化存在一定的问题。
游戏性能测试
我再强调一次。游戏FPS是由GPU FPS和CPU FPS的下限决定。如果想要保证GPU的性能不被限制。需要需要CPU FPS>GPU FPS;
显卡越好。GPU FPS越高。对于CPU的性能需求越高;
判断游戏CPU瓶颈的方法不是看CPU占用率占满没。而是应该反过来看GPU的占用率。如果GPU占用率不满。就说明GPU FPS低于CPU FPS。性能发挥被限制;
和你玩的游戏/画面分辨率/画质设置相关。你玩的游戏画面越好。分辨率/特效越高。GPU FPS就越低。CPU性能需求反而会降低;
但玩的都是英雄联盟/CSGO这样的游戏。显卡好一点的话。GPU是吃不满。那就是纯CPU瓶颈;
具体的FPS需求。主要取决于用户的显示器。如果最低FPS就可以高于显示器刷新率。那一般也就够用了。
我们测试的不仅包含了CSGO、英雄联盟、PUBG这样低GPU要求的电竞游戏。同样也包含古墓丽影暗影、赛博朋克2077、地平线5这样的3A。也对3A的CPU性能影响进行了分析。并且在测试画面和分辨率设置也尽量贴近一般用户的真实使用情况。
CSGO
CSGO是采用的十几年前的Source引擎。还是采用的DX9 API。其对于显卡要求不高。但对于处理器性能极其敏感。有可能有人认为200FPS和300FPS并没什么差别。反正都比显示器的刷新率高。但CSER却对FPS有种几乎偏执的追求。依然认为越高越好。我们使用控制台的timedemo命令行进行测试。测试场景为Dust 2。由于CSGO的GPU需求和负载很低。完全不构成瓶颈。1080P到4K的性能差别几乎可以忽略。我们仅仅列出4K MAX 4X MSAA的性能。
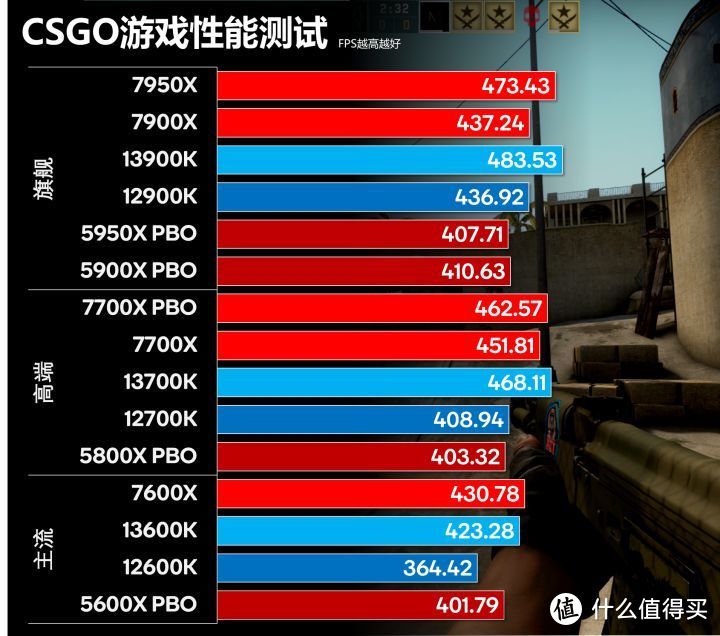
CSGO Zen 4相对Zen 3有30-50FPS的提升。基本和13代打平。很大程度是得益于频率优势。
英雄联盟
英雄联盟是个重延迟的游戏。在之前12代的测试中。英雄联盟的性能完全同L3缓存的容量成正比。大容量L3的Zen 3优势很明显。我们使用召唤师峡谷的回放在4K分辨率全特效下。使用CapFrameX记录游戏后段总攻战斗的180秒的平均FPS。

而Zen 4和13代Raptor Lake相比Zen 3找英雄联盟中的性能又再次大幅提升。特别是13900K更是接近于400FPS的水平。这很大程度是得益于缓存系统。特别是uncore频率和L2 Cache整体部分的改进。
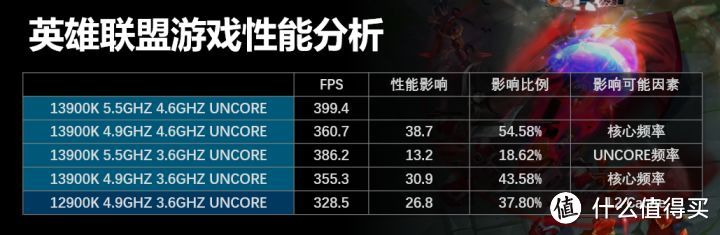
我们拿13900K做测试。分别降低13900K核心频率和uncore频率到12900K水平。性能影响核心频率占50%。uncore频率占20%。其他方面的影响可能是L2 Cache方面的影响。
(视频说明。OSD显示占用资源。实际测试无OSD;OSD核心占用实际是线程占用。7950X RTSS和AIDA64无法读取传感器温度。视频采用4K30FPS采集卡录制。只反馈OSD信息。不代表真实流畅度)
英雄联盟是完全CPU瓶颈。GPU使用率/频率和功耗都很低。如果CPU性能更好。那GPU的使用率/频率和功耗都会相对更高。能够更好的释放性能。
CSGO和英雄联盟是完全CPU瓶颈的游戏。我继续沿用之前9月使用RTX 3090 Ti的数据。但在我测试过RTX 4090后。地平线5/古墓丽影暗影这些游戏即使是4K分辨率使用RTX 4090的话。即使是12900K也出现了瓶颈。对于有 GPU瓶颈的游戏我们使用RTX 4090重新进行了测试。此外系统也更新为22H2。Zen 4平台内存频率改成6200MHz。
绝地求生
绝地求生最近更新提供了对DX12的支持。但实际DX12的性能和稳定性都不如DX11。我们依然使用DX11路径。画面我们设置成2K/4K分辨率。纹理、视野距离和抗锯齿最高。其他最低。这样的设置能够在画质和性能之间能够较好的平衡。同时画面也较为干净方便索敌。测试我们使用第一张海岛图游戏回放。降落到Y城北面的山坡。然后南下搜刮和开车。这应该是游戏负载比较高的区域。使用CapFrameX记录的180秒的平均FPS。
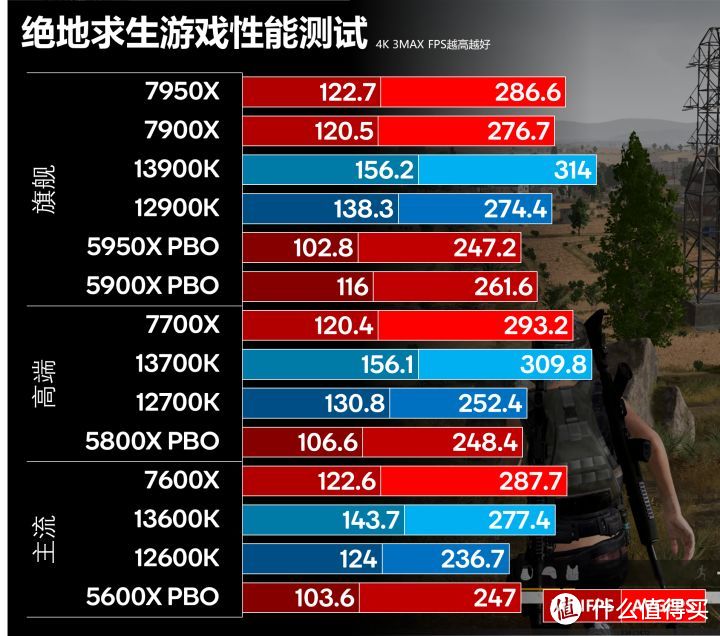
虽然Zen 4在PUBG里完胜12代。但13代13700K/13900K还是再次夺回领先优势。但13600K由于频率较低。落后7600X 10FPS。此外Zen 4的最低帧稳定性明显是要差于intel平台。基本要低30FPS。
(视频说明。OSD显示占用资源。实际测试无OSD;OSD核心占用实际是线程占用。7950X RTSS和AIDA64无法读取传感器温度。视频采用4K30FPS采集卡录制。只反馈OSD信息。不代表真实流畅度)
13900K全程稳定在5.5GHz。这个进一步验证了。那个5.8GHz的Boost频率仅仅是为了单线程跑分好看。实际游戏是绝对到不了的。这个频率在即使。
古墓丽影暗影
古墓丽影暗影我们使用的游戏预设的最高画质(不是MAX)。开启光线追踪阴影到最高。2160P DLSS性能模式的设置进行测试。古墓丽影暗影测试除了有FPS以外还有具体的CPU性能分析。
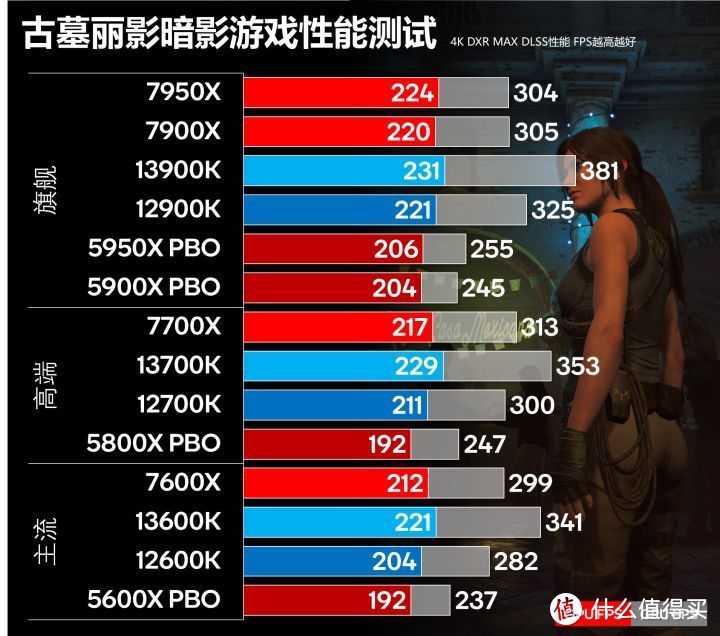
上图是古墓丽影暗影在4K分辨率下的性能数据。彩色的为GPU FPS。灰色的为CPU渲染FPS,如果灰色的CPU渲染FPS和GPU FPS比较接近。那CPU FPS就会制约GPU FPS。
即使是在4K开启光线追踪的情况。Zen 3依然落后13代30-40FPS。很明显已经出现明显瓶颈。之前有外媒用5800X测试RTX 4090是明显的不合适。Zen 4和12代性能在一个水平。基本落后13代10FPS。
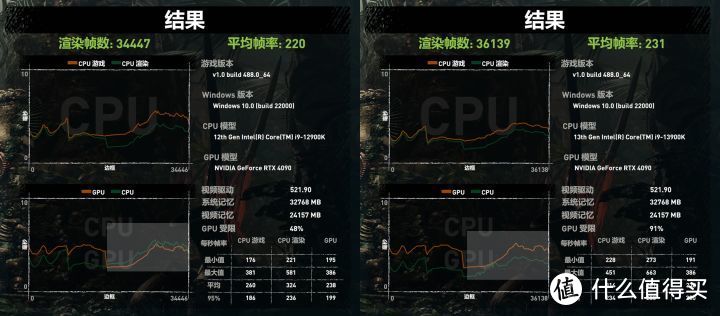
我们再来看看CPU是如何制约GPU性能的。这里具体比较12900K和13900K。古墓丽影暗影的Benchmark有三个场景。前2个场景绝大部分时间都是单帧的GPU渲染耗时>CPU耗时(FPS=1000/耗时)。是典型的GPU瓶颈。但在后半段。测试场景的复杂度明显降低,GPU的FPS提高。在12900K CPU性能不够好的情况下。CPU单帧耗时就长于GPU单帧耗时,就会拖累GPU性能。12900K和13900K的GPU受限比例为40%和91%。就说两者有60%和9%时段是CPU瓶颈。
地平线5
地平线5是我今年玩的时间最多的游戏。特别是风火轮DLC出了以后。地平线5我们使用游戏自带的Benchmark极端特效测试1080p和4K下的性能。
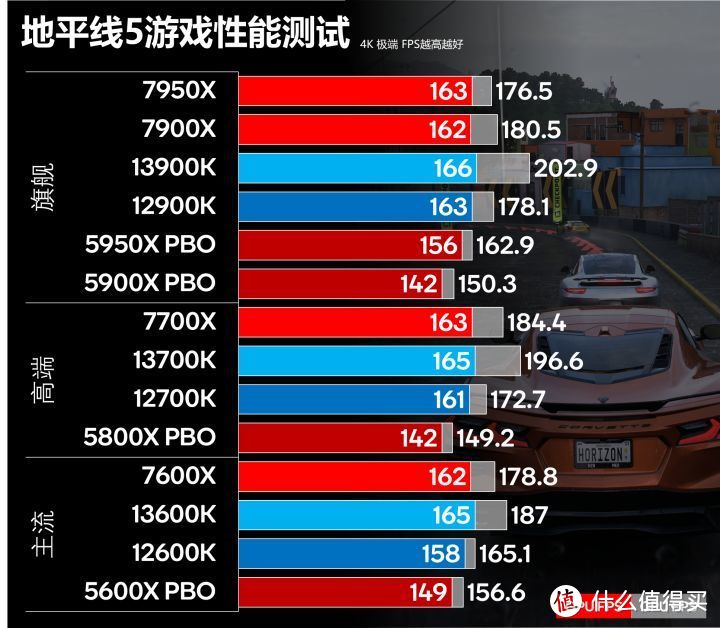
地平线5在RTX 3090 Ti的时候是完全的GPU瓶颈游戏。但RTX 4090发布以后即使是4K分辨率也有CPU瓶颈。12代/Zen 4的GPU FPS都十分逼近CPU FPS。
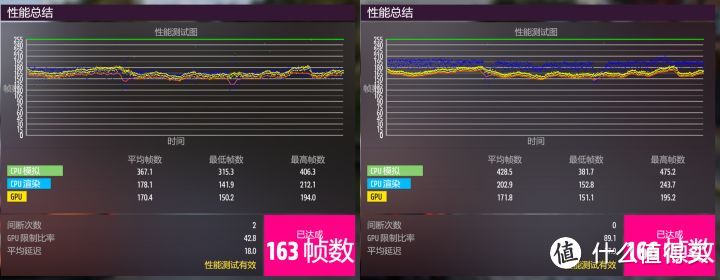
12900K(左)的CPU FPS基本和GPU FPS重叠。并且在2/3位置有小幅下跌。这就是受到蓝色FPS的影响。如果比12900K更慢的12代和Zen 3就会有更明显的制约。蓝色的CPU FPS会低于黄色的GPU FPS。并且还有2次由于CPU性能造成的间断。而13900K(右)的CPU FPS明显是高于GPU FPS的。这样RTX 4090的性能才能充分发挥。
赛博朋克2077
赛博朋克2077我们使用最近更新的1.6版本进行测试。设置光线追踪极致。DLSS性能模式。使用游戏自带的Benchmark测试1080P和4K分辨率下的性能。

赛博朋克2077基本是对多核心利用最为充分的游戏。可以将任务让每个物理核心都雨露均沾。但问题是其GPU负载更高。究竟2077是我印象中唯一用DXR做光照/阴影/反射特效的3A游戏。

赛博朋克2077在1080p分辨率性能不同处理器的性能差别及其明显。12代/Zen 4同13代就20FPS的差距。而到了4K分辨率。瓶颈就更多的转移到GPU。虽然性能排名没有变化。但差距明显收窄。intel 12/13代差别比较小。整体分别领先Zen 4和Zen 3 3-5FPS。
游戏性能测试小结
游戏测试结论部分可以分成两个部分说:
首先是CSGO。英雄联盟。PUBG这样的轻量游戏。3090Ti在4K分辨率下基本也是CPU瓶颈。
13代RPL游戏性能大幅提升有3个方面的原因:
13代3个型号P-core核心频率都有0.6GHz的提升;
当然提升的不仅是核心频率。uncore频率更是有1GHz幅度的提升。L3性能对于游戏的影响也很大。
再就是L2缓存容量和性能的改进。
对于PUBG这样的电竞游戏而言。慢CPU和快CPU大概是200FPS和300FPS的差别。这样的差别在前几年是没什么意义。而现在类似ROG PG279QM/三星奥德赛G8/外星人AW3423DW这样的新世代电竞显示器都是240Hz。200出头的FPS就不能保证minfps能够稳定在刷新率以上。接近300FPS的性能就会有更流畅的体验。
再来说3A。在30世代的情况。瓶颈基本在GPU。但在RTX 4090发布以后。地平线5/古墓这样的基本全特效。原有的Zen 3/12代就不能满足需求。CPU会拖GPU的后腿。不过和竞技游戏一样。CPU性能需求取决于你的显示器刷新率。最低帧高于显示器刷新率那就问题不大。
但这仅仅是RTX 4090的情况。并不是每个人需要4090。如果显卡FPS比较低。CPU的性能需求也会降低。再者你玩的游戏/画面分辨率/画质设置/显示器刷新率也都会影响FPS。一般而言。对于3A游戏显卡只要不是RTX 4090,甚至是3080/3090级别。CPU的性能需求就可以降低很多。基本Zen 3就差不多。12代就绰绰有余。
测试总结
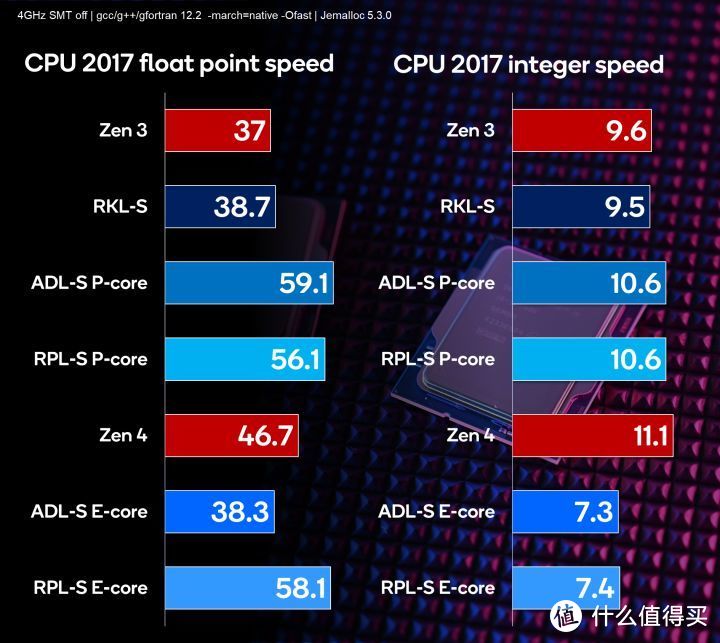
依据前面的定频4GHz的SPEC CPU 2017测试。同频的12代和13代P-core整数效能基本一样。浮点甚至还有略微下降(和流水线变长有关)。但实际13代频率大幅提升。可以很容易的覆盖掉这点的效能下降。
Zen 4浮点相比Zen 3大幅提升了26%。但依然同12/13代有明显差距。整数部分。Zen 3相对12代/13代落后10%。而这次Zen 4提升15.6%。又再次反超intel。

其实日常软件使用或者游戏基本都是整数。浮点主要是用在渲染/视频处理这样的生产力上。所以对于大多数用户浮点性能是没整数性能那样重要。
生产力测试部分。intel RPL凭借再次增加E-core的数量。在渲染/视频编码这样的多线程密集应用有十分明显的优势。这样的胜利是E-core的胜利。我之前在12代测试的时候就说过,E-core才是12代的本体。其能够以十分低成本方式提升多线程(跑分)性能。要知道4个E-core的核心面积才比一个P-core大一点。现在可以形成2个E-core打一个Zen 4的局面。这个就是架构策略的胜利。
E-core好还是不好?
但现在很多人是抵制E-core的:他们观点是OUTEL的小核是跑分的。还有说什么如果大小核这么好。为啥服务器不用。
我在12代评测的时候就说过。intel的P-core/E-core调度策略十分粗暴:前台任务首先用P-core。用完了就用E-core。再用完了就用P-core的超线程。后台任务优先用E-core。这样策略很简单且有效。我用了一年多也没发现有什么问题。
再者虽然Zen 3/Zen 4都是大核。但对于Ryzen 9这种双CCD型号。CCD1和CCD2的调用策略其实也和P-core/E-core差不多。在游戏的时候,Ryzen 9会优先使用高频的CCD1。后台程序用CCD2。并且在我测试过程中。反而还发现了Zen 4有更为明显的调度问题。特别是首版AGESA。在赛博朋克2077、地铁离去性能问题都很明显。双CCD型号性能明显不如单CCD的型号。intel P-core/E-core任务切换更快。究竟是在一个RING上。而Zen 3/Zen 4。通过IO Die跨CCD。还需要L3缓存一致性。这样的代价就高得多。
购买建议
13代并不像Zen 4那样架构有比较大的变化。工艺线宽也没有大的升级。仅仅是优化工艺拉升频率。再加塞E-core就获得了性能上的明显优势。因此对于新购机用户。或者说是老机器升级用户。13代毫无疑问是最佳的选择。游戏性能完胜Zen 4。生产力方面在大多领域也有优势。
购买建议:13600K/13600KF
13600K核心数量比较少。并不太合适生产力(虽然也领先7600X)。但凭借高频和架构优化。游戏性能已经超越12900K。京东预售的13600K/KF的价格是2699/2499。价格从比例上相比12600K还是贵不少。但考虑到更高的频率。更多的E-core。相比上代12900K更好的游戏性能。还是很合适整体预算不太高的用户。特别是那些想在处理器主板上少花钱。留更多预算给显卡的用户。
既然是要省钱。 我觉得华硕Z690-P/Z690M Plus这样的入门定位的Z690就可以。这些主板价格也比B650便宜。相比7600X平台优势明显。更不用说还有更便宜的B660。13600K 160-170W的功耗用TUF B660M PLUS这样规格的主板就可以应对。虽然B660不能超频。但全核心5.1GHz也很强了。
对于游戏用户。DDR4相比DDR5并不弱。因此我们也推荐3600-4000频率的DDR4搭配。这样相比7600X+B650+DDR5的平台整体持有成本就更低。13600K整体价格优势相比7600X十分明显。不过我觉得首发的价格应该还是有不少水分。并且这个水分比13700K/13900K更大。估计双11时候不会比12600K贵太多。热方面13600K依据体质不同。满载功耗大概在150-170W。使用一般便宜的240/360或者6热管单塔/便宜双塔就可以压得服服帖帖。散热方面也不用太担心。
购买建议:13700K/13700KF
13700K和12900K一样。都是8P+8E。P-core频率从5.1提升到5.3GHz。但功耗依然还是维持12900K水平。因此13700K其实不应该于12700K相比。而像是一颗完美版的12900K。京东预售的13700K/KF的价格是3499/3299。虽然价格相比12700K上涨不少。但作为完美版的12900K。这个价格还是可以接受。
主板方面。虽然240W的功耗Z690-P这样的级别就可以应对。但从心理上来说,上到TUF或者STRIX-A这个级别更合理。D4和D5版都可以。
散热方面。240W级别的13700K一般还是建议性能级别的360水冷。如果雅浚GA5或者VK的GL360。都可以压倒8x度。高性能双塔风冷默认设置压住还是有点难。但降低点电压也可以控制在90多度。不至于触发100度TJmax降频。我自己这样的风冷党。就应该会选择13700K。
购买建议:13900K/13900KF
京东预售的13600K/KF的价格是4899/4699。相比12900K的价格要贵几百。在游戏方面相对13700K性能优势并不大。生产力方面虽然强大。但功耗更强大。默认3XX W的功耗。常规的散热手段是基本不可能压住的。
但13900K也不是没有办法用。可以依据自己处理器的体质和散热器性能。在BIOS设置降压或者限制Power Limit/温度墙。在设置后对于日常使用和游戏是没性能影响的。有影响是渲染或者是视频处理这样的生产力领域。不过性能影响程度也很小。这和调低7950X的温度墙差不多。
因此13900K我们依然还是推荐给不差钱什么都追求最强的玩家和有一定生产力需要的个人用户。
内存方面。对于预算有限的用户还是推荐海力士Mdie。配合Z790一般都可以上6800。即使是Z790 HERO这样的四槽主板现在QVL 2根的情况下也可以到7400。就说Adie也能够得以发挥。不一定需要APEX才能跑出来。
另外CPU购买还是有些细节问题可以提下:
上面的价格是京东自营预售。实际淘宝拼多多的价格更低。还有平台补贴。并且双11就差10多天了;
K和KF差价200。买那个比较好的问题:虽然买K的用户基本不太可能没独显。但我一般还是建议买K。在独显卖掉或者返修的时候方便紧急。并且以后卖二手的时候。K和KF差价也往往大于200;
对于新购机的用户而言。一般还是建议买处理器+主板的套餐。价格一般会比单独买更低;
对于12600K/12700K/12900K+Z690用户。其实13代也是值得升级的。其性能提升还是很明显。并且CPU的二手残值比较高。卖掉也亏不了多少。不怕折腾的玩家我觉得还是值得折腾下。
如果你想上Adie。内存跑到7400甚至跟高。还是需要高规格的Z790。就如我们本次测试的Z790 HERO。之前Z690除了APEX这样的极限超频型号是不能把Adie频率跑起来。

我做了一个统计表。是京东自营X670当前价格/Z790预售价/Z690 618最低价格进行比较。Z790还是稍微贵一点。但作为新品预售也可以理解。并且我对比的是618最低价。这样对比其实有点欺负Z790。相信双11的时候两者之间的差价应该不会大大。20号发布距离双11开门红就差10天。我觉得届时入手应该更合适。特别是对于已经购入或者准备购入40系显卡的玩家。今年双11毫无疑问是最近几年最合适装机升级的时机。
入门款的Z790-P目前京东自营没有上自营。但渠道差价不到200。Z790提升主要在D5高频。D4型号玩家如果预算紧张或者现有比较好的D4的话。继续选择Z690也不是不行。

阿妮亚都喜欢这个。你也不来套?
作者声明本文无利益相关。欢迎值友理性交流。和谐讨论~
其他人还看了
华硕推出新一代ROGRyuoIII240/360ARGB“龙王”水冷散热器1799元起
降温降功耗,性能还涨了?手把手教你简单优化Ryzen锐龙7000CPU!
郑重声明:本文“13代VSZen4VS12代VSZen3最全对比测试看完就知道该买那个了”,https://nmgjrty.com/diannaopj_644333.html内容,由cloudliu提供发布,请自行判断内容优劣。

- 全部评论(0)

-
 千元级小钢炮,畅爽游戏兼顾生产力,华硕VG249Q1A
千元级小钢炮,畅爽游戏兼顾生产力,华硕VG249Q1A -
 男朋友说用这个显示器打游戏好爽!
男朋友说用这个显示器打游戏好爽! -
 小米显示器,性价比还是挺高的
小米显示器,性价比还是挺高的 -
 自媒体最佳拍档,这块飞利浦高清显示器我不信你不心动!
自媒体最佳拍档,这块飞利浦高清显示器我不信你不心动! -
 告别平庸的硬盘底座!OIRCO这款“集装箱”,速度快玩法超多
告别平庸的硬盘底座!OIRCO这款“集装箱”,速度快玩法超多 -
 W4K显示器
W4K显示器 -
 朗科(Netac)NV70001TPCIe40SSD固态硬盘测试
朗科(Netac)NV70001TPCIe40SSD固态硬盘测试 -
 Linus考虑让Linux内核放弃支持英特尔80486处理器
Linus考虑让Linux内核放弃支持英特尔80486处理器 -
 13代i7暴打12代i9!憋屈太久了,牙膏厂疯起来真的挺吓人
13代i7暴打12代i9!憋屈太久了,牙膏厂疯起来真的挺吓人 -
 超高性价比的选择,锐可余音“夏至”三件套之CX5电竞声卡体验
超高性价比的选择,锐可余音“夏至”三件套之CX5电竞声卡体验 -
 225元的105寸一线通便携屏SurfaceGO2同款屏幕
225元的105寸一线通便携屏SurfaceGO2同款屏幕 -
 矿难确定不当回开扎古的真男人么
矿难确定不当回开扎古的真男人么 -
 闲置固态硬盘的完美解决方案!奥睿科USB40固态硬盘盒实测分享
闲置固态硬盘的完美解决方案!奥睿科USB40固态硬盘盒实测分享 -
 华硕推出新一代ROGRyuoIII240/360ARGB“龙王”水冷散热器1799元起
华硕推出新一代ROGRyuoIII240/360ARGB“龙王”水冷散热器1799元起 -
 2022年了,我才开始用先马趣造
2022年了,我才开始用先马趣造 -
 DIY台式电脑之选购机箱篇
DIY台式电脑之选购机箱篇
最新更新
- 千元级小钢炮,畅爽游戏兼顾生产力,华
- 男朋友说用这个显示器打游戏好爽!
- 小米显示器,性价比还是挺高的
- 自媒体最佳拍档,这块飞利浦高清显示器
- 告别平庸的硬盘底座!OIRCO这款“集装箱
- W4K显示器
- 朗科(Netac)NV70001TPCIe40SSD固态硬盘测试
- Linus考虑让Linux内核放弃支持英特尔80486处
- 13代i7暴打12代i9!憋屈太久了,牙膏厂疯
- 超高性价比的选择,锐可余音“夏至”三
- 225元的105寸一线通便携屏SurfaceGO2同款屏幕
- 矿难确定不当回开扎古的真男人么
- 闲置固态硬盘的完美解决方案!奥睿科
- 华硕推出新一代ROGRyuoIII240/360ARGB“龙王”
- 2022年了,我才开始用先马趣造
推荐阅读
猜你喜欢
- [机箱]ITX装机初体验
- [机箱]机箱界的铝厂,支持240水冷与长显卡的乔思伯V8ITX机箱装机点评
- [机箱]安钛克驱逐者DF600FLUX
- [机箱]Thermaltake发布Divider300TG机箱
- [机箱]Zen3架构基础款单核锤爆10900K?AMD锐龙55600X评测
- [机箱]也许是最小MATX主机的完美走线
- [机箱]30系列已到,机电有升级的必要吗?
- [机箱]女王的ITX新电脑上篇之复刻lousuITX机箱
- [机箱]最小ATX乔思伯RM2及风道改造
- [机箱]bequiet!德商必酷发布PureBase500DX机箱
- [机箱]修理机箱耳机插孔
- [机箱]大容积的小钢炮
- [机箱]乔思伯A4水冷机箱+R53600RX5700升级装机
- [机箱]TtLevel20GT全塔机箱开封解析
- [机箱]Dell戴尔小机箱内部升级记